统计代写 | Statistical Learning and Decision Making代考| Inference in Bayesian Networks
如果你也在 怎样代写Statistical Learning and Decision Making这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
数据和预测模型是决策中一个越来越重要的部分。
statistics-lab™ 为您的留学生涯保驾护航 在代写Statistical Learning and Decision Making方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写Statistical Learning and Decision Making代写方面经验极为丰富,各种代写Statistical Learning and Decision Making相关的作业也就用不着说。
我们提供的Statistical Learning and Decision Making及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写 | Statistical Learning and Decision Making代考|Inference in Bayesian Networks
In inference problems, we want to infer a distribution over query variables given some observed evidence variables. The other nodes are referred to as hidden variables. We often refer to the distribution over the query variables given the evidence as a posterior distribution.
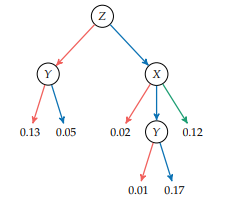
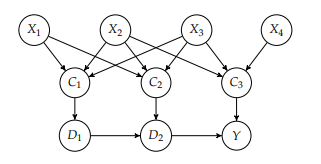
To illustrate the computations involved in inference, recall the Bayesian network from example $2.5$, the structure of which is reproduced in figure $3.1$. Suppose we have $B$ as a query variable and evidence $D=1$ and $C=1$. The inference task is to compute $P\left(b^{1} \mid d^{1}, c^{1}\right)$, which corresponds to computing the probability that we have a battery failure given an observed trajectory deviation and communication loss.
From the definition of conditional probability introduced in equation (2.22), we know
$$
P\left(b^{1} \mid d^{1}, c^{1}\right)=\frac{P\left(b^{1}, d^{1}, c^{1}\right)}{P\left(d^{1}, c^{1}\right)}
$$
To compute the numerator, we must use a process known as marginalization, where we sum out variables that are not involved, in this case $S$ and $E$ :
$$
P\left(b^{1}, d^{1}, c^{1}\right)=\sum_{s} \sum_{e} P\left(b^{1}, s, e, d^{1}, c^{1}\right)
$$
We know from the chain rule for Bayesian networks introduced in equation (2.31) that
$$
P\left(b^{1}, s, e, d^{1}, c^{1}\right)=P\left(b^{1}\right) P(s) P\left(e \mid b^{1}, s\right) P\left(d^{1} \mid e\right) P\left(c^{1} \mid e\right)
$$
All of the components on the right-hand side are specified in the conditional probability distributions associated with the nodes in the Bayesian network. We can compute the denominator in equation (3.1) using the same approach but with anditional summation over the values for $B$.
This process of using the definition of conditional probability, marginalization, and applying the chain rule can be used to perform exact inference in any Bayesian network. We can implement exact inference using factors. Recall that factors represent discrete multivariate distributions. We use the following three operations on factors to achieve this:
- We use the factor product (algorithm 3.1) to combine two factors to produce a larger factor whose scope is the combined scope of the input factors. If we have $\phi(X, Y)$ and $\psi(Y, Z)$, then $\phi \cdot \psi$ will be over $X, Y$, and $Z$ with $(\phi \cdot \psi)(x, y, z)=$ $\phi(x, y) \psi(y, z)$. The factor product is demonstrated in example $3.1$.
- We use factor marginalization (algorithm 3.2) to sum out a particular variable from the entire factor table, removing it from the resulting scope. Example $3.2$ illustrates this process.
- We use factor conditioning (algorithm 3.3) with respect to some evidence to remove any rows in the table inconsistent with that evidence. Example $3 \cdot 3$ demonstrates factor conditioning.
统计代写 | Statistical Learning and Decision Making代考|Inference in Naive Bayes Models
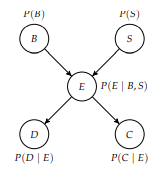
The previous section presented a general method for performing exact inference in any Bayesian network. This section discusses how this same method can be used to solve classification problems for a special kind of Bayesian network structure known as a naive Bayes model. This structure is shown in figure 3.2. An equivalent but more compact representation is shown in figure $3.3$ using a plate, shown as a rounded box. The $i=1: n$ in the bottom of the box specifies that the $i$ in the subscript of the variable name is repeated from 1 to $n$.
In the naive Bayes model, the class $C$ is the query variable, and the observed features $O_{1: n}$ are the evidence variables. The naive Bayes model is called naive because it assumes conditional independence between the evidence variables given the class. Using the notation introduced in section 2.6, we can say $\left(O_{i} \perp O_{j}\right.$ C) for all $i \neq j$. Of course, if these conditional independence assumptions do not hold, then we can add the necessary directed edges between the observed features.
We have to specify the prior $P(C)$ and the class-conditional distributions $P\left(O_{i} \mid C\right)$. As done in the previous section, we can apply the chain rule to compute the joint distribution:
$$
P\left(c, o_{1: n}\right)=P(c) \prod_{i=1}^{n} P\left(o_{i} \mid c\right)
$$
Our classification task involves computing the conditional probability $P\left(c \mid o_{1: n}\right)$. From the definition of conditional probability, we have
$$
P\left(c \mid o_{1: n}\right)=\frac{P\left(c, o_{1: n}\right)}{P\left(o_{1: n}\right)}
$$
We can compute the denominator by marginalizing the joint distribution:
$$
P\left(o_{1: n}\right)=\sum_{c} P\left(c, o_{1: n}\right)
$$
The denominator in equation (3.5) is not a function of $C$ and can therefore be treated as a constant. Hence, we can write
$$
P\left(c \mid o_{1: n}\right)=\kappa P\left(c, o_{1: n}\right)
$$
where $\kappa$ is a normalization constant such that $\sum_{c} P\left(c \mid o_{1: n}\right)=1$. We often drop $\kappa$ and write
$$
P\left(c \mid o_{1: n}\right) \propto P\left(c, o_{1 \Omega}\right)
$$
where the proportional to symbol $\propto$ is used to represent that the left-hand side is proportional to the right-hand side. Example $3.4$ illustrates how inference can be applied to classifying radar tracks.
We can use this method to infer a distribution over classes, but for many applications, we have to commit to a particular class. It is common to classify according to the class with the highest posterior probability, $\arg \max {c} P\left(c \mid o{1: n}\right)$. However, choosing a class is really a decision problem that often should take into account the consequences of misclassification. For example, if we are interested in using our classifier to filter out targets that are not aircraft for the purpose of air traffic control, then we can afford to occasionally let a few birds and other clutter tracks through our filter. However, we would want to avoid filtering out any real aircraft because that could lead to a collision. In this case, we would probably only want to classify a track as a bird if the posterior probability were close to $1 .$ Decision problems will be discussed in chapter $6 .$
统计代写 | Statistical Learning and Decision Making代考|Sum-Product Variable Elimination
A variety of methods can be used to perform efficient inference in more complicated Bayesian networks. One method is known as sum-product variable elimination, which interleaves eliminating hidden variables (summations) with applications of the chain rule (products). It is more efficient to marginalize variables out as early as possible to avoid generating large factors.
We will illustrate the variable elimination algorithm by computing the distribution $P\left(B \mid d^{1}, c^{1}\right)$ for the Bayesian network in figure $3.1$. The conditional probability distributions associated with the nodes in the network can be represented by the following factors:
$$
\phi_{1}(B), \phi_{2}(S), \phi_{3}(E, B, S), \phi_{4}(D, E), \phi_{5}(C, E)
$$
Because $D$ and $C$ are observed variables, the last two factors can be replaced with $\phi_{6}(E)$ and $\phi_{7}(E)$ by setting the evidence $D=1$ and $C=1$.
We then proceed by eliminating the hidden variables in sequence. Different strategies can be used for choosing an ordering, but for this example, we arbitrarily choose the ordering $E$ and then $S$. To eliminate $E$, we take the product of all the factors involving $E$ and then marginalize out $E$ to get a new factor:
$$
\phi_{8}(B, S)=\sum_{e} \phi_{3}(e, B, S) \phi_{6}(e) \phi_{7}(e)
$$
We can now discard $\phi_{3}, \phi_{6}$, and $\phi_{7}$ because all the information we need from them is contained in $\phi_{8}$.
Next, we eliminate $S$. Again, we gather all remaining factors that involve $S$ and marginalize out $S$ from the product of these factors:
$$
\phi_{9}(B)=\sum_{s} \phi_{2}(s) \phi_{8}(B, s)
$$
We discard $\phi_{2}$ and $\phi_{8}$, and are left with $\phi_{1}(B)$ and $\phi_{9}(B)$. Finally, we take the product of these two factors and normalize the result to obtain a factor representing $P\left(B \mid d^{1}, c^{1}\right) .$
The above procedure is equivalent to computing the following:
$$
P\left(B \mid d^{1}, c^{1}\right) \propto \phi_{1}(B) \sum_{s}\left(\phi_{2}(s) \sum_{e}\left(\phi_{3}\left(e \mid B_{t} s\right) \phi_{4}\left(d^{1} \mid e\right) \phi_{5}\left(c^{1} \mid e\right)\right)\right)
$$
This produces the same result as, but is more efficient than, the naive procedure of taking the product of all of the factors and then marginalizing:
$$
P\left(B \mid d^{1}, c^{1}\right) \propto \sum_{s} \sum_{e} \phi_{1}(B) \phi_{2}(s) \phi_{3}(e \mid B, s) \phi_{4}\left(d^{1} \mid e\right) \phi_{5}\left(c^{1} \mid e\right)
$$
统计代写
统计代写 | Statistical Learning and Decision Making代考|Inference in Bayesian Networks
在推理问题中,我们希望在给定一些观察到的证据变量的情况下推断查询变量的分布。其他节点称为隐藏变量。我们经常将给定证据的查询变量上的分布称为后验分布。
为了说明推理中涉及的计算,请从示例中回顾贝叶斯网络2.5,其结构如图所示3.1. 假设我们有乙作为查询变量和证据D=1和C=1. 推理任务是计算磷(b1∣d1,C1),这对应于在给定观察到的轨迹偏差和通信丢失的情况下计算我们发生电池故障的概率。
由式(2.22)中引入的条件概率的定义,我们知道
磷(b1∣d1,C1)=磷(b1,d1,C1)磷(d1,C1)
为了计算分子,我们必须使用称为边缘化的过程,在这种情况下,我们将不涉及的变量相加小号和和 :
磷(b1,d1,C1)=∑s∑和磷(b1,s,和,d1,C1)
我们从等式(2.31)中引入的贝叶斯网络的链式法则知道
磷(b1,s,和,d1,C1)=磷(b1)磷(s)磷(和∣b1,s)磷(d1∣和)磷(C1∣和)
右侧的所有组件都在与贝叶斯网络中的节点相关的条件概率分布中指定。我们可以使用相同的方法计算等式(3.1)中的分母,但对乙.
这个使用条件概率定义、边缘化和应用链式规则的过程可用于在任何贝叶斯网络中执行精确推理。我们可以使用因子来实现精确推理。回想一下,因子代表离散的多元分布。我们对因子使用以下三个操作来实现这一点:
- 我们使用因子乘积(算法 3.1)将两个因子组合起来产生一个更大的因子,其范围是输入因子的组合范围。如果我们有φ(X,是)和ψ(是,从), 然后φ⋅ψ将会结束X,是, 和从和(φ⋅ψ)(X,是,和)= φ(X,是)ψ(是,和). 因子积在例子中演示3.1.
- 我们使用因子边缘化(算法 3.2)从整个因子表中总结出特定变量,将其从结果范围中删除。例子3.2说明了这个过程。
- 我们针对某些证据使用因子条件(算法 3.3)来删除表中与该证据不一致的任何行。例子3⋅3演示因子调节。
统计代写 | Statistical Learning and Decision Making代考|Inference in Naive Bayes Models
上一节介绍了在任何贝叶斯网络中执行精确推理的通用方法。本节讨论如何使用相同的方法解决一种特殊的贝叶斯网络结构(称为朴素贝叶斯模型)的分类问题。这种结构如图 3.2 所示。等效但更紧凑的表示如图所示3.3使用盘子,显示为圆形框。这一世=1:n在框的底部指定一世在变量名的下标从1到重复n.
在朴素贝叶斯模型中,类C是查询变量,观察到的特征这1:n是证据变量。朴素贝叶斯模型被称为朴素,因为它假设给定类的证据变量之间的条件独立。使用第 2.6 节中介绍的符号,我们可以说(这一世⊥这jC) 为所有人一世≠j. 当然,如果这些条件独立性假设不成立,那么我们可以在观察到的特征之间添加必要的有向边。
我们必须指定先验磷(C)和类条件分布磷(这一世∣C). 如上一节所述,我们可以应用链式法则来计算联合分布:
磷(C,这1:n)=磷(C)∏一世=1n磷(这一世∣C)
我们的分类任务涉及计算条件概率磷(C∣这1:n). 根据条件概率的定义,我们有
磷(C∣这1:n)=磷(C,这1:n)磷(这1:n)
我们可以通过边缘化联合分布来计算分母:
磷(这1:n)=∑C磷(C,这1:n)
等式 (3.5) 中的分母不是C因此可以被视为一个常数。因此,我们可以写
磷(C∣这1:n)=ķ磷(C,这1:n)
在哪里ķ是一个归一化常数,使得∑C磷(C∣这1:n)=1. 我们经常掉线ķ和写
磷(C∣这1:n)∝磷(C,这1Ω)
其中与符号成比例∝用来表示左边与右边成正比。例子3.4说明了如何将推理应用于对雷达轨迹进行分类。
我们可以使用这种方法来推断类的分布,但是对于许多应用程序,我们必须提交到特定的类。通常根据后验概率最高的类别进行分类,参数最大限度C磷(C∣这1:n). 然而,选择一个类别确实是一个决策问题,通常应该考虑错误分类的后果。例如,如果我们有兴趣使用我们的分类器来过滤掉不是飞机的目标以进行空中交通管制,那么我们可以偶尔让一些鸟类和其他杂波轨迹通过我们的过滤器。但是,我们希望避免过滤掉任何真实的飞机,因为这可能会导致碰撞。在这种情况下,如果后验概率接近于1.决策问题将在本章讨论6.
统计代写 | Statistical Learning and Decision Making代考|Sum-Product Variable Elimination
可以使用多种方法在更复杂的贝叶斯网络中执行有效的推理。一种方法称为和积变量消除,它将消除隐藏变量(求和)与链式法则(积)的应用交错。尽早将变量边缘化以避免产生较大的因子更为有效。
我们将通过计算分布来说明变量消除算法磷(乙∣d1,C1)对于图中的贝叶斯网络3.1. 与网络中的节点相关的条件概率分布可以由以下因素表示:
φ1(乙),φ2(小号),φ3(和,乙,小号),φ4(D,和),φ5(C,和)
因为D和C是观察变量,最后两个因子可以替换为φ6(和)和φ7(和)通过设置证据D=1和C=1.
然后我们依次消除隐藏变量。可以使用不同的策略来选择排序,但是对于这个例子,我们任意选择排序和进而小号. 消除和, 我们取所有涉及的因素的乘积和然后边缘化和得到一个新的因素:
φ8(乙,小号)=∑和φ3(和,乙,小号)φ6(和)φ7(和)
我们现在可以丢弃φ3,φ6, 和φ7因为我们需要从他们那里得到的所有信息都包含在φ8.
接下来,我们消除小号. 再次,我们收集了所有涉及的剩余因素小号并边缘化小号从这些因素的产物:
φ9(乙)=∑sφ2(s)φ8(乙,s)
我们丢弃φ2和φ8, 并留下φ1(乙)和φ9(乙). 最后,我们取这两个因子的乘积,并对结果进行归一化,得到一个因子代表磷(乙∣d1,C1).
上述过程等价于计算以下内容:
磷(乙∣d1,C1)∝φ1(乙)∑s(φ2(s)∑和(φ3(和∣乙吨s)φ4(d1∣和)φ5(C1∣和)))
这产生了相同的结果,但比取所有因素的乘积然后边缘化的天真的过程更有效:
磷(乙∣d1,C1)∝∑s∑和φ1(乙)φ2(s)φ3(和∣乙,s)φ4(d1∣和)φ5(C1∣和)

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。