机器学习代写|强化学习project代写reinforence learning代考|Actor-Critic Hypothesis
如果你也在 怎样代写强化学习reinforence learning这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
强化学习是一种基于奖励期望行为和/或惩罚不期望行为的机器学习训练方法。一般来说,强化学习代理能够感知和解释其环境,采取行动并通过试验和错误学习。
statistics-lab™ 为您的留学生涯保驾护航 在代写强化学习reinforence learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写强化学习reinforence learning代写方面经验极为丰富,各种代写强化学习reinforence learning相关的作业也就用不着说。
我们提供的强化学习reinforence learning及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础

机器学习代写|强化学习project代写reinforence learning代考|Actor-Critic Hypothesis
Houk, Adams and Barto attempted to solve the credit assignment problem in animals by linking activity of dopamine neurons in the basal ganglia to an actor-critic model [8]. There is evidence that links an actor to habitual behavior (stimulus response or S-R associations) of mammals with action selection mechanisms in the dorsolateral striatum located in the basal ganglia [14].
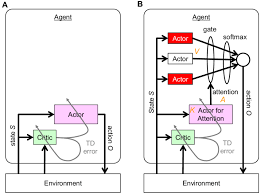
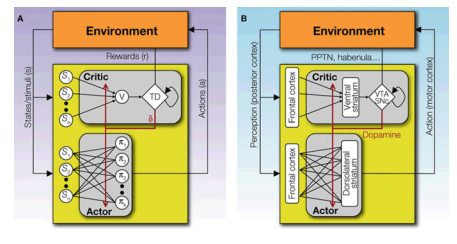
In his review on reinforcement learning and the neural basis of conditioning, Tiago V. Maia states that in order for an area to be taken seriously as the critic, it needs to fulfill three requirements. The area should show neuronal activity during the expectation of reward. The area should also show activation during an unexpected reward or a reward-predicting stimulus but not in the period between predictor and the reward itself. The third requirement is that the area should project to and from neurons in the dopamine system because they represent prediction errors as discussed in the section above [12]. The ventral striatum fulfills all three criteria. It has been shown that the expectation of external events with behavioral significance is related to activity in the ventral striatum [19]. This area also sends dopaminergic projections to and receives from all regions in the striatum including what is hypothesized to be the actor [10]. The orbitofrontal cortex and the amygdala are two other structures in the brain that also fulfill these criteria [17]. The two areas are both anatomically and functionally closely related to the ventral striatum [1]. Fig. I shows a diagram that depicts how the structure of a neural actor-critic might look like. The actor in the dorsolateral striatum receives its input from the posterior regions (somatosensory and visual cortices) and sends action decisions back to the environment through signals to the motor cortex. The critic in the ventral striatum computes the prediction error and returns it to the actor through dopamine projections to the dorsal striatum.
机器学习代写|强化学习project代写reinforence learning代考|Multiple Critics Hypothesis
As was mentioned in the previous subsection, the amygdala and the orbitofrontal cortex are also correlated with learning and have dopamine receptors/projections from and to the dorsal striatum. The former shows activation patterns during emotional learning [13] and the latter during associative learning [6]. This raises the question of whether there can be multiple critics with different criteria interacting with each other. The main function of each structure could represent a unique criterion that perhaps projects its value to the other areas. If this hypothesis is valid, then we might see excitatory or inhibitory dopamine receptors being activated by presynaptic neurons in the amygdala during learning while different emotions that trigger activation in the amgydala are induced. Furthermore, it would be interesting to investigate the role of different dopamine transmitter sub-types and receptors that might play different learning roles in these structures.
机器学习代写|强化学习project代写reinforence learning代考|Limitations
The main difficulty with neuroscience research is our limited understanding of how biochemical reactions in the brain can represent and process information. Studies on humans are conducted mostly with fMRI and EEG (electroencephalography). fMRI achieves relatively high spatial resolution with one voxel representing a few million neurons and tens of billions of synapses [9]. However, fMRI has low temporal resolution producing images after 1 second of the event. This is not desirable when we consider that prediction errors are time-based. EEG measures electrophysiological activity by placing non-invasive electrodes on the scull. The electrodes achieve a high temporal resolution in the range of milliseconds but with a very low spatial resolution. This is due to volume conduction and other distortions which can even affect the validity of the temporal resolution [3].
Transferring concepts of reinforcement learning between psychology, neuroscience and computer science has resulted in mutual progress. The early development of classical conditioning in behavioral psychology eventually resulted in TD learning and an actor-critic paradigm is now being hypothesized to function in the brain. We believe that despite current limitations in measurement technologies, future research which integrates integrates reinforcement learning in psychology, neuroscience, and computer science can bring novel theories to the three fields.

强化学习代写
机器学习代写|强化学习project代写reinforence learning代考|Actor-Critic Hypothesis
Houk、Adams 和 Barto 试图通过将基底神经节中多巴胺神经元的活动与演员-评论模型联系起来来解决动物的信用分配问题 [8]。有证据表明,行为者与哺乳动物的习惯行为(刺激反应或 SR 关联)与位于基底神经节的背外侧纹状体中的行为选择机制有关 [14]。
在他对强化学习和条件反射的神经基础的评论中,Tiago V. Maia 指出,为了让一个领域被认真对待,它需要满足三个要求。该区域应在期望奖励期间显示神经元活动。该区域还应该在意外奖励或奖励预测刺激期间显示激活,但不是在预测变量和奖励本身之间的时期内。第三个要求是该区域应该投射到多巴胺系统中的神经元和从多巴胺系统中的神经元投射,因为它们代表了上面部分中讨论的预测误差[12]。腹侧纹状体满足所有三个标准。已经表明,对具有行为意义的外部事件的预期与腹侧纹状体的活动有关 [19]。该区域还向纹状体的所有区域发送和接收多巴胺能投射,包括被假设为演员的区域 [10]。眶额皮质和杏仁核是大脑中另外两个也符合这些标准的结构 [17]。这两个区域在解剖学和功能上都与腹侧纹状体密切相关 [1]。图 I 显示了一个图表,描述了神经演员-评论家的结构可能是什么样子。背外侧纹状体中的参与者接收来自后部区域(躯体感觉和视觉皮层)的输入,并通过运动皮层的信号将动作决策发送回环境。腹侧纹状体中的批评者计算预测误差并通过多巴胺对背侧纹状体的投射将其返回给演员。
机器学习代写|强化学习project代写reinforence learning代考|Multiple Critics Hypothesis
如前一小节所述,杏仁核和眶额叶皮层也与学习相关,并且具有来自和到背侧纹状体的多巴胺受体/投射。前者显示情绪学习期间的激活模式[13],后者显示关联学习期间的激活模式[6]。这就提出了一个问题,即是否可以有多个具有不同标准的评论家相互影响。每个结构的主要功能可以代表一个独特的标准,可能会将其价值投射到其他领域。如果这个假设是有效的,那么我们可能会看到兴奋性或抑制性多巴胺受体在学习过程中被杏仁核中的突触前神经元激活,而引发杏仁核激活的不同情绪被诱导。此外,
机器学习代写|强化学习project代写reinforence learning代考|Limitations
神经科学研究的主要困难是我们对大脑中的生化反应如何代表和处理信息的理解有限。对人类的研究主要使用 fMRI 和 EEG(脑电图)进行。fMRI 实现了相对较高的空间分辨率,一个体素代表数百万个神经元和数百亿个突触 [9]。然而,fMRI 在事件发生 1 秒后生成图像的时间分辨率较低。当我们认为预测误差是基于时间的时,这是不可取的。EEG 通过在双桨上放置非侵入性电极来测量电生理活动。电极实现了毫秒范围内的高时间分辨率,但空间分辨率非常低。
在心理学、神经科学和计算机科学之间转移强化学习的概念已经导致相互进步。行为心理学中经典条件反射的早期发展最终导致了 TD 学习,现在假设演员-批评范式在大脑中发挥作用。我们相信,尽管目前测量技术存在局限性,但未来将强化学习与心理学、神经科学和计算机科学相结合的研究可以为这三个领域带来新的理论。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。