统计代写|R语言代写R language代考|NTRES6100
如果你也在 怎样代写R语言这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
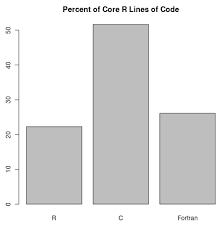
R是一种用于统计计算和图形的编程语言,由R核心团队和R统计计算基金会支持。R由统计学家Ross Ihaka和Robert Gentleman创建,在数据挖掘者和统计学家中被用于数据分析和开发统计软件。用户已经创建了软件包来增强R语言的功能。
根据用户调查和对学术文献数据库的研究,R是数据挖掘中最常用的编程语言之一。[6] 截至2022年3月,R在衡量编程语言普及程度的TIOBE指数中排名第11位。
官方的R软件环境是GNU软件包中的一个开源自由软件环境,在GNU通用公共许可证下提供。它主要是用C、Fortran和R本身(部分自我托管)编写的。预编译的可执行文件提供给各种操作系统。R有一个命令行界面。[8] 也有多个第三方图形用户界面,如RStudio,一个集成开发环境,和Jupyter,一个笔记本界面。
statistics-lab™ 为您的留学生涯保驾护航 在代写R语言方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写R语言代写方面经验极为丰富,各种代写R语言相关的作业也就用不着说。
我们提供的R语言及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|R语言代写R language代考|Using R interactively
A physical terminal (keyboard plus text-only screen) decades ago was how users communicated with computers, and was frequently called a console. Nowadays, a text-only interface to a computer, in most cases a window or a pane within a graphical user interface, is still called a console. In our case, the R console (Figure 1.1). This is the native user interface of $R$.
Typing commands at the $\mathrm{R}$ console is useful when one is playing around, rather aimlessly exploring things, or trying to understand how an $\mathrm{R}$ function or operator we are not familiar with works. Once we want to keep track of what we are doing, there are better ways of using $\mathrm{R}$, which allow us to keep a record of how an analysis has been carried out. The different ways of using $R$ are not exclusive of each other, so most users will use the $\mathrm{R}$ console to test individual commands and plot data during the first stages of exploration. As soon as we decide how we want to plot or analyze the data, it is best to start using scripts. This is not enforced in any way by $\mathrm{R}$, but scripts are what really brings to light the most important advantages of using a programming language for data analysis. In Figure $1.1$ we can see how the R console looks. The text in red has been typed in by the user, except for the prompt $>$, and the text in blue is what $R$ has displayed in response. It is essentially a dialogue between user and R. The console can look different when displayed within an IDE like RStudio, but the only difference is in the appearance of the text rather than in the text itself (cf. Figures $1.1$ and 1.2).
The two previous figures showed the result of entering a single command. Figure $1.3$ shows how the console looks after the user has entered several commands, each as a separate line of text.
The examples in this book require only the console window for user input. Menu-driven programs are not necessarily bad, they are just unsuitable when there is a need to set very many options and choose from many different actions. They are also difficult to maintain when extensibility is desired, and when independently developed modules of very different characteristics need to be integrated. Textual languages also have the advantage, to be addressed in later chapters, that command sequences can be stored in human- and computer-readable text files. Such files constitute a record of all the steps used, and in most cases, makes it trivial to reproduce the same steps at a later time. Scripts are a very simple and handy way of communicating to other users how to do a given data analysis.
统计代写|R语言代写R language代考|Using R in a “batch job”
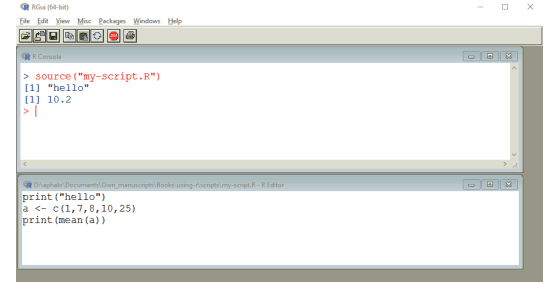
To run a script we need first to prepare a script in a text editor. Figure $1.4$ shows the console immediately after running the script file shown in the text editor. As before, red text, the command source(“my-script. R”), was typed by the user, and the blue text in the console is what was displayed by $R$ as a result of this action. The title bar of the console, shows “R-console,” while the title bar of the editor shows the path to the script file that is open and ready to be edited followed by “R-editor.”A true “batch job” is not run at the R console but at the operating system command prompt, or shell. The shell is the console of the operating system-Linux, Unix, OS X, or MS-Windows. Figure $1.5$ shows how running a script at the Windows command prompt looks. A script can be run at the operating system prompt to do time-consuming calculations with the output saved to a file. One may use this approach on a server, say, to leave a large data analysis job running overnight or even for several days.
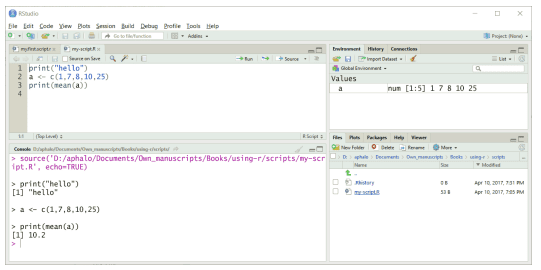
Integrated Development Environments (IDEs) are used when developing computer programs. IDEs provide a centralized user interface from within which the different tools used to create and test a computer program can be accessed and used in coordination. Most IDEs include a dedicated editor capable of syntax highlighting, and even report some mistakes, related to the programming language in use. One could describe such an editor as the equivalent of a word processor with spelling and grammar checking, that can alert about spelling and syntax errors for a computer language like $\mathrm{R}$ instead of for a natural language like English. In the case of RStudio, the main, but not only language supported is R. The main window of IDEs usually displays more than one pane simultaneously. From within the RStudio IDE, one has access to the R console, a text editor, a file-system browser, a pane for graphical output, and access to several additional tools such as for installing and updating extension packages. Although RStudio supports very well the development of large scripts and packages, it is currently, in my opinion, also the best possible way of using $R$ at the console as it has the $R$ help system very well integrated both in the editor and R console. Figure $1.6$ shows the main window displayed by RStudio after running the same script as shown above at the R console (Figure 1.4) and at the operating system command prompt (Figure 1.5). We can see by comparing these three figures how RStudio is really a layer between the user and an unmodified $R$ executable. The script was sourced by pressing the “Source” button at the top of the editor pane. RStudio, in response to this, generated the code needed to source the file and “entered” it at the console, the same console, where we would type any $\mathrm{R}$ commands.
R语言代写
统计代写|R语言代写R language代考|Using R interactively
几十年前,物理终端(键盘加上纯文本屏幕)是用户与计算机通信的方式,通常被称为控制台。如今,计算机的纯文本界面,在大多数情况下是图形用户界面中的窗口或窗格,仍称为控制台。在我们的例子中,R 控制台(图 1.1)。这是本机用户界面R.
在输入命令R当一个人在玩耍时,控制台很有用,而不是漫无目的地探索事物,或者试图理解一个R我们不熟悉的函数或运算符的作品。一旦我们想要跟踪我们正在做的事情,就有更好的使用方法R,这使我们能够记录分析是如何进行的。不同的使用方式R互不排斥,所以大多数用户会使用R控制台在探索的第一阶段测试单个命令和绘制数据。一旦我们决定如何绘制或分析数据,最好开始使用脚本。这不是以任何方式强制执行的R,但是脚本真正揭示了使用编程语言进行数据分析的最重要优势。如图1.1我们可以看到 R 控制台的外观。红色文字已被用户输入,提示除外>,蓝色的文字是什么R已显示为响应。它本质上是用户和 R 之间的对话。在 RStudio 等 IDE 中显示时,控制台看起来会有所不同,但唯一的区别在于文本的外观而不是文本本身(参见图1.1和 1.2)。
前两个图显示了输入单个命令的结果。数字1.3显示用户输入多个命令后控制台的外观,每个命令都作为单独的文本行。
本书中的示例只需要用户输入的控制台窗口。菜单驱动的程序不一定是坏的,它们只是在需要设置很多选项并从许多不同的操作中进行选择时不合适。当需要可扩展性时,它们也难以维护,并且当需要集成独立开发的具有非常不同特性的模块时。文本语言还有一个优势,将在后面的章节中讨论,即命令序列可以存储在人类和计算机可读的文本文件中。这些文件构成了所有使用的步骤的记录,并且在大多数情况下,使得以后重现相同的步骤变得微不足道。脚本是与其他用户交流如何进行给定数据分析的一种非常简单方便的方式。
统计代写|R语言代写R language代考|Using R in a “batch job”
要运行脚本,我们首先需要在文本编辑器中准备一个脚本。数字1.4运行文本编辑器中显示的脚本文件后立即显示控制台。和以前一样,红色文本,命令源(“my-script.R”)是用户输入的,控制台中的蓝色文本是显示的R作为这一行动的结果。控制台的标题栏显示“R-console”,而编辑器的标题栏显示打开并准备好编辑的脚本文件的路径,然后是“R-editor”。真正的“批处理作业”不是在 R 控制台上运行,而是在操作系统命令提示符或 shell 上运行。shell 是操作系统(Linux、Unix、OS X 或 MS-Windows)的控制台。数字1.5显示在 Windows 命令提示符下运行脚本的外观。可以在操作系统提示符下运行脚本来执行耗时的计算,并将输出保存到文件中。可以在服务器上使用这种方法,例如,让大型数据分析作业运行一夜甚至几天。
开发计算机程序时使用集成开发环境 (IDE)。IDE 提供了一个集中的用户界面,从中可以访问和协调使用用于创建和测试计算机程序的不同工具。大多数 IDE 都包含一个能够突出显示语法的专用编辑器,甚至报告一些与所使用的编程语言相关的错误。人们可以将这样的编辑器描述为具有拼写和语法检查功能的文字处理器,它可以警告计算机语言的拼写和语法错误,例如R而不是像英语这样的自然语言。对于 RStudio,主要但不仅支持的语言是 R。IDE 的主窗口通常同时显示多个窗格。从 RStudio IDE 中,您可以访问 R 控制台、文本编辑器、文件系统浏览器、图形输出窗格,以及访问其他一些工具,例如安装和更新扩展包。尽管 RStudio 很好地支持大型脚本和包的开发,但在我看来,它目前也是最好的使用方式R在控制台上,因为它有R帮助系统很好地集成在编辑器和 R 控制台中。数字1.6显示了 RStudio 在 R 控制台(图 1.4)和操作系统命令提示符(图 1.5)上运行与上述相同的脚本后显示的主窗口。通过对比这三个图,我们可以看出 RStudio 是如何真正介于用户和未修改的R可执行。该脚本是通过按编辑器窗格顶部的“源”按钮获取的。RStudio 对此作出响应,生成了获取文件所需的代码并在控制台“输入”它,在同一个控制台,我们可以在其中键入任何R命令。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
随机过程代考
在概率论概念中,随机过程是随机变量的集合。 若一随机系统的样本点是随机函数,则称此函数为样本函数,这一随机系统全部样本函数的集合是一个随机过程。 实际应用中,样本函数的一般定义在时间域或者空间域。 随机过程的实例如股票和汇率的波动、语音信号、视频信号、体温的变化,随机运动如布朗运动、随机徘徊等等。
贝叶斯方法代考
贝叶斯统计概念及数据分析表示使用概率陈述回答有关未知参数的研究问题以及统计范式。后验分布包括关于参数的先验分布,和基于观测数据提供关于参数的信息似然模型。根据选择的先验分布和似然模型,后验分布可以解析或近似,例如,马尔科夫链蒙特卡罗 (MCMC) 方法之一。贝叶斯统计概念及数据分析使用后验分布来形成模型参数的各种摘要,包括点估计,如后验平均值、中位数、百分位数和称为可信区间的区间估计。此外,所有关于模型参数的统计检验都可以表示为基于估计后验分布的概率报表。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
statistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
机器学习代写
随着AI的大潮到来,Machine Learning逐渐成为一个新的学习热点。同时与传统CS相比,Machine Learning在其他领域也有着广泛的应用,因此这门学科成为不仅折磨CS专业同学的“小恶魔”,也是折磨生物、化学、统计等其他学科留学生的“大魔王”。学习Machine learning的一大绊脚石在于使用语言众多,跨学科范围广,所以学习起来尤其困难。但是不管你在学习Machine Learning时遇到任何难题,StudyGate专业导师团队都能为你轻松解决。
多元统计分析代考
基础数据: $N$ 个样本, $P$ 个变量数的单样本,组成的横列的数据表
变量定性: 分类和顺序;变量定量:数值
数学公式的角度分为: 因变量与自变量
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。