如果你也在 怎样代写强化学习reinforence learning这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
强化学习是一种基于奖励期望行为和/或惩罚不期望行为的机器学习训练方法。一般来说,强化学习代理能够感知和解释其环境,采取行动并通过试验和错误学习。
statistics-lab™ 为您的留学生涯保驾护航 在代写强化学习reinforence learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写强化学习reinforence learning代写方面经验极为丰富,各种代写强化学习reinforence learning相关的作业也就用不着说。
我们提供的强化学习reinforence learning及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础

机器学习代写|强化学习project代写reinforence learning代考|Further Comparison
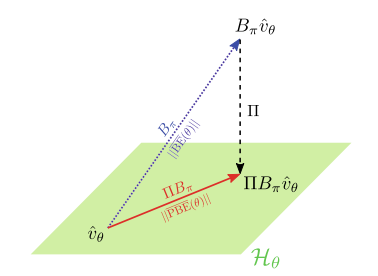
$\mathrm{TD}(0)$ and RG both perform SGD on the $\overline{\mathrm{BE}}$, with $\mathrm{TD}(0)$ simply ignoring the fact, that the one-step TD error also depends on the parameters $\theta$. When assuming linear function approximation, this comparison can also be shown using objective function formulations. Since $\Pi$ represents a orthogonal projection, the relation
$$
|\overline{\mathrm{BE}}(\theta)|^{2}=|\overline{\mathrm{PBE}}(\theta)|^{2}+\left|B_{\pi} \hat{v}{\theta}-\Pi B{\pi} \hat{v}{\theta}\right|^{2} $$ is valid (compare Fig. 1). Since the TD-fix-point is congruent with the fix-point of the $\overline{\mathrm{PBE}}, \mathrm{TD}(0)$ only minimizes the $\overline{\mathrm{PBE}}$ and ignores the term $\left|B{\pi} \hat{v}{\theta}-\Pi B{\pi} \hat{v}_{\theta}\right|^{2}$, that is crucial for guaranteed convergence. In contrast RG minimizes both parts of the $\overline{\mathrm{BE}}$ objective. Furthermore the relation shows, that the $\overline{\mathrm{BE}}$, minimized by $\mathrm{RG}$, is an upper bound for the $\overline{\mathrm{PBE}}$, minimized by TD-learning. So minimizing the $\overline{\mathrm{BE}}$ ensures small TD errors. Since optimizing the $\overline{\mathrm{BE}}$ objective using $\mathrm{RG}$ in a way includes the optimization of the $\overline{\mathrm{PBE}}$ objective done by $\mathrm{TD}(0), \mathrm{RG}$ appears to be more difficult from a numerical point of view [8]. The $\overline{\mathrm{BE}}$ objective also suffers from higher variance in its estimates and is therefore harder to optimize [8].
Assuming linear function approximation Li [6] compared $\mathrm{TD}(0)$ and RG with respect to prediction errors $(\overline{\mathrm{VE}})$. The derived bounds for TD $(0)$ are tighter than those for RG, i.e. performance of $\mathrm{TD}(0)$ seems to result in a smaller $\overline{\mathrm{VE}}$. With respect to RG Scherrer [8] also derived an upper bound for the $\overline{\mathrm{VE}}$ using the $\overline{\mathrm{BE}}$. However Dann, Neumann and Peters [3] observed this bound to be too loose for many MDPs in real applications. Sun and Bagnell [9] managed to tighten the bounds for the prediction error of RG even more, even with less strict assumptions than all previous attempts and even for nonlinear function approximation. Although the bounds for $\mathrm{TD}(0)$ are still tighter than those for RG, Sun and Bagnell [9] find in experiments, that residual gradient methods have the potential to achieve smaller prediction errors than temporal-difference methods. Those results are contradictory to the derived bounds
and to the work of Scherrer [8], that finds, that approximation functions derived using the fix-point of the $\overline{\mathrm{PBE}}$ often achieve a lower $\overline{\mathrm{VE}}$ than functions congruent with the fix-point of the $\overline{\mathrm{BE}}$.
Nevertheless, the main point affecting RG is the double sampling problem. Also the $\overline{\text { TDE }}$ objective, that is optimized by RG when simply sampling just one successor state for each state, has not been investigated much in research [3]. In addition Lagoudakis and Parr [5] found, that policy iteration making use of the $\overline{\text { PBE }}$ objective results in control policies of higher quality. Furthermore, congruent to Baird [1], Scherrer [8] and Dann, Neumann and Peters [3] also find TD $(0)$ to converge much faster than RG. Finally Sutton and Barto [11] question the learnability of the Bellman Error and therefore the $\overline{\mathrm{BE}}$ as an objective in general. Altogether TD $(0)$ seems to be preferable, as long as it does not diverge. In the next section, more recent approaches are stated, which combine the advantages of temporal-differences methods with guaranteed convergence.
机器学习代写|强化学习project代写reinforence learning代考|Recent Methods and Approaches
In 2009 Sutton, Maei and Szepesvári [13] introduced a stable off-policy temporaldifference algorithm called gradient temporal-difference (GTD). GTD was the first algorithm achieving guaranteed off-policy convergence and linear complexity in memory and per-time-step computation using temporal differences and linear function approximation. GTD performs SGD on a new objective, called norm of the expected TD update (NEU). When optimizing the NEU objective, there are two estimates $\theta$ and $\omega$ of the parameters of the approximation function. First the approximation value function $\hat{v}{\theta}$ is mapped against the one-step TD estimations of the true values of the states (the targets), which are calculated using $\hat{v}{\omega}$. Second $\hat{v}{\omega}$ is mapped against $\hat{v}{\theta}$. Maintaining two individual approximation functions, one for estimating the targets and one for the actual value function approximation, was also one of two key ideas by Mnih et al. [7] to achieve greater success with deep QLearning. Q-Learning is closely related to the problem of non-linear critic-learning. (The second key idea was the introduction of an experience replay memory.) Like Q-Learning, GTD was also extended by Bhatnagar et al. [2] to non-linear function approximation. As all non-linear optimization approaches, it also suffers from potential failures caused by the non-convexity of the optimization objective. GTD, though achieving a lot desirable properties, still converges much slower than conventional $\mathrm{TD}(0)$. Therefore Sutton et al. [12] introduced two new non-linear approximation algorithms, gradient temporal-difference 2 (GTD2) and linear TD with gradient correction (TDC), which converge both faster than GTD. They both perform SGD directly on the $\overline{\mathrm{PBE}}$ objective and TDC even seems to achieve the same (sometimes even better) convergence speed as $\mathrm{TD}(0)$.
机器学习代写|强化学习project代写reinforence learning代考|Conclusion
We have reviewed the fundamental contents to understand critic learning. We explained all basic objective functions and compared Temporal-difference learning and the Residual-Gradient algorithm. Thereby Temporal-difference learning was found to be the preferable choice. Also some more recent approaches based on Temporal-difference learning have been reviewed. Like the Residual-Gradient algorithm those approaches are also stable in the off-policy case, but possess better properties.
Nevertheless several aspects have not been considered in this paper, like other optimization techniques to solve the discussed objective functions (e.g. least-squares or probabilistic approaches), extensions like eligibility-traces and further comparison and investigation concerning to the related topic of Q-Learning (and its achievements like $\mathrm{DQN}$ and dueling networks).
强化学习代写
机器学习代写|强化学习project代写reinforence learning代考|Further Comparison
吨D(0)和 RG 都在乙和¯, 和吨D(0)简单地忽略一个事实,即一步 TD 误差也取决于参数θ. 当假设线性函数近似时,这种比较也可以使用目标函数公式来表示。自从圆周率表示正交投影,关系
|乙和¯(θ)|2=|磷乙和¯(θ)|2+|乙圆周率在^θ−圆周率乙圆周率在^θ|2是有效的(比较图 1)。由于 TD-fix-point 与磷乙和¯,吨D(0)只会最小化磷乙和¯并忽略该术语|乙圆周率在^θ−圆周率乙圆周率在^θ|2,这对于保证收敛至关重要。相比之下,RG 最小化了乙和¯客观的。此外,该关系表明,乙和¯, 最小化RG, 是上界磷乙和¯,通过 TD 学习最小化。所以最小化乙和¯确保小的 TD 误差。由于优化乙和¯客观使用RG在某种程度上包括优化磷乙和¯目标完成吨D(0),RG从数值的角度来看似乎更困难[8]。这乙和¯Objective 的估计也存在较大的方差,因此更难优化 [8]。
假设线性函数逼近李[6]比较吨D(0)和 RG 关于预测误差(在和¯). TD 的派生界限(0)比那些为 RG 更紧,即性能吨D(0)似乎导致更小的在和¯. 关于 RG Scherrer [8] 还得出了在和¯使用乙和¯. 然而,Dann、Neumann 和 Peters [3] 观察到,对于实际应用中的许多 MDP,这必然过于松散。Sun 和 Bagnell [9] 设法进一步收紧了 RG 的预测误差的界限,即使假设没有以前所有的尝试那么严格,甚至对于非线性函数逼近也是如此。虽然界限为吨D(0)仍然比 RG、Sun 和 Bagnell [9] 在实验中发现的更严格,残差梯度方法有可能实现比时间差分方法更小的预测误差。这些结果与导出的界限相矛盾
Scherrer [8] 的工作发现,使用磷乙和¯经常达到较低的在和¯比与固定点一致的函数乙和¯.
然而,影响 RG 的主要问题是双采样问题。还有 TDE ¯目标,即在简单地为每个状态仅采样一个后继状态时由 RG 优化,在研究中尚未进行太多研究 [3]。此外,Lagoudakis 和 Parr [5] 发现,策略迭代利用 PBE ¯客观导致更高质量的控制政策。此外,与 Baird [1]、Scherrer [8] 和 Dann、Neumann 和 Peters [3] 一致也发现 TD(0)收敛速度比 RG 快得多。最后 Sutton 和 Barto [11] 质疑贝尔曼错误的可学习性,因此乙和¯作为一个总体目标。总TD(0)似乎更可取,只要它不发散。在下一节中,将陈述最近的方法,它们结合了时间差分方法的优点和保证收敛。
机器学习代写|强化学习project代写reinforence learning代考|Recent Methods and Approaches
2009 年,Sutton、Maei 和 Szepesvári [13] 引入了一种稳定的离策略时间差算法,称为梯度时间差 (GTD)。GTD 是第一个使用时间差异和线性函数逼近在内存和每时间步计算中实现有保证的非策略收敛和线性复杂性的算法。GTD 对一个新目标执行 SGD,称为预期 TD 更新 (NEU) 的范数。在优化 NEU 目标时,有两个估计θ和ω的近似函数的参数。首先是近似值函数在^θ映射到状态(目标)的真实值的一步 TD 估计,这些估计是使用在^ω. 第二在^ω映射到在^θ. 维护两个单独的近似函数,一个用于估计目标,一个用于实际值函数近似,这也是 Mnih 等人的两个关键思想之一。[7] 通过深度 QLearning 取得更大的成功。Q-Learning 与非线性批评学习问题密切相关。(第二个关键思想是引入经验回放记忆。)与 Q-Learning 一样,GTD 也被 Bhatnagar 等人扩展。[2] 到非线性函数逼近。与所有非线性优化方法一样,它也存在由优化目标的非凸性引起的潜在故障。GTD 虽然实现了很多理想的特性,但仍然比传统的收敛速度慢得多吨D(0). 因此萨顿等人。[12] 引入了两种新的非线性逼近算法,梯度时间差 2(GTD2)和带梯度校正的线性 TD(TDC),它们的收敛速度都比 GTD 快。他们都直接在磷乙和¯目标和 TDC 甚至似乎达到了相同(有时甚至更好)的收敛速度吨D(0).
机器学习代写|强化学习project代写reinforence learning代考|Conclusion
我们回顾了基本内容来理解批评学习。我们解释了所有基本目标函数,并比较了时间差分学习和残差梯度算法。因此,时间差分学习被发现是更可取的选择。还回顾了一些基于时差学习的最新方法。与残差梯度算法一样,这些方法在非策略情况下也很稳定,但具有更好的属性。
尽管如此,本文还没有考虑几个方面,例如解决所讨论目标函数的其他优化技术(例如最小二乘或概率方法)、资格跟踪等扩展以及与 Q-Learning 相关主题的进一步比较和调查(及其成就如D问ñ和决斗网络)。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。