澳洲代写|COMP3670|Introduction to Machine Learning机器学习入门 澳洲国立大学
statistics-labTM为您提供澳大利亚国立大学(The Australian National University)Introduction to Machine Learning机器学习入门澳洲代写代考和辅导服务!
课程介绍:
Essential foundations for any machine learning application are a basic statistical analysis of the data to be processed, a solid understanding of the mathematical foundations underpinning machine learning as well as the basic classes of learning/adaptation concepts. Those foundations are bundled in this single, introductory course to machine learning in preparation for deeper explorations into the topic, but also as a standalone unit.
| Detail | Information |
|---|---|
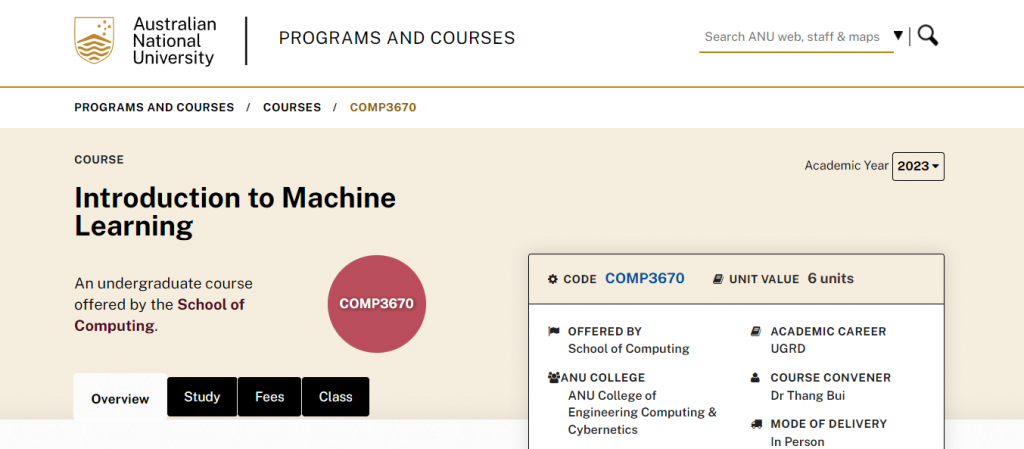
| Course Code | COMP3670 |
| Prerequisite | Not mentioned in the provided text |
| Academic Unit | School of Computing |
| ANU College | ANU College of Engineering Computing & Cybernetics |
| Course Subject | Computer Science |
| Course Convener | Dr Thang Bui |
| Units | 6 units |
Binary Classification二进制分类定义
Binary Classification is probably the most frequently studied problem in machine learning and it has led to a large number of important algorithmic and theoretic developments over the past century. In its simplest form it reduces to the question: given a pattern $x$ drawn from a domain $X$, estimate which value an associated binary random variable $y \in{ \pm 1}$ will assume. For instance, given pictures of apples and oranges, we might want to state whether the object in question is an apple or an orange. Equally well, we might want to predict whether a home owner might default on his loan, given income data, his credit history, or whether a given e-mail is spam or ham. The ability to solve this basic problem already allows us to address a large variety of practical settings.
There are many variants exist with regard to the protocol in which we are required to make our estimation:
二元分类可能是机器学习中最常被研究的问题,在过去的一个世纪里,它带来了大量重要的算法和理论发展。最简单的问题是:给定从一个领域 $X$ 中抽取的模式 $x$,估计与之相关的二进制随机变量 $y \in{ \pm 1}$ 将取哪个值。例如,给定苹果和橘子的图片,我们可能想知道相关物体是苹果还是橘子。同样,我们可能希望根据收入数据、信用记录或某封电子邮件是垃圾邮件还是火腿肠来预测房主是否会拖欠贷款。解决这一基本问题的能力已经让我们能够应对各种实际情况。
在我们需要进行估算的协议方面存在许多变体:
- We might see a sequence of $\left(x_i, y_i\right)$ pairs for which $y_i$ needs to be estimated in an instantaneous online fashion. This is commonly referred to as online learning.
- We might observe a collection $\mathbf{X}:=\left{x_1, \ldots x_m\right}$ and $\mathbf{Y}:=\left{y_1, \ldots y_m\right}$ of pairs $\left(x_i, y_i\right)$ which are then used to estimate $y$ for a (set of) so-far unseen $\mathbf{X}^{\prime}=\left{x_1^{\prime}, \ldots, x_{m^{\prime}}^{\prime}\right}$. This is commonly referred to as batch learning.
- We might be allowed to know $\mathbf{X}^{\prime}$ already at the time of constructing the model. This is commonly referred to as transduction.
- We might be allowed to choose $\mathbf{X}$ for the purpose of model building. This is known as active learning.
- We might not have full information about $\mathbf{X}$, e.g. some of the coordinates of the $x_i$ might be missing, leading to the problem of estimation with missing variables.
- The sets $\mathbf{X}$ and $\mathbf{X}^{\prime}$ might come from different data sources, leading to the problem of covariate shift correction.
- We might be given observations stemming from two problems at the same time with the side information that both problems are somehow related. This is known as co-training.
- Mistakes of estimation might be penalized differently depending on the type of error, e.g. when trying to distinguish diamonds from rocks a very asymmetric loss applies.
- 我们可能会看到一连串的 $/left(x_i, y_i\right)$ 对,其中的 $y_i$ 需要以即时在线的方式进行估计。这通常被称为在线学习。
- 我们可能会观察到一个集合 $\mathbf{X}:=\left{x_1, \ldots x_m\right}$ 和 $\mathbf{Y}: =\$left(x_i,y_i\right)$的成對 $left(x_i,y_i\right)$,然後用於估計(一組)至今未見的 $y$。这通常被称为批量学习。
- 在构建模型时,我们可能已经知道 $/mathbf{X}^{prime}$。这通常被称为转导。
- 我们可以选择 $\mathbf{X}$ 来构建模型。这就是所谓的主动学习。
- 我们可能没有关于 $\mathbf{X}$ 的全部信息,例如,$x_i$ 的某些坐标可能缺失,这就导致了缺失变量的估计问题。
- $\mathbf{X}$和$\mathbf{X}^{prime}$这两个集合可能来自不同的数据源,从而导致协变量偏移校正问题。
- 我们可能会同时得到来自两个问题的观测数据,而这两个问题在某种程度上是相关的。这就是所谓的共同训练。
- 估计错误可能会因错误类型的不同而受到不同的惩罚,例如,当试图区分钻石和岩石时,就会出现非常不对称的损失。
Multiclass Classification is the logical extension of binary classification. The main difference is that now y ∈ {1, . . . , n} may assume a range of different values. For instance, we might want to classify a document according to the language it was written in (English, French, German, Spanish,
Hindi, Japanese, Chinese, . . . ). See Figure 1.6 for an example. The main difference to before is that the cost of error may heavily depend on the type of error we make. For instance, in the problem of assessing the risk of cancer, it makes a significant difference whether we mis-classify an early stage of cancer as healthy (in which case the patient is likely to die) or as an advanced
stage of cancer (in which case the patient is likely to be inconvenienced from
overly aggressive treatment).
Structured Estimation goes beyond simple multiclass estimation by
assuming that the labels y have some additional structure which can be used
in the estimation process. For instance, y might be a path in an ontology,
when attempting to classify webpages, y might be a permutation, when
attempting to match objects, to perform collaborative filtering, or to rank
documents in a retrieval setting. Equally well, y might be an annotation of
a text, when performing named entity recognition. Each of those problems
has its own properties in terms of the set of y which we might consider
admissible, or how to search this space.
Regression is another prototypical application. Here the goal is to estimate a real-valued variable y ∈ R given a pattern x For
instance, we might want to estimate the value of a stock the next day, the
yield of a semiconductor fab given the current process, the iron content of
ore given mass spectroscopy measurements, or the heart rate of an athlete,
given accelerometer data. One of the key issues in which regression problems
differ from each other is the choice of a loss. For instance, when estimating
stock values our loss for a put option will be decidedly one-sided. On the
other hand, a hobby athlete might only care that our estimate of the heart
rate matches the actual on average.
多分类是二元分类的逻辑延伸。主要区别在于,现在 y ∈ {1, . , n} 可以有一系列不同的值。例如,我们可能想根据文档的语言(英语、法语、德语、西班牙语、印地语、日语、中文……)对其进行分类、
印地语、日语、中文……)。). 示例见图 1.6。与之前的主要区别在于,错误的代价可能在很大程度上取决于我们所犯的错误类型。例如,在评估癌症风险的问题中 在评估癌症风险的问题中,我们是将早期癌症错误地归类为健康癌症(在这种情况下,患者很可能会死亡),还是将晚期癌症错误地归类为健康癌症(在这种情况下,患者很可能会死亡),这两者之间的差别是非常大的。
癌症晚期(在这种情况下,病人很可能会因为过于积极的治疗而带来不便)。
过度积极的治疗带来不便)。
结构化估算超越了简单的多类估算,其方法是
假定标签 y 有一些额外的结构,可以在估计过程中使用。
在估计过程中使用。例如,y 可能是本体中的一条路径、
在尝试对网页进行分类时,y 可能是一个排列组合。
例如,在尝试对网页进行分类时,y 可能是本体中的一条路径;在尝试匹配对象、执行协同过滤或在检索设置中对文档进行排序时,y 可能是一种排列。
在检索设置中对文档进行排序。同样,在进行命名实体识别时,y 可以是文本的注释。
同样,在进行命名实体识别时,y 可能是文本的注释。这些问题中的每一个
都有其自身的特性,比如我们可能会认为 y 的集合
或如何搜索这个空间。
回归是另一个典型应用。这里的目标是在给定模式 x 的情况下估计实值变量 y∈R。
例如,我们可能想要估计某只股票第二天的价值、某个半导体制造厂的收益率、某只股票第二天的价值、某只股票第二天的收益率、某只股票第二天的收益率。
例如,我们可能希望根据当前的工艺流程估算出半导体工厂的产量,根据质谱测量结果估算出矿石中的铁含量。
或运动员的心率、
加速度计数据。回归问题的关键问题之一是
不同的关键问题之一是损失的选择。例如,在估算
例如,在估算股票价值时,我们对看跌期权的损失将是明显的单边损失。另一方面
另一方面,业余运动员可能只关心我们对心率的估计值与实际心率的平均值是否一致。
平均心率是否与实际相符。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。