统计代写|描述统计学代写Descriptive statistics代考|Structure and Nature of Socio-Economic Data: The Aggregates
如果你也在 怎样代写描述统计学Descriptive statistics这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
描述性统计是对给定数据集进行总结的简短描述性系数,它可以是整个人口的代表,也可以是人口的样本。描述性统计被细分为中心趋势的测量和可变性(扩散)的测量。中心趋势的测量包括平均数、中位数和模式,而变异性的测量包括标准差、方差、最小和最大变量、峰度和偏度。
statistics-lab™ 为您的留学生涯保驾护航 在代写描述统计学Descriptive statistics方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写描述统计学Descriptive statistics代写方面经验极为丰富,各种代写描述统计学Descriptive statistics相关的作业也就用不着说。
我们提供的描述统计学Descriptive statistics及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|描述统计学代写Descriptive statistics代考|Surveying the ‘Real-Life-Objects’
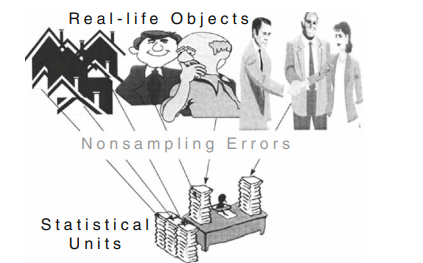
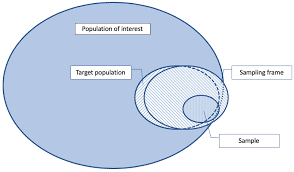
The process which transforms the ‘real-life-objects’ into ‘statistical-counting-units’ usually is the statistical survey. It can be a census, a sample, or some administrative listing that exists for other purposes but is made available to statistics.
Known is the population census. There are other, less known economic census operations: census of agriculture, of mining, manufacturing, whole-sale-retail establishments, and service industries. Even less known is the US census of governments, in which the local governments in the US are the real-life-objects. Because a census is a costly, major operation that requires a legal basis, a professional staff and big budget allocations, it is carried out only at 5 or 10 year intervals, and the different censuses are scheduled at different times because of the limited administrative capacity of census bureaus.
Another matter are the abundant sample surveys. Unless they are undertaken by a public or private professional sampling organization, they seldom serve a serious statistical purpose, but are used as a pretext to draw attention to a new product or some political cause.
Statistical theory has spent much thought and effort on improving the sample design in selecting the real-life-objects and managing the inevitable (mathematical) sampling error. As already mentioned, sampling theory and inference has dominated the discussion of statistics at the expense of nearly everything else.
This statistical process extracts from the rich reality of the existing ‘real-lifeobjects a simplified – and often distorted – sketch of it on a questionnaire or other means of recording. It is a reduction process that is not reversible: The real-life object, e.g. a human person, cannot be reconstructed from a questionnaire, regardless of how much detail it contains and how conscientiously it has been filled out. Furthermore, once recorded, each ‘statistical-counting-unit’ starts its own existence, separate from, and independent of that of the real-life object. Even if the latter should disappear completely, the ‘statistical-counting-unit’ remains, as a lasting testimony to the former’s existence. When tabulated, it survives even the destruction of the original record, on a questionnaire, punch-card, magnetic tape, CD or other device.
Statistical surveys record the real-life-objects in isolation from their socio-economic context. Usually real-life-objects of one kind are enumerated together, such as the dairy farms located in a country in a census of agriculture. Different types of real-life-objects are surveyed at different times, by different agencies, usually according to different criteria and definitions. No integral census has yet been accomplished that would report together human beings, factories, farms, mines, wholesale and retail establishments, banks and other service establishments, with their relevant characteristics. This inability to survey the entire society and its activities together, at the same time, results in discrepancies and variations in the data that have nothing to do with chance occurrences in the economy, but result from the truncation of socio-economic phenomena through the statistical process
统计代写|描述统计学代写Descriptive statistics代考|The ‘Statistical-Counting-Units’
It is interesting to consider the differences between “measurement” in the natural sciences and the corresponding statistical activity in the social sciences. In the natural sciences these measurements are the result of observations by objective especially trained observers, like in the bio sciences, so to speak from the outside of the thing to be measured. In the socio-economic setting the person providing the information e.g. in a population survey, really is the “object” to be observed. That selfreported information from many different informants of varying competence and intelligence is collected by survey takers, who themselves often are insufficiently prepared for that task, acting mostly as mail carriers, not like the observers in the natural sciences. The truthfulness and accuracy of such information depends on the cooperation of these interviewees, a matter that cannot be guaranteed, despite existing laws that require it. Neither their honesty nor the accuracy of their memory can be guaranteed. That is a fundamental, important difference between socio-economic statistical data and the measurement data in the natural sciences.
Statistical data have been variously classified. The distinction in ‘Punkt- and Streckenmassen’15 (point- and line masses), for example, is based on the length of life of the real-life-objects: some real-life-objects are perceived as being points in time, of short duration. Others last long, occupying a ‘Strecke’ that is, a considerable stretch of time. But every real-life-object has a certain duration. Considering its life span as point-like and short, or as long lasting, is a relative matter. Moreover, this distinction ignores the fact, that we do not deal with the real-life-objects themselves but with the ‘statistical-counting-units’ which are, by their nature, points in time and space, regardless of the length of life of the real-life object.
Another distinction in ‘Bestands- and Bewegungsmassen’ – inventories of a mass of stationary real-life-objects and masses of moving real-life-objects that are not stationary – is based on the spurious distinction between existence-units which are real-life objects that remain in their location without moving, and motion-units, that is, real-life objects that are on the move, without a fixed relation to a place in a geographic region. That obscures the fact, that every ‘statistical-counting-unit’ is a static record, fixed in a certain time and location, regardless of whether a real-lifeobject is static or dynamic. ${ }^{16}$
A distinction could be made between different types of ‘statistical-countingunits’ according to the occasion of their registration:
- Real-life-objects are contacted by mail, telephone or personal visit by a concerted effort to record them, and approached at a certain point in time as in a census or sample survey, or
- A government or private institution records the real-life object on the occasion of some event that triggers a registration, such as a beginning of something, a change of its characteristics, or its termination, carried out for other than statistical purposes. Typical is the registration of the birth of a child, the issue of a building permit for an addition to an existing building or for a new building, the registration of the bankruptcy of a firm (death), or the periodic re-registration of motor vehicles. In most of these instances the registration is requested by law,is carried out as a continuing operation, often for the purpose of taxation, not originally for statistical purposes.
统计代写|描述统计学代写Descriptive statistics代考|The Tri-Dimensional Frame of an Aggregate
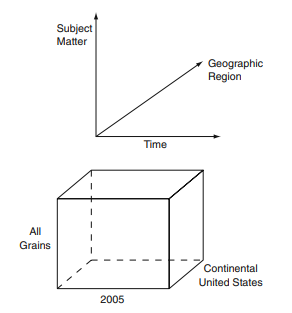
Socio-economic phenomena deal not only with a subject-matter aspect but also with a time and a regional-geographic aspect. The real-life-objects, and their corresponding ‘statistical-counting-units’ that portray those phenomena, partake in those three aspects that can be conveniently visualized as the three perpendicular vectors or dimensions of a coordinate system. This means that every aggregate ${ }^{1}$ that deals with socio-economic phenomena can be understood as occupying a tri-dimensional space like in a Cartesian coordinate system (Fig. 3.1).
The subject-matter dimension can be presented on the vertical vector of a statistical aggregate, or on any other of the vectors, if so preferred. The sub-divisions of the subject-matter, e.g. the major groupings of the classification of economic activities, can be indicated in linear form by corresponding tick-marks. ${ }^{2}$
For the social sciences the development of phenomena over time is of great interest. Time, therefore, should be marked on the second vector of that – still empty – Cartesian space, facing the observer, using the customary subdivisions of the calendar (months, quarters, semesters).
On the third, geographic vector, the administrative regions are plotted as a onedimensional sequence. Regional districts, reduced to linear form, are projected on the geographic vector. Figure $3.2$ shows the tri-dimensional frame of a statistical aggregate before the ‘statistical-counting-units’ are placed into it. One could imagine this empty space framed by the three vectors to look like an empty fish tank with its three dimensions.
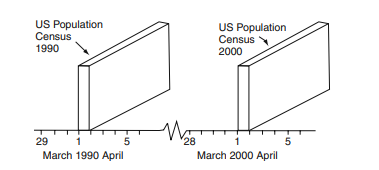
It is important to recognize that these three dimensions are present in all statistical data. This is easily overlooked, because data published in tabular form usually present only two of these three dimensions, either the subject-matter and time, or the subject-matter and geographic-territorial-dimension. This is true as much for aggregates as it is for other data-materials that are derived from aggregates.
When the time dimension is small, like in a census or inventory, the tri-dimensional character of a statistical aggregate shrinks to a seemingly two-dimensional sheet and is easily overlooked. Yet, like a sheet of paper that, regardless how thin it may be, still has a thickness that becomes evident when e.g. 500 sheets of such thin papers are packaged as a ream. In the case of a survey, the time dimension of the resulting data consists of those few hours or days – in a census of a big country that may be many months – needed to accomplish the field work, capturing a specific socio-economic phenomenon at that particular point in time. It may take that long to locate the respective ‘real-life-objects,’ to interview or canvass them and forward the result to a central location, an office, to produce the ‘statistical-counting-units’. The placement of the resulting aggregates on the time vector, Fig. 3.3, is important, because it allows to connect them to other statistical and non-statistical materials. ${ }^{3}$
描述统计学代写
统计代写|描述统计学代写Descriptive statistics代考|Surveying the ‘Real-Life-Objects’
将“现实生活对象”转化为“统计计数单位”的过程通常是统计调查。它可以是为其他目的而存在但可供统计使用的人口普查、样本或某些行政清单。
众所周知的是人口普查。还有其他鲜为人知的经济普查活动:农业普查、矿业普查、制造业普查、批发零售企业和服务业普查。更鲜为人知的是美国政府普查,其中美国的地方政府是现实生活中的对象。由于人口普查是一项成本高昂的大型活动,需要有法律依据、专业人员和大笔预算拨款,因此仅每隔 5 年或 10 年进行一次,而且由于行政能力有限,不同的人口普查安排在不同的时间进行人口普查局。
另一件事是丰富的抽样调查。除非它们由公共或私人专业抽样组织进行,否则它们很少用于严肃的统计目的,而是被用作引起人们对新产品或某些政治原因的关注的借口。
统计理论在改进样本设计以选择现实生活对象和管理不可避免的(数学)抽样误差方面花费了很多心思和精力。如前所述,抽样理论和推理几乎以牺牲其他一切为代价,主导了统计学的讨论。
这个统计过程从现有的“现实生活对象”的丰富现实中提取了一个简化的——通常是扭曲的——在问卷或其他记录方式上的草图。这是一个不可逆的还原过程:现实生活中的对象,例如一个人,无论它包含多少细节以及填写得多么认真,都无法从问卷中重建。此外,一旦记录下来,每个“统计单位”就开始其自身的存在,独立于现实生活对象的存在。即使后者完全消失,“统计单位”仍然存在,作为前者存在的持久证明。制成表格时,即使原始记录在问卷、穿孔卡、磁带、CD 或其他设备上被破坏,它也能幸存下来。
统计调查记录了脱离其社会经济背景的现实生活对象。通常将一种现实生活中的对象列举在一起,例如农业普查中位于某个国家的奶牛场。不同类型的现实生活对象在不同时间由不同机构进行调查,通常根据不同的标准和定义。尚未完成将人类、工厂、农场、矿山、批发和零售机构、银行和其他服务机构及其相关特征一起报告的完整普查。无法同时调查整个社会及其活动,导致数据的差异和变化与经济中的偶然事件无关,
统计代写|描述统计学代写Descriptive statistics代考|The ‘Statistical-Counting-Units’
考虑自然科学中的“测量”与社会科学中相应的统计活动之间的差异是很有趣的。在自然科学中,这些测量是客观的、特别受过训练的观察者的观察结果,就像在生物科学中一样,可以说是从被测量的事物的外部。在社会经济环境中,提供信息的人,例如在人口调查中,确实是要观察的“对象”。来自许多不同能力和智力的不同线人的自我报告信息是由调查人员收集的,他们自己往往没有为这项任务做好充分的准备,主要充当邮递员,不像自然科学中的观察者。此类信息的真实性和准确性取决于这些受访者的合作,尽管现行法律要求,但无法保证这一点。既不能保证他们的诚实,也不能保证他们记忆的准确性。这是社会经济统计数据与自然科学中的测量数据之间的一个根本的、重要的区别。
统计数据已进行了各种分类。例如,“Punkt- and Streckenmassen”15(点和线质量)中的区别是基于现实生活对象的寿命长度:一些现实生活对象被认为是时间点,持续时间短。其他人持续很长时间,占据了“Strecke”,即相当长的一段时间。但是每个现实生活中的对象都有一定的持续时间。将其寿命视为点状且短暂或持久,是相对的问题。此外,这种区别忽略了这样一个事实,即我们处理的不是现实生活中的对象本身,而是“统计单位”,它们本质上是时间和空间上的点,与生命的长短无关现实生活中的对象。
“Bestands-and Bewegungsmassen”中的另一个区别——大量静止的现实生活对象和大量非静止的移动现实生活对象的清单——是基于现实生活中的存在单位之间的虚假区别保持在其位置而不移动的对象,以及运动单元,即移动中的真实对象,与地理区域中的位置没有固定关系。这掩盖了这样一个事实,即每个“统计计数单元”都是静态记录,固定在某个时间和地点,无论现实生活中的对象是静态的还是动态的。16
根据注册的场合,可以区分不同类型的“统计单位”:
- 现实生活中的对象通过邮件、电话或个人访问进行联系,共同努力记录它们,并在某个时间点(如在人口普查或抽样调查中)接近,或
- 政府或私人机构在某些触发注册的事件之际记录现实生活中的对象,例如出于统计目的以外的目的进行的某事的开始、其特征的变化或终止。典型的例子是孩子的出生登记、为现有建筑物增建或新建建筑物的建筑许可证的签发、公司破产(死亡)的登记或汽车的定期重新登记汽车。在大多数情况下,注册是法律要求的,是作为持续经营进行的,通常是出于税收目的,而不是最初用于统计目的。
统计代写|描述统计学代写Descriptive statistics代考|The Tri-Dimensional Frame of an Aggregate
社会经济现象不仅涉及主题方面,还涉及时间和区域地理方面。现实生活中的对象,以及它们对应的描绘这些现象的“统计计数单位”,参与这三个方面,这些方面可以方便地可视化为坐标系的三个垂直向量或维度。这意味着每个聚合1处理社会经济现象可以理解为在笛卡尔坐标系中占据三维空间(图 3.1)。
主题维度可以呈现在统计聚合的垂直向量上,或任何其他向量上,如果愿意的话。主题的细分,例如经济活动分类的主要分组,可以用相应的勾号以线性形式表示。2
对于社会科学来说,现象随时间的发展是非常有趣的。因此,时间应该标记在第二个向量上——仍然是空的——笛卡尔空间,面向观察者,使用日历的惯常细分(月、季度、学期)。
在第三个地理向量上,行政区域被绘制为一维序列。简化为线性形式的区域区域被投影到地理矢量上。数字3.2显示了在“统计计数单位”放入其中之前的统计聚合的三维框架。可以想象这个由三个向量构成的空白空间看起来像一个具有三个维度的空鱼缸。
重要的是要认识到这三个维度存在于所有统计数据中。这很容易被忽视,因为以表格形式发布的数据通常只呈现这三个维度中的两个,要么是主题和时间,要么是主题和地理区域维度。这对于聚合和从聚合中派生的其他数据材料同样适用。
当时间维度很小时,例如在人口普查或清单中,统计聚合的三维特征缩小为看似二维的表,很容易被忽视。然而,就像一张纸,无论它有多薄,当将例如 500 张这样的薄纸包装成令时,仍然具有明显的厚度。在调查的情况下,结果数据的时间维度包括完成实地工作所需的几个小时或几天——在一个大国的人口普查中,可能需要几个月的时间——捕捉特定的社会经济现象。那个特定的时间点。可能需要很长时间才能找到相应的“现实生活对象”,采访或调查它们并将结果转发到中心位置,办公室,以产生“统计单位”。3

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。