如果你也在 怎样代写数据库SQL这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
结构化查询语言(SQL)是一种标准化的编程语言,用于管理关系型数据库并对其中的数据进行各种操作。
statistics-lab™ 为您的留学生涯保驾护航 在代写数据库SQL方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写数据库SQL代写方面经验极为丰富,各种代写数据库SQL相关的作业也就用不着说。
我们提供的数据库SQL及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
计算机代写|数据库作业代写SQL代考|SQL Query Structure
SQL queries have common clauses and syntax, although these can be combined in a nearly infinite number of ways to achieve analysis goals. This book assumes you have some prior knowledge of SQL, but I’ll review the basics here so that we have a common foundation for the code examples to come.
The SELECT clause determines the columns that will be returned by the query. One column will be returned for each expression within the SELECT clause, and expressions are separated by commas. An expression can be a field from the table, an aggregation such as a sum, or any number of calculations, such as CASE statements, type conversions, and various functions that will be discussed later in this chapter and throughout the book.
The FROM clause determines the tables from which the expressions in the SELECT clause are derived. A “table” can be a database table, a view (a type of saved query that otherwise functions like a table), or a subquery. A subquery is itself a query, wrapped in parentheses, and the result is treated like any other table by the query that references it. A query can reference multiple tables in the FROM clause, though they must use one of the JOIN types along with a condition that specifies how the tables relate. The JOIN condition usually specifies an squality between ficlds in cach table, such as orders.customer_id = customers.customer_id. JOIN conditions can include multiple fields and can also specify inequalities or ranges of values, such as ranges of dates. We’ll see a variety of JOIN conditions that achieve specific analysis goals throughout the book. An INNER JOIN returns all records that match in both tables. A LEFT JOIN returns all records from the first table, but only those records from the second table that match. A RIGHT JOIN returns all records from the second table, but only those records from the first table that match. A FULL OUTER JOIN returns all records from both tables. A Cartesian JOIN can result when each record in the first table matches more than one record in the second table. Cartesian JOINs should generally be avoided, though there are some specific use cases, such as generating data to fill in a time series, in which we will use them intentionally. Finally, tables in the FROM clause can be aliased, or given a shorter name of one or more letters that can be referenced in other clauses in the query. Aliases save query writers from having to type out long table names repeatedly, and they make queries easier to read.
计算机代写|数据库作业代写SQL代考|Profiling: Distributions
Profiling is the first thing I do when I start working with any new data set. I look at how the data is arranged into schemas and tables. I look at the table names to get familiar with the topics covered, such as customers, orders, or visits. I check out the column names in a few tables and start to construct a mental model of how the tables relate to one another. For example, the tables might include an order_detail table with line-item breakouts that relate to the order table via an order_id, while the order table relates to the customer table via a customer_id. If there is a data dictionary, I review that and compare it to the data I see in a sample of rows.
The tables generally represent the operations of an organization, or some subset of the operations, so I think about what domain or domains are covered, such as ecommerce, marketing, or product interactions. Working with data is easier when we have knowledge of how the data was generated. Profiling can provide clues about this, or about what questions to ask of the source, or of people inside or outside the organization responsible for the collection or generation of the data. Even when you collect the data yourself, profiling is useful.
Another detail I check for is how history is represented, if at all. Data sets that are replicas of production databases may not contain previous values for customer addresses or order statuses, for example, whereas a well-constructed data warehouse may have daily snapshots of changing data fields.
Profiling data is related to the concept of exploratory data analysis, or EDA, named by John Tukey. In his book of that name, ${ }^{1}$ Tukey describes how to analyze data sets by computing various summaries and visualizing the results. He includes techniques for looking at distributions of data, including stem-and-leaf plots, box plots, and histograms.
After checking a few samples of data, I start looking at distributions. Distributions allow me to understand the range of values that exist in the data and how often they occur, whether there are nulls, and whether negative values exist alongside positive ones. Distributions can be created with continuous or categorical data and are also called frequencies. In this section, we’ll look at how to create histograms, how binning can help us understand the distribution of continuous values, and how to use n-tiles to get more precise about distributions.
计算机代写|数据库作业代写SQL代考|Histograms and Frequencies
One of the best ways to get to know a data set, and to know particular fields within the data set, is to check the frequency of values in each field. Frequency checks are also useful whenever you have a question about whether certain values are possible or if you spot an unexpected value and want to know how commonly it occurs. Frequency checks can be done on any data type, including strings, numerics, dates, and booleans. Frequency queries are a great way to detect sparse data as well.
The query is straightforward. The number of rows can be found with count(* ), and the profiled field is in the GROUP BY. For example, we can check the frequency of each type of fruit in a fictional fruit_inventory table:
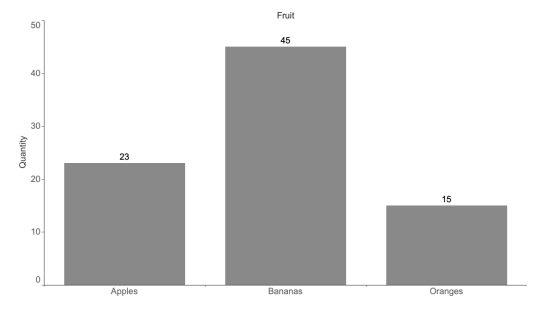
A frequency plot is a way to visualize the number of times something occurs in the data set. The field being profiled is usually plotted on the $x$-axis, with the count of observations on the $y$-axis. Figure 2-1 shows an example of plotting the frequency of fruit from our query. Frequency graphs can also be drawn horizontally, which accommodates long value names well. Notice that this is categorical data without any inherent order.
SQL代考
计算机代写|数据库作业代写SQL代考|SQL Query Structure
SQL 查询具有通用的子句和语法,尽管它们可以以几乎无限的方式组合以实现分析目标。本书假设您有一些 SQL 的先验知识,但我将在这里回顾基础知识,以便我们为后面的代码示例有一个共同的基础。
SELECT 子句确定查询将返回的列。SELECT 子句中的每个表达式都将返回一列,表达式用逗号分隔。表达式可以是表中的字段、聚合(如求和)或任意数量的计算(如 CASE 语句、类型转换和将在本章后面和整本书中讨论的各种函数)。
FROM 子句确定派生 SELECT 子句中的表达式的表。“表”可以是数据库表、视图(一种保存的查询类型,其功能类似于表)或子查询。子查询本身就是一个查询,用括号括起来,结果被引用它的查询与任何其他表一样对待。一个查询可以在 FROM 子句中引用多个表,但它们必须使用一种 JOIN 类型以及一个指定表如何关联的条件。JOIN 条件通常指定 cach 表中 ficld 之间的 squality,例如 orders.customer_id = customers.customer_id。JOIN 条件可以包括多个字段,还可以指定不等式或值范围,例如日期范围。我们将在整本书中看到各种实现特定分析目标的 JOIN 条件。INNER JOIN 返回两个表中匹配的所有记录。LEFT JOIN 返回第一个表中的所有记录,但仅返回第二个表中匹配的那些记录。RIGHT JOIN 返回第二个表中的所有记录,但仅返回第一个表中匹配的那些记录。FULL OUTER JOIN 返回两个表中的所有记录。当第一个表中的每条记录与第二个表中的多个记录匹配时,可能会导致笛卡尔连接。通常应该避免笛卡尔 JOIN,尽管有一些特定的用例,例如生成数据以填充时间序列,我们将在其中有意使用它们。最后,FROM 子句中的表可以别名,或给出一个或多个字母的较短名称,可以在查询的其他子句中引用。别名使查询编写者不必重复输入长表名,并且它们使查询更易于阅读。
计算机代写|数据库作业代写SQL代考|Profiling: Distributions
分析是我开始使用任何新数据集时要做的第一件事。我看看数据是如何排列到模式和表中的。我查看表名以熟悉所涵盖的主题,例如客户、订单或访问。我检查了几个表中的列名,并开始构建一个表如何相互关联的心理模型。例如,这些表可能包括一个 order_detail 表,其中包含通过 order_id 与 order 表相关的行项目细分,而 order 表通过 customer_id 与 customer 表相关。如果有数据字典,我会查看它并将其与我在行样本中看到的数据进行比较。
这些表通常代表一个组织的运营,或运营的某个子集,所以我考虑涵盖哪些域或域,例如电子商务、营销或产品交互。当我们了解数据的生成方式时,使用数据会更容易。剖析可以提供有关这方面的线索,或者关于要向来源或负责收集或生成数据的组织内部或外部的人员提出什么问题的线索。即使您自己收集数据,分析也很有用。
我检查的另一个细节是历史是如何表示的,如果有的话。例如,作为生产数据库副本的数据集可能不包含客户地址或订单状态的先前值,而构建良好的数据仓库可能具有更改数据字段的每日快照。
分析数据与由 John Tukey 命名的探索性数据分析或 EDA 的概念有关。在他那个名字的书中,1Tukey 描述了如何通过计算各种摘要和可视化结果来分析数据集。他介绍了查看数据分布的技术,包括茎叶图、箱线图和直方图。
在检查了一些数据样本后,我开始查看分布。分布使我能够了解数据中存在的值的范围以及它们出现的频率、是否存在空值以及负值是否与正值一起存在。可以使用连续或分类数据创建分布,也称为频率。在本节中,我们将了解如何创建直方图,分箱如何帮助我们理解连续值的分布,以及如何使用 n-tile 来更精确地了解分布。
计算机代写|数据库作业代写SQL代考|Histograms and Frequencies
了解数据集并了解数据集中特定字段的最佳方法之一是检查每个字段中值的频率。每当您对某些值是否可能存在疑问或发现意外值并想知道它发生的频率时,频率检查也很有用。可以对任何数据类型进行频率检查,包括字符串、数字、日期和布尔值。频率查询也是检测稀疏数据的好方法。
查询很简单。可以使用 count(*) 找到行数,并且已分析的字段位于 GROUP BY 中。例如,我们可以在一个虚构的 fruit_inventory 表中检查每种水果的频率:
频率图是一种可视化数据集中某事发生的次数的方法。被分析的字段通常绘制在X-axis,与观察的计数是-轴。图 2-1 显示了一个从我们的查询中绘制水果频率的示例。频率图也可以水平绘制,可以很好地适应长值名称。请注意,这是没有任何固有顺序的分类数据。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。