如果你也在 怎样代写流形学习manifold data learning这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
流形学习是机器学习的一个流行且快速发展的子领域,它基于一个假设,即一个人的观察数据位于嵌入高维空间的低维流形上。本文介绍了流形学习的数学观点,深入探讨了核学习、谱图理论和微分几何的交叉点。重点放在图和流形之间的显著相互作用上,这构成了流形正则化技术的广泛使用的基础。
statistics-lab™ 为您的留学生涯保驾护航 在代写流形学习manifold data learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写流形学习manifold data learning代写方面经验极为丰富,各种代写流形学习manifold data learning相关的作业也就用不着说。
我们提供的流形学习manifold data learning及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
机器学习代写|流形学习代写manifold data learning代考|Shounak Roychowdhury and Joydeep Ghosh
Dimensionality reduction is an important process that is often required to understand the data in a more tractable and humanly comprehensible way. This process has been extensively studied in terms of linear methods such as Principal Component Analysis (PCA), Independent Component Analysis (ICA), Factor Analysis etc. [8]. However, it has been noticed that many high dimensional data, such as a series of related images, lie on a manifold $[12]$ and are not scattered throughout the feature space.
Belkin and Niyogi in [2] proposed Laplacian Eigenmaps (LEM), a method that approximates the Laplace-Beltrami Operator which is able to capture the properties of any Riemaniann manifold. The motivation of our work derives from our experimental observations that when the graph that used Laplacian Eigenmaps (LEM) [2] is not well-constructed (either it has lot of isolated vertices or there are islands of subgraphs) the data is difficult to interpret after a dimension reduction. This paper discusses how global information can be used in addition to local information in the framework of Laplacian Eigenmaps to address such situations. We make use of an interesting result by Costa and Hero that shows that Minimum Spanning Tree on a manifold can reveal its intrinsic dimension and entropy [4]. In other words, it implies that MSTs can capture the underlying global structure of the manifold if it exists. We use this finding to extend the dimension reduction technique using LEM to exploit both local and global information.
LEM depends on the Graph Laplacian matrix and so does our work. Fiedler initially proposed the Graph Laplacian matrix as a means to comprehend the notion of algebraic connectivity of a graph [6]. Merris has extensively discussed the wide variety of properties of the Laplacian matrix of a graph such as invariance, on various bounds and inequalities, extremal examples and constructions, etc., in his survey [10]. A broader role of the Laplacian matrix can be seen in Chung’s book on Spectral Graph Theory [3].
The second section touches on the Graph Laplacian matrix. The role of global information in manifold learning is then presented, followed by our proposed approach of augmenting LEM by including global information about the data. Experimental results confirm that global information can indeed help when the local information is limited for manifold learning.
机器学习代写|流形学习代写manifold data learning代考|Graph Laplacian
Let us consider a weighted graph $G=(V, E)$, where $V=V(G)=\left{v_{1}, v_{2}, \ldots, v_{n}\right}$ is the set of vertices (also called vertex set) and $E=E(G)=\left{e_{1}, e_{2}, \ldots, e_{n}\right}$ is the set of edges (also called edge set). The weight $w$ function is defined as $w: V \times V \rightarrow \Re$ such that $w\left(v_{i}, v_{j}\right)=w\left(v_{j}, v_{i}\right)=w_{i j}$.
Definition 1: The Laplacian [6] of a graph without loops of multiple edges is defined as the following:
$$
L(G)= \begin{cases}d_{v_{i}} & \text { if } v_{i}=v_{j} \ -1 & \text { if } v_{i} \text { are } v_{j} \text { adjacent } \ 0 & \text { Otherwise }\end{cases}
$$
Fiedler [6] defined the Laplacian of a graph as a symmetric matrix for a regular graph, where $A$ is an adjacency matrix ( $A^{T}$ is the transpose of adjacency matrix), $I$ is the identity matrix, and $n$ is the degree of the regular graph:
$$
L(G)=n I-A .
$$
A definition by Chung (see [3]) – which is given below – generalizes the Laplacian by adding the weights on the edges of the graph. It can be viewed as Weighed Graph Laplacian. Simply, it is a difference between the diagonal matrix $D$ and $W$, the weighted adjacency matrix.
$$
L_{W}(G)=D-W,
$$
where the diagonal element in $D$ is defined as $d_{v_{i}}=\sum_{j=1}^{n} w\left(v_{i}, v_{j}\right)$.
Definition 2: The Laplacian of weighted graph (operator) is defined as the following:
$$
L_{w}(G)= \begin{cases}d_{v_{i}}-w\left(v_{i}, v_{j}\right) & \text { if } v_{i}=v_{j} \ -w\left(v_{i}, v_{j}\right) & \text { if } v_{i} \text { are } v_{j} \text { connected } \ 0 & \text { otherwise. }\end{cases}
$$
$L_{w}(G)$ reduces to $L(G)$ when the edges have unit weights.
机器学习代写|流形学习代写manifold data learning代考|Global Information of Manifold
Global information has not been used in manifold learning since it is widely believed that global information may capture unnecessary data (like ambient data points) that should be avoided when dealing with manifolds.
However, some recent research results show that that it might be useful to to explore global information in a more constrained manner for manifold learning. Costa and Hero show that it is possible to use a Geodesic Minimum Spanning Tree (GMST) on the manifold to estimate the intrinsic dimension and intrinsic entropy of the manifold [4].
Costa and Hero showed in the following theorem that is possible to learn the intrinsic entropy and intrinsic dimension of a non-linear manifold by extending the BHH theorem [1], a well-known result in Geometric Probability.
Theorem: [Generalization of BHH Theorem to Embedded manifolds: [4]] Let $\mathcal{M}$ be a smooth compact $m$-dimensional manifold embedded in $\mathbb{R}^{d}$ through the diffeomorphism $\phi: \Omega \rightarrow \mathcal{M}$, and $\Omega \in \mathbb{R}^{d}$. Assume $2 \leq m \leq d$ and $0<\gamma<m$. Suppose that $Y_{1}, Y_{2}, \ldots$ are iid random vectors on $\mathcal{M}$ having a common density function $f$ with respect to a Lebesgue measure $\mu_{\mathcal{M}}$ on $\mathcal{M}$. Then the length functional $T_{\gamma}^{\mathbb{R}^{m}} \phi_{-1}\left(Y_{n}\right)$ of the MST spanning $\phi^{-1}\left(Y_{n}\right)$ satisfies the equation shown below in an almost sure sense:
$$
\lim {n \rightarrow \infty} \frac{T{\gamma}^{2^{m}} \phi_{-1}\left(Y_{n}\right)}{n \frac{(d-1)}{d}}=
$$
where $\alpha=(m-\gamma) / m$, and is always between $0<\alpha<1, J$ is the Jacobian, and $\beta_{m}$ is $a$ constant which depends on $m$.
Based on the above theorem we use MST on the entire data set as a source of global information. For more details see $[4]$, and more background information see [15] and [13].
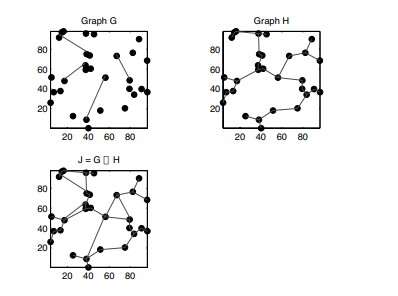
The basic principle of GLEM is quite straightforward. The objective function that is to be minimized is given by the following (it is has the same flavor and notation used in [2]):
$$
\begin{aligned}
& \sum_{i, j}\left|\mathbf{y}^{(\mathbf{i})}-\mathbf{y}^{(\mathbf{j})}\right|_{2}^{2}\left(W_{i j}^{N N}+W_{i j}^{M S T}\right) \
=& \operatorname{tr}\left(\mathbf{Y}^{T} L\left(G_{N N}\right) \mathbf{Y}+\mathbf{Y}^{T} L\left(G_{M S T}\right) \mathbf{Y}\right) \
=& \operatorname{tr}\left(\mathbf{Y}^{T}\left(L\left(G_{N N}\right)+L\left(G_{M S T}\right)\right) \mathbf{Y}\right) \
=& \operatorname{tr}\left(\mathbf{Y}^{T} L(J) \mathbf{Y}\right) .
\end{aligned}
$$
where $\mathbf{y}^{(i)}=\left[y_{1}(i), \ldots, y_{m}(i)\right]^{T}$, and $m$ is the dimension of embedding. $W_{i j}^{N N}$ and $W_{i j}^{M S T}$ are weighted matrices of k-Nearest Neighbor graph and the MST graph respectively. In other words, we have
$$
\operatorname{argmin}{\mathbf{Y T} \mathbf{Y}=\mathbf{I}} \mathbf{Y}^{T} L \mathbf{Y} $$ such that $Y=\left[\mathbf{y}{\mathbf{1}}, \mathbf{y}{\mathbf{2}}, \ldots, \mathbf{y}{\mathbf{m}}\right]$ and $\mathbf{y}^{(\mathbf{i})}$ is the $m$-dimensional representation of $i^{\text {th }}$ vertex. The solutions to this optimization problem are the eigenvectors of the generalized eigenvalue problem
$$
L \mathbf{Y}=\Lambda D \mathbf{Y}
$$
The GLEM algorithm is described in Algorithm $1 .$
流形学习代写
机器学习代写|流形学习代写manifold data learning代考|Shounak Roychowdhury and Joydeep Ghosh
降维是一个重要的过程,通常需要以更易于处理和人类理解的方式理解数据。这个过程已经在线性方法方面得到了广泛的研究,如主成分分析(PCA)、独立成分分析(ICA)、因子分析等[8]。然而,已经注意到许多高维数据,例如一系列相关图像,位于流形上[12]并且不会分散在整个特征空间中。
Belkin 和 Niyogi 在 [2] 中提出了 Laplacian Eigenmaps (LEM),这是一种近似 Laplace-Beltrami 算子的方法,能够捕获任何黎曼流形的属性。我们工作的动机源于我们的实验观察,即当使用拉普拉斯特征图 (LEM) [2] 的图构造不完善(它有很多孤立的顶点或存在子图岛)时,数据很难解释降维后。本文讨论了如何在拉普拉斯特征图框架中使用全局信息和局部信息来解决这种情况。我们利用了 Costa 和 Hero 的一个有趣结果,该结果表明流形上的最小生成树可以揭示其内在维度和熵 [4]。换句话说,这意味着 MST 可以捕获流形的潜在全局结构(如果存在)。我们利用这一发现来扩展使用 LEM 的降维技术,以利用本地和全局信息。
LEM 依赖于图拉普拉斯矩阵,我们的工作也是如此。Fiedler 最初提出图拉普拉斯矩阵作为理解图的代数连通性概念的一种手段 [6]。Merris 在他的调查 [10] 中广泛讨论了图的拉普拉斯矩阵的各种属性,例如不变性、各种边界和不等式、极值示例和构造等。拉普拉斯矩阵的更广泛作用可以在 Chung 的关于谱图理论的书中看到 [3]。
第二部分涉及图拉普拉斯矩阵。然后介绍了全局信息在流形学习中的作用,然后是我们提出的通过包含有关数据的全局信息来增强 LEM 的方法。实验结果证实,当局部信息受限于流形学习时,全局信息确实可以提供帮助。
机器学习代写|流形学习代写manifold data learning代考|Graph Laplacian
让我们考虑一个加权图G=(在,和), 在哪里V=V(G)=\left{v_{1}, v_{2}, \ldots, v_{n}\right}V=V(G)=\left{v_{1}, v_{2}, \ldots, v_{n}\right}是顶点集(也称为顶点集)和E=E(G)=\left{e_{1}, e_{2}, \ldots, e_{n}\right}E=E(G)=\left{e_{1}, e_{2}, \ldots, e_{n}\right}是边的集合(也称为边集)。重量在函数定义为在:在×在→ℜ这样在(在一世,在j)=在(在j,在一世)=在一世j.
定义 1:没有多重边环的图的拉普拉斯算子 [6] 定义如下:
大号(G)={d在一世 如果 在一世=在j −1 如果 在一世 是 在j 邻近的 0 除此以外
Fiedler [6] 将图的拉普拉斯算子定义为正则图的对称矩阵,其中一种是一个邻接矩阵 (一种吨是邻接矩阵的转置),一世是单位矩阵,并且n是正则图的度数:
大号(G)=n一世−一种.
Chung 的定义(见 [3])——下面给出——通过在图的边缘上添加权重来概括拉普拉斯算子。它可以看作是加权图拉普拉斯算子。简单来说,就是对角矩阵的区别D和在,加权邻接矩阵。
大号在(G)=D−在,
其中对角线元素在D定义为d在一世=∑j=1n在(在一世,在j).
定义2:加权图(算子)的拉普拉斯算子定义如下:
大号在(G)={d在一世−在(在一世,在j) 如果 在一世=在j −在(在一世,在j) 如果 在一世 是 在j 连接的 0 除此以外。
大号在(G)减少到大号(G)当边有单位权重时。
机器学习代写|流形学习代写manifold data learning代考|Global Information of Manifold
全局信息尚未用于流形学习,因为人们普遍认为全局信息可能会捕获在处理流形时应避免的不必要数据(如环境数据点)。
然而,最近的一些研究结果表明,以更受约束的方式探索全局信息对于流形学习可能是有用的。Costa 和 Hero 表明,可以在流形上使用测地线最小生成树 (GMST) 来估计流形的内在维度和内在熵 [4]。
Costa 和 Hero 在以下定理中表明,可以通过扩展 BHH 定理 [1] 来学习非线性流形的内在熵和内在维数,这是几何概率中的一个众所周知的结果。
定理:[BHH 定理到嵌入流形的推广:[4]] 让米是一个光滑的紧凑米维流形嵌入Rd通过微分同胚φ:Ω→米, 和Ω∈Rd. 认为2≤米≤d和0<C<米. 假设是1,是2,…是 iid 随机向量米具有共同的密度函数F关于 Lebesgue 测度μ米在米. 那么长度泛函吨CR米φ−1(是n)MST 跨越的φ−1(是n)几乎可以肯定地满足下面显示的方程:林n→∞吨C2米φ−1(是n)n(d−1)d=
在哪里一种=(米−C)/米, 并且总是介于0<一种<1,Ĵ是雅可比行列式,并且b米是一种常数取决于米.
基于上述定理,我们在整个数据集上使用 MST 作为全局信息的来源。有关更多详细信息,请参阅[4],更多背景信息参见 [15] 和 [13]。
GLEM 的基本原理非常简单。要最小化的目标函数由以下给出(它与 [2] 中使用的风格和符号相同):
∑一世,j|是(一世)−是(j)|22(在一世jññ+在一世j米小号吨) =tr(是吨大号(Gññ)是+是吨大号(G米小号吨)是) =tr(是吨(大号(Gññ)+大号(G米小号吨))是) =tr(是吨大号(Ĵ)是).
在哪里是(一世)=[是1(一世),…,是米(一世)]吨, 和米是嵌入的维度。在一世jññ和在一世j米小号吨分别是k-Nearest Neighbor图和MST图的加权矩阵。换句话说,我们有
精氨酸是吨是=一世是吨大号是这样是=[是1,是2,…,是米]和是(一世)是个米-维表示一世th 顶点。这个优化问题的解是广义特征值问题的特征向量
大号是=ΛD是
GLEM 算法在算法中描述1.

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。