机器学习代写|深度学习project代写deep learning代考|APPLICATION OF DEEP LEARNING IN RECOMMENDATION SYSTEM
如果你也在 怎样代写深度学习deep learning这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
深度学习是机器学习的一个子集,它本质上是一个具有三层或更多层的神经网络。这些神经网络试图模拟人脑的行为–尽管远未达到与之匹配的能力–允许它从大量数据中 “学习”。
statistics-lab™ 为您的留学生涯保驾护航 在代写深度学习deep learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写深度学习deep learning代写方面经验极为丰富,各种代写深度学习deep learning相关的作业也就用不着说。
我们提供的深度学习deep learning及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
机器学习代写|深度学习project代写deep learning代考|ABSTRACT
The advancement in the field of information technology in recent times has made the access of huge amounts of data very easy. There are a vast variety of products and services whose description is easily available along with their comments and reviews. Due to this overload of information [1], it becomes very difficult for the user to choose an appropriate product according to his requirements.
To deal with the above problems, recommendation systems are used. Recommendation Systems provide the users with personalized recommendations. There are many areas where recommendation system is being used, such as music, books, movies, shopping etc. Most of the online vendors have a recommendation engine already equipped. Recommendations are done on the basis of user’s previous items choice or the items preferred by similar user or on the basis of the description of item. Here the item refers to the product or services which is to be recommended. Recommendation system is classified into three parts based on their approach: [2] Content based, collaborative filtering and hybrid.
Recently, the use of artificial neural networks has become very popular in the problems which require complex computations and huge amount of input data. Deep learning is a part of ANN architectural models of deep neural network are efficiently built and trained. Deep neural networks have its applications in various fields such as speech recognition, image processing, object recognition, image processing, NLP tasks etc. Due to various advantages of deep learning, researchers have been encouraged to use its associated techniques in the field of recommendation system also.
Deep learning is being used successfully in recommendation system as well as many other fields in computer science and has shown significant improvements in the existing models. In 2007, a collaborative
filtering method for movie recommendation system was given by [3] which utilized the hierarchical model of deep learning. In 2015, [4] with the use of auto encoders, predicted the values which were missing in the user-item matrix.
The sparsity issue in recommendation system in collaborative filtering was addressed by [5].Various surveys have been done in the area of deep neural network based recommendation system. The state-of-theart survey for deep recommendation system has been done by [6]. In 2017 , a comprehensive review on deep learning based recommendation system has been done by [7]. The paper proposed the classifications on the basis of their structure that is neural network models and integration models.
This article is organized in various sections as follows. In the first section, introduction of recommendation and deep neural network based techniques are introduced. Section two consists of background and related terminologies. Section 3 describes the usage of various approaches of deep neural networks in the area of recommendation system and its classification.
机器学习代写|深度学习project代写deep learning代考|Recommendation System
A recommendation system is used for information filtering and outputs a list of specific products in a personalized manner. For examining how the two fields that are recommendation system and deep learning are integrated together, one should know the basics of both these fields. This section of the paper includes a brief description about the fundamental classifications and challenges of both the fields. First, there is an introduction of types of recommendation system and then the details about deep learning methods.
Various recommendation system approaches are evolved over time and applied in various applications.User finds to filter the huge amount of data available as important task, to find a useful, tailored and relevant content. The recommendations that are predicted by the recommendation System helps the users in taking a decision.
In a traditional recommendation system, the recommendations can be made in two different manners, i.e., predicting a particular item or preparing a ranking list of items for a particular user [8]. The recommendation model is categorized into Content based model [9], Collaborative filtering based model and hybrid recommendation framework [10].
1) Content based recommendation framework: In this model, the items which are same in content is searched. The profile of user is established on the basis of items on which the user is interested in. According to the profile generated, the recommendation system searches the database for the appropriate items using the descriptive attributes of the item. If we use this recommendation system [11] for an item which is newly added, then content based recommendation system works very efficiently. The problem with new inserted item is that it may not have any rating, but still the algorithm works since it uses descriptive information for recommendations. The limitation of this method is that it cannot recommend diverse range of products since the algorithm does not take the information from similar users.
2) Collaborative filtering recommendation systems: This recommendation system assumes that users’, who have previously preferred same items, would have same choice in future also. In this system, the recommendations are done on the basis of similar users’ pattern rather than descriptive features of items. A correlation among the users is determined, depending upon the choice of similar users, the items are recommended.
机器学习代写|深度学习project代写deep learning代考|Deep Learning Techniques
Deep learning is based on learning many layers of representations with the help of artificial neural networks, and is a part of machine learning. Deep learning has its applications in variety of fields like Computer vision, recognition of speech, natural language synthesis etc. The important factors which increase the importance of deep neural network as the state-of-the-art machine learning methods are as following:
Big data: As the amount of data increases, better representations are learnt by the deep learning model.
Computational power: The complex computations of the deep learning model is done using the GPU
In this section, there is a description of various deep learning models which are used in recommendation systems.
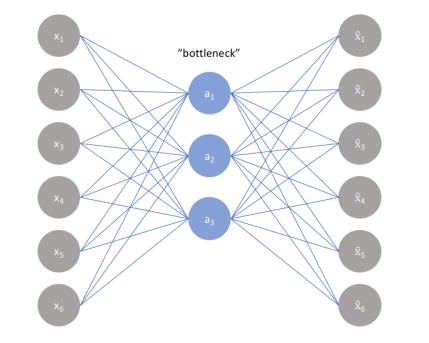
Autoencoder is an unsupervised learning technique in which neural networks are applied for the task of representation learning. Specifically, a neural network architecture is designed which imposes a bottleneck in the network which forces a compressed knowledge representation of the original input as shown in figure 1 . In autoencoder some representations from the encoded input are found by the training, so that the input can be restored back from these representations. Autoencoder have three layers arranged as the input, hidden and output layer. There are equivalent numbers of neurons in the input and output layer. The compressed representations are obtained from the hidden layer, and with the help of these representations, the first layer inputs are reconstructed at the output layer of autoencoder [13].
In the learning process, two mappings are used, with the help of encoder and decoder. An encoder is fully connected deep neural network which transforms the input into a latent space representation. Decoder is also having a similar structure as encoder and it is responsible for reconstructing the input back to the original form from the hidden layer outputs [14]. There are many variants of autoencoders such as sparse autoencoder, stacked autoencoder, denoising autoencoder and variational autoencoder etc. Data Compression, Image Denoising, Dimensionality Reduction, Feature Extraction, Image Generation and Image colorization are few important applications of autoencoders.
深度学习代写
机器学习代写|深度学习project代写deep learning代考|ABSTRACT
近年来,信息技术领域的进步使得大量数据的访问变得非常容易。有各种各样的产品和服务,它们的描述以及他们的评论和评论很容易获得。由于这种信息过载[1],用户很难根据自己的要求选择合适的产品。
为了解决上述问题,使用了推荐系统。推荐系统为用户提供个性化的推荐。推荐系统在很多领域都在使用,比如音乐、书籍、电影、购物等。大多数在线供应商已经配备了推荐引擎。推荐是根据用户以前的物品选择或相似用户喜欢的物品或根据物品的描述进行的。这里的项目是指要推荐的产品或服务。推荐系统根据其方法分为三个部分:[2] 基于内容、协同过滤和混合。
最近,人工神经网络的使用在需要复杂计算和大量输入数据的问题中变得非常流行。深度学习是深度神经网络的 ANN 架构模型的一部分,可以有效地构建和训练。深度神经网络在语音识别、图像处理、对象识别、图像处理、NLP 任务等各个领域都有其应用。由于深度学习的各种优势,鼓励研究人员在推荐系统领域使用其相关技术还。
深度学习已成功应用于推荐系统以及计算机科学的许多其他领域,并在现有模型中显示出显着的改进。2007 年,合作
电影推荐系统的过滤方法由[3]给出,它利用了深度学习的层次模型。2015 年,[4] 使用自动编码器,预测了用户项目矩阵中缺失的值。
[5] 解决了协同过滤中推荐系统的稀疏性问题。在基于深度神经网络的推荐系统领域进行了各种调查。深度推荐系统的现状调查已由 [6] 完成。2017 年,[7] 对基于深度学习的推荐系统进行了全面回顾。本文根据其结构即神经网络模型和集成模型提出了分类。
本文分为以下几个部分。在第一节中,介绍了推荐和基于深度神经网络的技术。第二部分由背景和相关术语组成。第 3 节描述了深度神经网络在推荐系统及其分类领域的各种方法的使用。
机器学习代写|深度学习project代写deep learning代考|Recommendation System
推荐系统用于信息过滤,并以个性化的方式输出特定产品的列表。要研究推荐系统和深度学习这两个领域是如何结合在一起的,我们应该了解这两个领域的基础知识。本文的这一部分简要描述了这两个领域的基本分类和挑战。首先介绍了推荐系统的类型,然后是深度学习方法的详细信息。
各种推荐系统方法随着时间的推移而发展并应用于各种应用程序。用户发现过滤大量可用数据作为重要任务,以找到有用的、量身定制的和相关的内容。推荐系统预测的推荐有助于用户做出决定。
在传统的推荐系统中,可以通过两种不同的方式进行推荐,即预测特定项目或为特定用户准备项目排名列表[8]。推荐模型分为基于内容的模型[9]、基于协同过滤的模型和混合推荐框架[10]。
1)基于内容的推荐框架:在该模型中,搜索内容相同的项目。基于用户感兴趣的项目建立用户档案。根据生成的档案,推荐系统使用项目的描述属性在数据库中搜索合适的项目。如果我们将这个推荐系统 [11] 用于新添加的项目,那么基于内容的推荐系统会非常有效地工作。新插入项目的问题在于它可能没有任何评级,但该算法仍然有效,因为它使用描述性信息进行推荐。这种方法的局限性在于它不能推荐多样化的产品,因为该算法没有从相似用户那里获取信息。
2) 协同过滤推荐系统:该推荐系统假设以前喜欢相同项目的用户将来也有相同的选择。在这个系统中,推荐是基于相似用户的模式而不是项目的描述性特征来完成的。确定用户之间的相关性,根据相似用户的选择,推荐项目。
机器学习代写|深度学习project代写deep learning代考|Deep Learning Techniques
深度学习是基于在人工神经网络的帮助下学习多层表示,是机器学习的一部分。深度学习在计算机视觉、语音识别、自然语言合成等多个领域都有应用。增加深度神经网络作为最先进的机器学习方法的重要性的重要因素如下:
大数据:随着数据量的增加,深度学习模型会学习到更好的表示。
计算能力:深度学习模型的复杂计算是使用 GPU 完成的
在本节中,描述了推荐系统中使用的各种深度学习模型。
自动编码器是一种无监督学习技术,其中神经网络用于表示学习的任务。具体来说,设计了一种神经网络架构,该架构在网络中施加了一个瓶颈,这迫使原始输入的压缩知识表示,如图 1 所示。在自动编码器中,来自编码输入的一些表示是通过训练找到的,因此可以从这些表示中恢复输入。自动编码器具有三层,分别为输入层、隐藏层和输出层。输入层和输出层的神经元数量相等。压缩表示是从隐藏层获得的,并且在这些表示的帮助下,第一层输入在自动编码器的输出层被重建 [13]。
在学习过程中,在编码器和解码器的帮助下,使用了两个映射。编码器是完全连接的深度神经网络,它将输入转换为潜在空间表示。解码器也具有与编码器类似的结构,它负责将输入从隐藏层输出 [14] 重建回原始形式。自编码器有许多变体,如稀疏自编码器、堆叠自编码器、去噪自编码器和变分自编码器等。数据压缩、图像去噪、降维、特征提取、图像生成和图像着色是自编码器的几个重要应用。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。