如果你也在 怎样代写决策树decision tree这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
决策树是一种决策支持工具,它使用决策及其可能后果的树状模型,包括偶然事件结果、资源成本和效用。它是显示一个只包含条件控制语句的算法的一种方式。
statistics-lab™ 为您的留学生涯保驾护航 在代写决策树decision tree方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写决策树decision tree代写方面经验极为丰富,各种代写决策树decision tree相关的作业也就用不着说。
我们提供的决策树decision tree及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
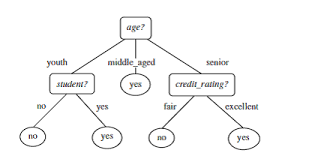
机器学习代写|决策树作业代写decision tree代考|Introduction
Classification, which is the data mining task of assigning objects to predefined categories, is widely used in the process of intelligent decision making. Many classification techniques have been proposed by researchers in machine learning, statistics, and pattern recognition. Such techniques can be roughly divided according to the their level of comprehensibility. For instance, techniques that produce interpretable classification models are known as white-box approaches, whereas those that do not are known as black-box approaches. There are several advantages in employing white-box techniques for classification, such as increasing the user confidence in the prediction, providing new insight about the classification problem, and allowing the detection of errors either in the model or in the data [12]. Examples of white-box classification techniques are classification rules and decision trees. The latter is the main focus of this book.
A decision tree is a classifier represented by a flowchart-like tree structure that has been widely used to represent classification models, specially due to its comprehensible nature that resembles the human reasoning. In a recent poll from the kdnuggets website [13], decision trees figured as the most used data mining/analytic method by researchers and practitioners, reaffirming its importance in machine learning tasks. Decision-tree induction algorithms present several advantages over other learning algorithms, such as robustness to noise, low computational cost for generating the model, and ability to deal with redundant attributes [22].
Several attempts on optimising decision-tree algorithms have been made by researchers within the last decades, even though the most successful algorithms date back to the mid-80s [4] and early $90 \mathrm{~s}[21]$. Many strategies were employed for deriving accurate decision trees, such as bottom-up induction $[1,17]$, linear programming [3], hybrid induction [15], and ensemble of trees [5], just to name a few. Nevertheless, no strategy has been more successful in generating accurate and comprehensible decision trees with low computational effort than the greedy top-down induction strategy.
A greedy top-down decision-tree induction algorithm recursively analyses if a sample of data should be partitioned into subsets according to a given rule, or if no further partitioning is needed. This analysis takes into account a stopping criterion, for
deciding when tree growth should halt, and a splitting criterion, which is responsible for choosing the “best” rule for partitioning a subset. Further improvements over this basic strategy include pruning tree nodes for enhancing the tree’s capability of dealing with noisy data, and strategies for dealing with missing values, imbalanced classes, oblique splits, among others.
A very large number of approaches were proposed in the literature for each one of these design components of decision-tree induction algorithms. For instance, new measures for node-splitting tailored to a vast number of application domains were proposed, as well as many different strategies for selecting multiple attributes for composing the node rule (multivariate split). There are even studies in the literature that survey the numerous approaches for pruning a decision tree $[6,9]$. It is clear that by improving these design components, more effective decision-tree induction algorithms can be obtained.
机器学习代写|决策树作业代写decision tree代考|Book Outline
This book is structured in 7 chapters, as follows.
Chapter 2 [Decision-Tree Induction]. This chapter presents the origins, basic concepts, detailed components of top-down induction, and also other decision-tree induction strategies.
Chapter 3 [Evolutionary Algorithms and Hyper-Heuristics]. This chapter covers the origins, basic concepts, and techniques for both Evolutionary Algorithms and Hyper-Heuristics.
Chapter 4 [HEAD-DT: Automatic Design of Decision-Tree Induction Algorithms]. This chapter introduces and discusses the hyper-heuristic evolutionary algorithm that is capable of automatically designing decision-tree algorithms. Details such as the evolutionary scheme, building blocks, fitness evaluation, selection, genetic operators, and search space are covered in depth.
Chapter 5 [HEAD-DT: Experimental Analysis]. This chapter presents a thorough empirical analysis on the distinct scenarios in which HEAD-DT may be applied to. In addition, a discussion on the cost effectiveness of automatic design, as well as examples of automatically-designed algorithms and a baseline comparison between genetic and random search are also presented.
Chapter 6 [HEAD-DT: Fitness Function Analysis]. This chapter conducts an investigation of 15 distinct versions for HEAD-DT by varying its fitness function, and a new set of experiments with the best-performing strategies in balanced and imbalanced data sets is described.
Chapter 7 [Conclusions]. We finish this book by presenting the current limitations of the automatic design, as well as our view of several exciting opportunities for future work.
机器学习代写|决策树作业代写decision tree代考|Decision-tree induction algorithms
Abstract Decision-tree induction algorithms are highly used in a variety of domains for knowledge discovery and pattern recognition. They have the advantage of producing a comprehensible classification/regression model and satisfactory accuracy levels in several application domains, such as medical diagnosis and credit risk assessment. In this chapter, we present in detail the most common approach for decision-tree induction: top-down induction (Sect. 2.3). Furthermore, we briefly comment on some alternative strategies for induction of decision trees (Sect. 2.4). Our goal is to summarize the main design options one has to face when building decision-tree induction algorithms. These design choices will be specially interesting when designing an evolutionary algorithm for evolving decision-tree induction algorithms.
Keywords Decision trees – Hunt’s algorithm . Top-down induction – Design components
决策树代写
机器学习代写|决策树作业代写decision tree代考|Introduction
分类是将对象分配到预定义类别的数据挖掘任务,广泛应用于智能决策过程。机器学习、统计学和模式识别领域的研究人员已经提出了许多分类技术。这些技术可以根据它们的可理解程度大致划分。例如,产生可解释分类模型的技术被称为白盒方法,而那些不能产生可解释分类模型的技术被称为黑盒方法。使用白盒技术进行分类有几个优点,例如增加用户对预测的信心,提供关于分类问题的新见解,以及允许检测模型或数据中的错误 [12]。白盒分类技术的例子是分类规则和决策树。后者是本书的重点。
决策树是由类似流程图的树结构表示的分类器,已广泛用于表示分类模型,特别是由于其类似于人类推理的可理解性。在 kdnuggets 网站 [13] 最近的一项民意调查中,决策树被认为是研究人员和从业者最常用的数据挖掘/分析方法,重申了其在机器学习任务中的重要性。与其他学习算法相比,决策树归纳算法具有几个优点,例如对噪声的鲁棒性、生成模型的低计算成本以及处理冗余属性的能力 [22]。
尽管最成功的算法可以追溯到 80 年代中期 [4] 和早期90 s[21]. 采用了许多策略来推导准确的决策树,例如自下而上的归纳[1,17]、线性规划 [3]、混合归纳 [15] 和树的集合 [5],仅举几例。然而,没有一种策略比贪心自上而下的归纳策略更成功地生成准确且易于理解的决策树,而且计算量很小。
贪心自上而下的决策树归纳算法递归地分析数据样本是否应根据给定规则划分为子集,或者是否需要进一步划分。该分析考虑了一个停止标准,对于
决定何时停止树的生长,以及一个分裂标准,它负责选择划分子集的“最佳”规则。对这一基本策略的进一步改进包括修剪树节点以增强树处理噪声数据的能力,以及处理缺失值、不平衡类、倾斜分割等的策略。
对于决策树归纳算法的这些设计组件中的每一个,文献中都提出了非常大量的方法。例如,提出了针对大量应用领域量身定制的节点拆分新措施,以及用于选择多个属性来组成节点规则(多变量拆分)的许多不同策略。文献中甚至有研究调查了修剪决策树的众多方法[6,9]. 很明显,通过改进这些设计组件,可以获得更有效的决策树归纳算法。
机器学习代写|决策树作业代写decision tree代考|Book Outline
本书共7章,内容如下。
第 2 章【决策树归纳】。本章介绍自上而下归纳的起源、基本概念、详细组成部分以及其他决策树归纳策略。
第 3 章 [进化算法和超启发式]。本章涵盖进化算法和超启发式算法的起源、基本概念和技术。
第 4 章 [HEAD-DT:决策树归纳算法的自动设计]。本章介绍并讨论了能够自动设计决策树算法的超启发式进化算法。深入介绍了进化方案、构建块、适应度评估、选择、遗传算子和搜索空间等细节。
第 5 章 [HEAD-DT:实验分析]。本章对 HEAD-DT 可能适用的不同场景进行了全面的实证分析。此外,还讨论了自动设计的成本效益,以及自动设计算法的示例以及遗传和随机搜索之间的基线比较。
第 6 章 [HEAD-DT:适应度函数分析]。本章通过改变其适应度函数对 HEAD-DT 的 15 个不同版本进行了调查,并描述了一组在平衡和不平衡数据集中表现最佳策略的新实验。
第7章[结论]。我们通过介绍当前自动设计的局限性以及我们对未来工作的几个令人兴奋的机会的看法来结束这本书。
机器学习代写|决策树作业代写decision tree代考|Decision-tree induction algorithms
摘要 决策树归纳算法广泛应用于知识发现和模式识别的各个领域。它们具有在多个应用领域(例如医疗诊断和信用风险评估)生成可理解的分类/回归模型和令人满意的准确度水平的优势。在本章中,我们将详细介绍最常见的决策树归纳方法:自上而下的归纳(第 2.3 节)。此外,我们简要评论了一些用于归纳决策树的替代策略(第 2.4 节)。我们的目标是总结在构建决策树归纳算法时必须面对的主要设计选项。在为进化决策树归纳算法设计进化算法时,这些设计选择将特别有趣。
关键词决策树——亨特算法。自上而下的归纳——设计组件

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。