如果你也在 怎样代写SPSS这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
SPSS主要用于数据管理、高级分析、多变量分析、商业智能。
statistics-lab™ 为您的留学生涯保驾护航 在代写SPSS方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写SPSS方面经验极为丰富,各种代写SPSS相关的作业也就用不着说。
我们提供的SPSS及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
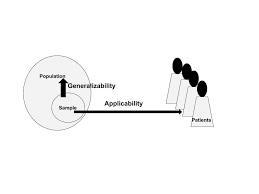
统计代写|SPSS代写代考|Generalizability and sampling adequacy
As we have alluded to so far in this chapter, one of the reasons that sampling, and sampling bias, are important is about generalizability. Usually, when a researcher conducts a quantitative study, they hope to have results that mean something for the population. In other words, researchers usually study samples to find things out about the population. When samples are too biased or too unrepresentative, the results may not generalize at all. That is, in a very biased sample, the results might only apply to that sample and be unlikely to ever occur in any other group. Generalizability, then, is often a goal of
quantitative work. Very few samples’ results would generalize to the entire population, but researchers should think about how far their results might generalize. One way to assess the generalizability of results is to evaluate sampling biases.
Another issue in generalizability is related to sample size. How many people comprise a sample affects multiple layers of quantitative analysis, including factors we will come to in future chapters like normality and homogeneity of variance. But the sample size also impacts generalizability. Very small samples are much less likely to be representative of the population. Even by pure chance in a random sample, smaller samples are more likely to be biased. As the sample size increases, it will likely become more representative. In fact, as the sample size increases, it gets closer and closer to the size of the population. As a general rule, there are some minimum sample sizes in quantitative research. We’ll return to these norms in future chapters. Most of our examples in this text will involve very small, imaginary samples to make it easier to track how the analyses work. But in general samples should have at least 30 people for a correlational or within-subjects design. When comparing two or more groups, the minimum should be at least 30 people per group (Gay et al., 2016). These are considered to be minimum sample sizes, and much larger samples might be appropriate in many cases, especially where there are multiple variables under analysis or the differences are likely to be small (Borg \& Gall, 1979).
统计代写|SPSS代写代考|LEVELS OF MEASUREMENT
The data we gather can be measured at several different levels. In the most basic sense, we think of variables as being either categorical or continuous. Categorical variables place people into groups, which might be groups with no meaningful order or groups that have a rank order to them. Continuous variables measure a quantity or amount, rather than a category. There are two types of categorical variables: nominal and ordinal. Likewise, there are two types of continuous variables: interval and ratio. For the purposes of the analyses discussed in this book, differentiating between interval and ratio data will not be important. However, below we introduce each level of measurement and provide some examples.
统计代写|SPSS代写代考|Nominal
Nominal data involve named categories. Nominal data cannot be meaningfully ordered. That is, they are categorical data with no meaningful numeric or rank-ordered values. For example, we might categorize participants based on things like gender, city of residence, race, or academic program. These categories do not have meaningful ordering or numbering within them-they are simply ways of categorizing participants. It is also important to note that all of these categories are also relatively arbitrary and rely on social constructions. Nominal data will often be coded numerically, even though the numbers assigned to each group are also arbitrary. For example, in collecting student gender, we might set 1 = woman, 2 = man, 3 = nonbinary/genderqueer, $4=$ an option not included in this list. There is no real logic to which group we assign the label of $1,2,3$, or 4 . In fact, it would make no difference if instead we labelled these groups $24,85,129$, and 72 . The numeric label simply marks which groups someone is in – it has no actual mathematical or ranking value. However, we will usually code groups numerically because software programs, such as jamovi, cannot analyze text data easily. So, we code group membership with numeric codes to make it easier to analyze later on. In another example, researchers in the United States often use racial categories that align to the federal Census categories. They do so in order to be able to compare their samples to the population for some region or even the entire country. So, they might code race as 1 = Black/African American, 2 = Asian American/Pacific Islander, 3 = Native American/Alaskan Native, $4=$ Hispanic/ Latinx, 5 = White. Again, the numbering of these categories is completely arbitrary and carries no real meaning. They could be numbered in any order and accomplish the same goal. Also notice that, although these racial categories are widely used, they are also problematic and leave many racial and ethnic groups out altogether. For most of the analyses covered in this text, nominal variables will be used to group participants in order to compare group means. Another example of a nominal variable would be experimental groups, where we might have $1=$ experimental condition and $0=$ control condition.
SPSS代写
统计代写|SPSS代写代考|GENERALIZABILITY AND SAMPLING ADEQUACY
正如我们在本章到目前为止所提到的,抽样和抽样偏差很重要的原因之一是关于泛化性。通常,当研究人员进行定量研究时,他们希望得到对人群有意义的结果。换句话说,研究人员通常会研究样本以了解有关人口的信息。当样本偏差太大或太不具代表性时,结果可能根本无法概括。也就是说,在一个非常有偏差的样本中,结果可能只适用于该样本,而不太可能出现在任何其他组中。因此,可概括性通常是
定量工作。很少有样本的结果可以推广到整个人群,但研究人员应该考虑他们的结果可以推广到什么程度。评估结果普遍性的一种方法是评估抽样偏差。
普遍性的另一个问题与样本量有关。一个样本中有多少人会影响多层定量分析,包括我们将在未来章节中讨论的因素,如正态性和方差同质性。但样本量也会影响普遍性。非常小的样本不太可能代表总体。即使在随机样本中纯属偶然,较小的样本也更有可能产生偏差。随着样本量的增加,它可能会变得更具代表性。事实上,随着样本量的增加,它越来越接近总体规模。作为一般规则,定量研究中有一些最小样本量。我们将在以后的章节中回到这些规范。我们在本文中的大多数示例将涉及非常小的,假想样本,以便更容易跟踪分析的工作方式。但一般而言,样本应该至少有 30 人用于相关或受试者内设计。在比较两组或更多组时,每组至少应有 30 人(Gay 等人,2016 年)。这些被认为是最小的样本量,并且在许多情况下更大的样本可能是合适的,特别是在分析中有多个变量或差异可能很小的情况下(Borg \& Gall, 1979)。
统计代写|SPSS代写代考|LEVELS OF MEASUREMENT
我们收集的数据可以在几个不同的层次上进行测量。在最基本的意义上,我们认为变量要么是分类的,要么是连续的。分类变量将人们分成组,这些组可能是没有有意义的顺序的组,也可能是对他们有等级顺序的组。连续变量测量数量或数量,而不是类别。有两种类型的分类变量:名义变量和有序变量。同样,有两种类型的连续变量:区间和比率。出于本书讨论的分析目的,区分区间数据和比率数据并不重要。但是,下面我们将介绍每个测量级别并提供一些示例。
统计代写|SPSS代写代考|Nominal
名义数据涉及命名类别。无法对标称数据进行有意义的排序。也就是说,它们是没有有意义的数字或排序值的分类数据。例如,我们可能会根据性别、居住城市、种族或学术课程等因素对参与者进行分类。这些类别没有有意义的排序或编号——它们只是对参与者进行分类的方式。同样重要的是要注意,所有这些类别也是相对武断的,并且依赖于社会结构。尽管分配给每个组的数字也是任意的,但标称数据通常会以数字方式编码。例如,在收集学生性别时,我们可以设置 1 = 女性,2 = 男性,3 = 非二元/性别酷儿,4=此列表中未包含的选项。我们将标签分配给哪个组没有真正的逻辑1,2,3, 或 4 . 事实上,如果我们给这些组贴上标签,那也没什么区别24,85,129, 和 72 . 数字标签只是标记某人所在的组 – 它没有实际的数学或排名值。但是,我们通常会以数字方式对组进行编码,因为 jamovi 等软件程序无法轻松分析文本数据。因此,我们使用数字代码对组成员身份进行编码,以便以后更容易分析。在另一个例子中,美国的研究人员经常使用与联邦人口普查类别一致的种族类别。他们这样做是为了能够将他们的样本与某些地区甚至整个国家的人口进行比较。因此,他们可能会将种族编码为 1 = 黑人/非裔美国人,2 = 亚裔美国人/太平洋岛民,3 = 美洲原住民/阿拉斯加原住民,4=西班牙裔/拉丁裔,5 = 白人。同样,这些类别的编号是完全任意的,没有实际意义。它们可以按任何顺序编号并实现相同的目标。另请注意,尽管这些种族类别被广泛使用,但它们也存在问题,并且将许多种族和族裔群体完全排除在外。对于本文中涵盖的大多数分析,名义变量将用于对参与者进行分组,以便比较组均值。名义变量的另一个例子是实验组,我们可能有1=实验条件和0=控制条件。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。统计代写|python代写代考
随机过程代考
在概率论概念中,随机过程是随机变量的集合。 若一随机系统的样本点是随机函数,则称此函数为样本函数,这一随机系统全部样本函数的集合是一个随机过程。 实际应用中,样本函数的一般定义在时间域或者空间域。 随机过程的实例如股票和汇率的波动、语音信号、视频信号、体温的变化,随机运动如布朗运动、随机徘徊等等。
贝叶斯方法代考
贝叶斯统计概念及数据分析表示使用概率陈述回答有关未知参数的研究问题以及统计范式。后验分布包括关于参数的先验分布,和基于观测数据提供关于参数的信息似然模型。根据选择的先验分布和似然模型,后验分布可以解析或近似,例如,马尔科夫链蒙特卡罗 (MCMC) 方法之一。贝叶斯统计概念及数据分析使用后验分布来形成模型参数的各种摘要,包括点估计,如后验平均值、中位数、百分位数和称为可信区间的区间估计。此外,所有关于模型参数的统计检验都可以表示为基于估计后验分布的概率报表。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
statistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
机器学习代写
随着AI的大潮到来,Machine Learning逐渐成为一个新的学习热点。同时与传统CS相比,Machine Learning在其他领域也有着广泛的应用,因此这门学科成为不仅折磨CS专业同学的“小恶魔”,也是折磨生物、化学、统计等其他学科留学生的“大魔王”。学习Machine learning的一大绊脚石在于使用语言众多,跨学科范围广,所以学习起来尤其困难。但是不管你在学习Machine Learning时遇到任何难题,StudyGate专业导师团队都能为你轻松解决。
多元统计分析代考
基础数据: $N$ 个样本, $P$ 个变量数的单样本,组成的横列的数据表
变量定性: 分类和顺序;变量定量:数值
数学公式的角度分为: 因变量与自变量
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。