如果你也在 怎样代写数据可视化data visualization这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
数据可视化是信息和数据的图形化表示,通过使用像图表、图形和地图这样的视觉元素,数据可视化工具提供了一种方便的方式来查看和理解数据的趋势、异常值和模式。
statistics-lab™ 为您的留学生涯保驾护航 在代写数据可视化data visualization方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写数据可视化data visualization方面经验极为丰富,各种代写数据可视化data visualization相关的作业也就用不着说。
我们提供的数据可视化data visualization及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|数据可视化作业代写data visualization代考|Color
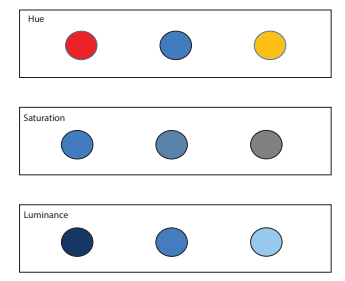
In terms of data visualization, color includes the attributes of hue, saturation, and luminance. Figure $3.6$ displays the difference between these aspects of color. Hue refers to what we typically think of as the basis of different colors, for example, red versus blue versus orange. In technical terms, the hue is defined by the position the light occupies on the visible light spectrum. Saturation refers to the intensity or purity of the color, which is defined as the amount of gray in the color. Luminance refers to the amount of black versus white within the color.
Hue, saturation, and luminance can each be used to draw the user’s attention to specific parts of a data visualization and to differentiate among values in a visualization. Using differences in hue in a data visualization creates bold, stark contracts while changing the saturation or luminance creates softer, less stark contrasts.
Color can be an extremely effective attribute to use to differentiate particular aspects of data in a visualization. However, one must be careful not to overuse color as it can become distracting in a visualization. It should also be noted that many people suffer from colorblindness, which affects their ability to differentiate between some colors.
统计代写|数据可视化作业代写data visualization代考|Form
Form includes the preattentive attributes of orientation, size, shape, length, and width. Each of these attributes can be used to call attention to a particular aspect of a data visualization. Figure $3.7$ shows an example for each of these form related preattentive attributes.
Orientation refers to the relative positioning of an object within a data visualization. It is a common preattentive attribute present in line graphs. Consider the chart in Figure $3.8$ that visualizes sales of a specific form of syringe that is used for administering insulin to diabetic patients in Europe and the United States. The difference in the orientation of these lines makes it easy for the audience to perceive that sales in Europe are increasing at a much faster rate than the United States for the years 2019 and 2020 .
Because the slope of the line for sales in Europe is much steeper than the slope of the line for sales in the United States, the orientation of these lines is different. Therefore, we quickly perceive that sales in Europe have increased much faster than in the United States since $2019 .$
Size refers to the relative amount of 2D space that an object occupies in a visualization. One must be careful with the use of size in data visualizations because humans are not particularly good at judging relative differences in the 2D sizes of objects. Consider Figure $3.9$, which shows a pair of squares and a pair of circles. Try to determine how much larger the bigger square and bigger circle are than their smaller counterparts.
Both the bigger square and bigger circle are nine times larger than their smaller counterparts in terms of area. Most people are not good at estimating this relative size difference, so we must be careful when using the attribute of size to convey information about relative amounts.
The difficulty most people have in estimating relative differences in $2 \mathrm{D}$ size is a major reason why the use of pie charts in a data visualization is generally not recommended.
There are often alternatives to a pie chart that do not rely as heavily on the attribute of size to convey relative differences in amounts.
Shape refers to the type of object used in a data visualization. Contrary to size and orientation, the preattentive attribute of shape does not usually convey a sense of quantitative amount. In a line graph, the orientation of a line (going up, staying flat, or going down) generally provides a sense of a quantitative change in amount. For size, most people assume that a larger object conveys a larger quantitative amount. In general, most shapes do not specifically correspond to certain quantitative amounts. Nevertheless, shape can be effectively used to draw attention in a visualization or as a way to group common items and distinguish between items from different groups.
Figure $3.10$ uses the attributes of color and shape to show how items are grouped. For example, suppose these 20 items represented 20 employees of a company. In Figure $3.10$ a we use the preattentive attribute of color to divide the items into three different groups, or categories: orange, blue, and black. For example, color could represent the type of educational degree the corresponding employee has earned. Orange could represent a business degree, blue could represent an engineering degree, and black could represent any other degree. In Figure $3.10 \mathrm{~b}$, we use the preattentive attribute of shape to divide the items into three groups: circle, square, and triangle. For example, shape could represent the highest educational degree level that the corresponding employee has earned. A circle could represent a bachelor’s degree, a triangle could represent a master’s degree, and black could represent a doctorate degree. In either case, the mind can quickly process these visualizations and divide the items into their distinct groups. Figure $3.10 \mathrm{c}$ uses both attributes, color and shape, to group items into nine groups-each combination of color (degree type) and shape (degree level). It requires a much higher cognitive load here to determine which items are in the same group. This illustrates why we have to be careful not to overuse combinations of preattentive attributes, or else we lose the ability for our mind to quickly recognize these.
统计代写|数据可视化作业代写data visualization代考|Length and Width
When we refer to the prealtentive attributes ol length and widh for datal visualization, we are generally referring to their use with lines, bars, or columns. Therefore, length refers to the horizontal, vertical, or diagonal distance of a line or bar/column while width refers to the thickness of the line or bar/column (see Figure 3.7). Length is useful for illustrating quantitative values because a longer line corresponds to a larger value. Length is used extensively in bar and column charts to visualize data. Because it is much easier to compare relative lengths than relative sizes, bar and column charts are often preferred to pie charts for visualizing data. Consider data on the number of accounts managed by eight account managers. Figure $3.11$ displays these same data as a pie chart (using size of pie pieces to indicate number of accounts and color to indicate the manager) and a bar chart (using length of bars to indicate number of accounts and labels on the vertical axis to indicate the manager).
It is much easier to see that the manager with the most accounts managed is Elijah and that Kate manages the second-most accounts from the bar chart in Figure $3.11 \mathrm{~b}$ than from the pie chart in Figure 3.11a. We could make the bar chart even easier to interpret by sorting the bars by their length with the longest bar on top and the shortest bar on the bottom by using the Excel Sort function as described in the following steps. The data appear in Figure 3.12.

数据可视化代写
统计代写|数据可视化作业代写data visualization代考|Color
在数据可视化方面,颜色包括色相、饱和度、亮度等属性。数字3.6显示颜色的这些方面之间的差异。色调是指我们通常认为的不同颜色的基础,例如,红色、蓝色和橙色。用技术术语来说,色调是由光在可见光谱中占据的位置定义的。饱和度是指颜色的强度或纯度,定义为颜色中的灰色量。亮度是指颜色中黑色与白色的量。
色调、饱和度和亮度均可用于将用户的注意力吸引到数据可视化的特定部分,并区分可视化中的值。在数据可视化中使用色调差异会创建大胆、鲜明的合同,而更改饱和度或亮度会创建更柔和、不那么鲜明的对比。
颜色是一种非常有效的属性,可用于区分可视化中数据的特定方面。但是,必须注意不要过度使用颜色,因为它会在可视化中分散注意力。还应该注意的是,许多人患有色盲,这会影响他们区分某些颜色的能力。
统计代写|数据可视化作业代写data visualization代考|Form
形式包括方向、大小、形状、长度和宽度等预先注意的属性。这些属性中的每一个都可用于引起对数据可视化特定方面的注意。数字3.7显示了这些与表单相关的前注意属性中的每一个的示例。
方向是指对象在数据可视化中的相对定位。它是折线图中常见的预注意属性。考虑图中的图表3.8可视化用于向欧洲和美国的糖尿病患者注射胰岛素的特定形式注射器的销售情况。这些线路方向的差异让观众很容易察觉到 2019 年和 2020 年欧洲的销售额增长速度远快于美国。
由于欧洲销售线的斜率比美国销售线的斜率大得多,因此这些线的方向不同。因此,我们很快发现,自那时以来,欧洲的销售额增长速度远快于美国2019.
大小是指对象在可视化中占据的 2D 空间的相对量。在数据可视化中使用大小时必须小心,因为人类并不特别擅长判断对象 2D 大小的相对差异。考虑图3.9,其中显示了一对正方形和一对圆形。尝试确定较大的正方形和较大的圆圈比较小的对应物大多少。
就面积而言,较大的正方形和较大的圆形都比较小的正方形大九倍。大多数人不擅长估计这种相对大小差异,所以我们在使用大小属性来传达有关相对数量的信息时必须小心。
大多数人在估计相对差异时遇到的困难2D大小是通常不建议在数据可视化中使用饼图的主要原因。
饼图通常有一些替代品,它们不那么依赖大小属性来传达数量的相对差异。
形状是指数据可视化中使用的对象类型。与大小和方向相反,形状的预先注意属性通常不能传达数量感。在折线图中,线的方向(上升、持平或下降)通常提供量的数量变化的感觉。对于尺寸,大多数人认为较大的物体代表较大的数量。一般来说,大多数形状并不具体对应于某些数量。然而,形状可以有效地用于在可视化中吸引注意力,或者作为对常见项目进行分组和区分来自不同组的项目的一种方式。
数字3.10使用颜色和形状的属性来显示项目是如何分组的。例如,假设这 20 个项目代表一家公司的 20 名员工。如图3.10a 我们使用颜色的 preattentive 属性将项目分为三个不同的组或类别:橙色、蓝色和黑色。例如,颜色可以代表相应员工获得的教育程度类型。橙色可以代表商业学位,蓝色可以代表工程学位,黑色可以代表任何其他学位。如图3.10 b,我们使用 shape 的 preattentive 属性将项目分为三组:圆形、方形和三角形。例如,形状可以代表相应员工获得的最高教育程度。圆形代表学士学位,三角形代表硕士学位,黑色代表博士学位。在任何一种情况下,大脑都可以快速处理这些可视化并将项目分成不同的组。数字3.10C使用颜色和形状这两种属性将项目分为九组——颜色(度数类型)和形状(度数级别)的每个组合。这里需要更高的认知负荷来确定哪些项目属于同一组。这说明了为什么我们必须小心不要过度使用前注意属性的组合,否则我们会失去大脑快速识别这些属性的能力。
统计代写|数据可视化作业代写data visualization代考|Length and Width
当我们提到用于数据可视化的前属性 ol 长度和宽度时,我们通常指的是它们与线、条或列的使用。因此,长度是指一条线或条/列的水平、垂直或对角线距离,而宽度是指线或条/列的粗细(见图 3.7)。长度对于说明定量值很有用,因为较长的线对应于较大的值。长度在条形图和柱形图中广泛用于可视化数据。因为比较相对长度比比较相对大小要容易得多,所以条形图和柱形图通常比饼图更适合用于可视化数据。考虑由八位客户经理管理的客户数量数据。数字3.11将这些相同的数据显示为饼图(使用饼图大小表示帐户数量,使用颜色表示经理)和条形图(使用条形长度表示帐户数量,并在垂直轴上使用标签表示经理)。
从图中的条形图中很容易看出,管理账户最多的经理是 Elijah,而 Kate 管理着第二多的账户3.11 b与图 3.11a 中的饼图相比。我们可以通过使用 Excel 排序功能按以下步骤中所述的 Excel 排序功能按长度对条形图进行排序,使条形图更易于解释,最长的条形图在顶部,最短的条形图在底部。数据如图 3.12 所示。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。统计代写|python代写代考
随机过程代考
在概率论概念中,随机过程是随机变量的集合。 若一随机系统的样本点是随机函数,则称此函数为样本函数,这一随机系统全部样本函数的集合是一个随机过程。 实际应用中,样本函数的一般定义在时间域或者空间域。 随机过程的实例如股票和汇率的波动、语音信号、视频信号、体温的变化,随机运动如布朗运动、随机徘徊等等。
贝叶斯方法代考
贝叶斯统计概念及数据分析表示使用概率陈述回答有关未知参数的研究问题以及统计范式。后验分布包括关于参数的先验分布,和基于观测数据提供关于参数的信息似然模型。根据选择的先验分布和似然模型,后验分布可以解析或近似,例如,马尔科夫链蒙特卡罗 (MCMC) 方法之一。贝叶斯统计概念及数据分析使用后验分布来形成模型参数的各种摘要,包括点估计,如后验平均值、中位数、百分位数和称为可信区间的区间估计。此外,所有关于模型参数的统计检验都可以表示为基于估计后验分布的概率报表。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
statistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
机器学习代写
随着AI的大潮到来,Machine Learning逐渐成为一个新的学习热点。同时与传统CS相比,Machine Learning在其他领域也有着广泛的应用,因此这门学科成为不仅折磨CS专业同学的“小恶魔”,也是折磨生物、化学、统计等其他学科留学生的“大魔王”。学习Machine learning的一大绊脚石在于使用语言众多,跨学科范围广,所以学习起来尤其困难。但是不管你在学习Machine Learning时遇到任何难题,StudyGate专业导师团队都能为你轻松解决。
多元统计分析代考
基础数据: $N$ 个样本, $P$ 个变量数的单样本,组成的横列的数据表
变量定性: 分类和顺序;变量定量:数值
数学公式的角度分为: 因变量与自变量
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。