如果你也在 怎样代写机器学习 machine learning这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
机器学习是一个致力于理解和建立 “学习 “方法的研究领域,也就是说,利用数据来提高某些任务的性能的方法。机器学习算法基于样本数据(称为训练数据)建立模型,以便在没有明确编程的情况下做出预测或决定。机器学习算法被广泛用于各种应用,如医学、电子邮件过滤、语音识别和计算机视觉,在这些应用中,开发传统算法来执行所需任务是困难的或不可行的。
statistics-lab™ 为您的留学生涯保驾护航 在代写机器学习 machine learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写机器学习 machine learning代写方面经验极为丰富,各种代写机器学习 machine learning相关的作业也就用不着说。
我们提供的机器学习 machine learning及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
计算机代写|机器学习代写machine learning代考|The Research Behind Interpretability
Several industries are witnessing an increasing trend of leveraging ML for high stake prediction applications, which deeply impacts human lives.
When automated algorithms make high-stake decisions, the problem of incorrect predictions becomes even more severe. To address this issue, explainable machine learning emerged as a field of study focusing on machine learning interpretability and shifting toward a more transparent AI. The main goal of this was to create a suite of interpretable models and methods that produce human-friendly explanations and maintain high predictive performance levels.
One of the entities in this field is the Defense Advanced Research Projects Agency (DARPA), funded by the US Department of Defense. It created the interpretability and explainability program that funds academic and military research at 11 US research laboratories. The program information states that the program aims to produce more explainable models while maintaining high predictive performance levels, enabling appropriate human trust, and understanding for better management of the emerging generation of artificially intelligent partners.
This is not the only example of public focus on AI and machine learning interpretability. In 2016, the White House Office of Science and Technology Policy (OSTP) released a report titled, “Preparing for the Future of Artificial Intelligence,” which states that AI systems are open, transparent, and understandable so that people can interrogate the assumptions and decisions behind the models’ decisions.
Also, the Association for Computing Machinery US Public Policy Council (USACM) released a “Statement on algorithmic transparency and accountability” in 2017. It is stated that explainability is one of the seven principles for algorithmic transparency and accountability. Then it is particularly important in public policy contexts.
Other countries have also made public the demand for AI and machine learning interpretability. One example is the draft version of the Dutch AI, which is utterly focused on explainable AI, stating the utmost importance of AI systems being accurate and able to explain how the system came to its decision.
计算机代写|机器学习代写machine learning代考|Machine Learning Interpretability Taxonomy
Interpretable machine learning techniques can generally be grouped into three categories.
- Pre-model interpretability uses interpretable techniques used before model building.
- Intrinsic interpretability uses explanations derived using the model structure.
- Post hoc interpretability uses explanations derived from methods outside the model structure generally run after the model has been built and predictions have been made using the model.
Pre-model interpretability is exploratory data analysis on a data set to understand the distribution of various features. It helps determine any relationships in different feature values and each feature with the dependent.
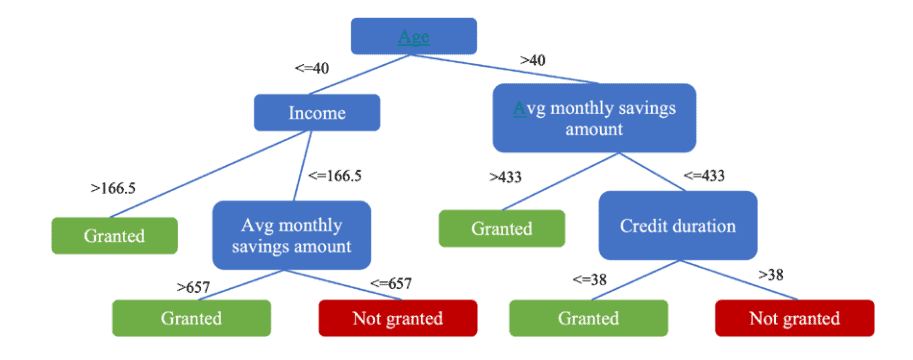
Intrinsic interpretability or explanations are computed using self-explanatory models that incorporate interpretability directly to their structures. The algorithms of this category include decision trees, rule-based models, linear models, and attention models. With the use of an intrinsic interpretable model, you might not achieve the same accuracy as black-box models; however, it becomes easy to understand the models’ working because of their inherent structure. Intrinsic interpretable models can further be divided into global methods and local methods.
Global interpretability means users can understand how the model works globally by inspecting the structures and parameters of a complex model. In contrast, local interpretability examines an individual prediction of a model locally, figuring out why the model makes its decision.
After fitting a model on the data, the data scientist then analyses it to understand the model results. The process of analyzing the model using the interpretability method to extract various types of information is called post hoc interpretability. There are several post hoc interpretability methods that can be used in different forms on top of various models to understand the model’s inner workings. Post hoc interpretability methods are implemented after the predictions are made from the model. The common types of input that go into these kinds of models involve training data, the black-box model itself, or prediction functions.
The diagram in Figure 3-2 shows how all interpretability models can be divided into different sections. Some sections focus on the s separations of different techniques, while some sections focus on model-related sections.
机器学习代考
计算机代写|机器学习代写machine learning代考|The Research Behind Interpretability
多个行业正在目睹利用 ML 进行高风险预测应用程序的增长趋势,这对人类生活产生了深远的影响。
当自动化算法做出高风险决策时,不正确预测的问题变得更加严重。为了解决这个问题,可解释的机器学习成为一个专注于机器学习可解释性并转向更透明的人工智能的研究领域。这样做的主要目标是创建一套可解释的模型和方法,以产生人性化的解释并保持高预测性能水平。
该领域的实体之一是由美国国防部资助的国防高级研究计划局 (DARPA)。它创建了可解释性和可解释性计划,资助 11 个美国研究实验室的学术和军事研究。该计划信息表明,该计划旨在产生更多可解释的模型,同时保持高预测性能水平,实现适当的人类信任和理解,以更好地管理新一代人工智能合作伙伴。
这并不是公众关注人工智能和机器学习可解释性的唯一例子。2016 年,白宫科技政策办公室 (OSTP) 发布了一份题为“为人工智能的未来做准备”的报告,其中指出人工智能系统是开放、透明和可理解的,以便人们可以质疑假设和模型决策背后的决策。
此外,计算机协会美国公共政策委员会(USACM)在 2017 年发布了一份“关于算法透明度和问责制的声明”。其中指出,可解释性是算法透明度和问责制的七项原则之一。然后它在公共政策环境中尤为重要。
其他国家也公开了对人工智能和机器学习可解释性的需求。一个例子是荷兰 AI 的草案版本,它完全专注于可解释的 AI,说明 AI 系统的准确性和能够解释系统如何做出决定的重要性。
计算机代写|机器学习代写machine learning代考|Machine Learning Interpretability Taxonomy
可解释的机器学习技术通常可以分为三类。
- 预模型可解释性使用模型构建之前使用的可解释技术。
- 内在可解释性使用从模型结构派生的解释。
- 事后可解释性使用从模型结构外部的方法派生的解释,这些方法通常在构建模型并使用模型进行预测后运行。
预模型可解释性是对数据集的探索性数据分析,以了解各种特征的分布。它有助于确定不同特征值之间的任何关系以及每个特征与依赖关系。
内在的可解释性或解释是使用不言自明的模型计算的,这些模型将可解释性直接结合到它们的结构中。此类算法包括决策树、基于规则的模型、线性模型和注意力模型。使用内在的可解释模型,您可能无法达到与黑盒模型相同的准确性;然而,由于模型的内在结构,理解模型的工作变得容易。内在可解释模型可以进一步分为全局方法和局部方法。
全局可解释性意味着用户可以通过检查复杂模型的结构和参数来了解模型如何在全局范围内工作。相比之下,局部可解释性在局部检查模型的个体预测,弄清楚模型做出决定的原因。
在对数据拟合模型后,数据科学家随后对其进行分析以了解模型结果。使用可解释性方法分析模型以提取各类信息的过程称为事后可解释性。有几种事后解释性方法可以在各种模型之上以不同的形式使用,以了解模型的内部工作原理。在根据模型做出预测后,实施事后可解释性方法。进入这些模型的常见输入类型包括训练数据、黑盒模型本身或预测函数。
图 3-2 中的图表显示了如何将所有可解释性模型划分为不同的部分。一些部分侧重于不同技术的分离,而一些部分侧重于与模型相关的部分。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。