统计代写|非参数统计代写Nonparametric Statistics代考|STA104
如果你也在 怎样代写非参数统计Nonparametric Statistics这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
非参数统计指的是一种统计方法,其中不假定数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
statistics-lab™ 为您的留学生涯保驾护航 在代写非参数统计Nonparametric Statistics方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写非参数统计Nonparametric Statistics代写方面经验极为丰富,各种代写非参数统计Nonparametric Statistics相关的作业也就用不着说。
我们提供的非参数统计Nonparametric Statistics及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|非参数统计代写Nonparametric Statistics代考|Binomial Distribution
A simple Bernoulli random variable $Y$ is dichotomous with $P(Y=1)=p$ and $P(Y=0)=1-p$ for some $0 \leq p \leq 1$. It is denoted as $Y \sim \operatorname{Ber}(p)$. Suppose an experiment consists of $n$ independent trials $\left(Y_1, \ldots, Y_n\right)$ in which two outcomes are possible (e.g. success or failure), with $P$ (success) $=P(Y=1)=p$ for each trial. If $X=x$ is defined as the number of successes (out of $n$ ), then $X=Y_1+Y_2+\cdots+Y_n$, and there are $\left(\begin{array}{l}n \ x\end{array}\right)$ arrangements of $x$ successes and $n-x$ failures, each having the same probability $p^x(1-p)^{n-x} . X$ is a binomial random variable with PMF:
$$
p_X(x)=\left(\begin{array}{l}
n \
x
\end{array}\right) p^x(1-p)^{n-x}, \quad x=0,1, \ldots, n .
$$
This is denoted by $X \sim \operatorname{Bin}(n, p)$. From the moment generating function $m_X(t)=$ $\left(p e^t+(1-p)\right)^n$, we obtain $\mu=\mathbb{E} X=n p$ and $\sigma^2=\mathbb{V a r} X=n p(1-p)$.
The cumulative distribution for a binomial random variable is not simplified beyond the sum; i.e. $F(x)=\sum_{i \leq x} p_X(i)$. However, interval probabilities can be computed in $\mathrm{R}$ using pbinom $(\mathrm{x}, \mathrm{n}, \mathrm{p})$, which computes the CDF at value $x$. The PMF is also computed in $R$ using dbinom $(x, n, p)$.
Random events characterized by counting the number of independent trials until a specific event occurs will have a geometric distribution. As such, the geometric is a special case of negative binomial for $k=1$ called the geometric distribution. Random variable $X$ has geometric $\mathcal{G}(p)$ distribution if its PMF is
$$
p_X(x)=p(1-p)^x, \quad x=0,1,2, \ldots
$$
If $X$ has geometric $\mathcal{G}(p)$ distribution, its expected value is $\mathbb{E} X=(1-p) / p$ and variance $\operatorname{Var} X=(1-p) / p^2$.
The geometric random variable can be considered as the discrete analog to the (continuous) exponential random variable because it possesses a “memoryless” property. That is, if we condition on $X \geq m$ for some nonnegative integer $m$, then for $n \geq m, P(X \geq n \mid X \geq m)=P(X \geq n-m)$.
R commands for geometric CDF, PDF, quantile, and a random number are pgeom, dgeom, qgeom, and rgeom.
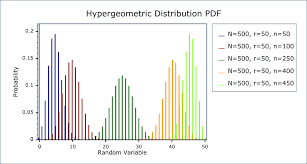
统计代写|非参数统计代写Nonparametric Statistics代考|Hypergeometric Distribution
The hypergeometric distribution is a natural byproduct of counting principles. Suppose a box contains $m$ balls, $k$ of which are white and $m-k$ of which are gold. Suppose we randomly select and remove $n$ balls from the box without replacement, so that when we finish, there are only $m-n$ balls left. If $X$ is the number of white balls chosen (without replacement) from $n$, then
$$
p_X(x)=\frac{\left(\begin{array}{l}
k \
x
\end{array}\right)\left(\begin{array}{c}
m-k \
n-x
\end{array}\right)}{\left(\begin{array}{l}
m \
n
\end{array}\right)}, \quad x \in{0,1, \ldots, \min {n, k}} .
$$
This PMF can be deduced with counting rules. There are $\left(\begin{array}{c}m \ n\end{array}\right)$ different ways of selecting the $n$ balls from a box of $m$. From these (each equally likely), there are $\left(\begin{array}{l}k \ x\end{array}\right)$ ways of selecting $x$ white balls from the $k$ white balls in the box and similarly $\left(\begin{array}{c}m-k \ n-x\end{array}\right)$ ways of choosing the gold balls.
It can be shown that the mean and variance for the hypergeometric distribution are, respectively,
$$
\mathbb{E}(X)-\mu-\frac{n k}{m} \quad \text { and } \quad \operatorname{Var}(X)-\sigma^2-\left(\frac{n k}{m}\right)\left(\frac{m-k}{m}\right)\left(\frac{m-n}{m-1}\right) .
$$
$\mathrm{R}$ commands for hypergeometric $\mathrm{CDF}, \mathrm{PDF}$, quantile, and a random number are phyper, dhyper, qhyper, and rhyper.
Example 2.1 Games such as poker based on a deal of $x$ cards from a deck of $m$ cards resemble the hypergeometric distribution. With the hypergeometric PMF
$$
p_X(x)=\frac{\left(\begin{array}{l}
k \
x
\end{array}\right)\left(\begin{array}{l}
m-k \
n-x
\end{array}\right)}{\left(\begin{array}{l}
m \
n
\end{array}\right)}
$$
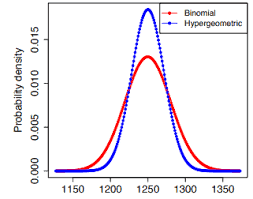
if $k \rightarrow \infty$ and $m \rightarrow \infty$ in such a way that $k / m \rightarrow p$ for some $0<p<1$, then (2.2) converges to the binomial probability
$$
\left(\begin{array}{l}
n \
x
\end{array}\right) p^x(1-p)^{n-x} .
$$
To a gambler, this results makes card-counting a futile effort if the casino uses multiple card packs in a game of 21 or blackjack. The player’s advantage in such games relies on the hypergeometric distribution’s without replacement properties of the card deal, which slowly disappear with multiple decks. The game eventually resembles a with replacement counting problem, which is characterized by the binomial distribution.
非参数统计代考
统计代写|非参数统计代写Nonparametric Statistics代考|Binomial Distribution
一个简单的伯努利随机变量 $Y$ 与 $P(Y=1)=p$ 和 $P(Y=0)=1-p$ 对于一些 $0 \leq p \leq 1$. 它表示为 $Y \sim \operatorname{Ber}(p)$. 假设一个实验包括 $n$ 独立试验 $\left(Y_1, \ldots, Y_n\right)$ 其中有两种可能的结果(例如成功或失败), 其中 $P$ (成功) $=P(Y=1)=p$ 对于每个试验。如果 $X=x$ 被定义为成功的次数(出于 $n$ ),然后 $X=Y_1+Y_2+\cdots+Y_n$ ,并且有 $(n x)$ 的安排 $x$ 成功和 $n-x$ 失败,每个都有相同的概率 $p^x(1-p)^{n-x} . X$ 是具有 PMF 的二项式随机变量:
$$
p_X(x)=(n x) p^x(1-p)^{n-x}, \quad x=0,1, \ldots, n .
$$
这表示为 $X \sim \operatorname{Bin}(n, p)$. 从时刻生成函数 $m_X(t)=\left(p e^t+(1-p)\right)^n$ ,我们获得 $\mu=\mathbb{E} X=n p$ 和 $\sigma^2=\mathbb{V a r} X=n p(1-p)$
二项式随机变量的男积分布不会简化为超出总和; $\mid E F(x)=\sum_{i \leq x} p_X(i)$. 然而,区间概率可以计算为 R使用 pbinom $(\mathrm{x}, \mathrm{n}, \mathrm{p})$ ,它计算值的 CDF $x$. PMF 也计算在 $R$ 使用 $\operatorname{dbinom}(x, n, p)$.
以计算独立试验的次数为特征的随机事件,直到特定事件发生将具有几何分布。因此,几何是负二项式的 特例 $k=1$ 称为几何分布。随机变量 $X$ 有几何 $\mathcal{G}(p)$ 如果它的 PMF 是分布
$$
p_X(x)=p(1-p)^x, \quad x=0,1,2, \ldots
$$
如果 $X$ 有几何 $\mathcal{G}(p)$ 分布,其期望值为 $\mathbb{E} X=(1-p) / p$ 和方差 $\operatorname{Var} X=(1-p) / p^2$.
几何随机变量可以被认为是 (连续) 指数随机变量的离散模拟,因为它具有“无记忆”特性。也就是说,如 果我们条件 $X \geq m$ 对于一些非负整数 $m$ ,那么对于 $n \geq m, P(X \geq n \mid X \geq m)=P(X \geq n-m)$
用于几何 CDF、PDF、分位数和随机数的 R 命令是 pgeom、dgeom、 qgeom 和 rgeom。
统计代写|非参数统计代写Nonparametric Statistics代考|Hypergeometric Distribution
超几何分布是计数原理的自然副产品。假设一个蒀子包含 $m$ 球, $k$ 其中有白色和 $m-k$ 其中有黄金。假设 我们随机选择并删除 $n$ 盒子里的球没有更换,所以当我们完成时,只有 $m-n$ 剩下的球。如果 $X$ 是从中选 择 (没有替换) 的白球数 $n$ ,然后
$$
p_X(x)=\frac{(k x)(m-k n-x)}{(m n)}, \quad x \in 0,1, \ldots, \min n, k .
$$
这个 PMF 可以用计数规则推导出来。有 $(m n)$ 不同的选择方式 $n$ 从一盒球 $m$. 从这些(每一个可能性均 等) 中,有 $(k x)$ 选择方式 $x$ 白球从 $k$ 孟子里的白球和类似的 $(m-k n-x)$ 选择金球的方法。
可以证明超几何分布的均值和方差分别为
$$
\mathbb{E}(X)-\mu-\frac{n k}{m} \quad \text { and } \quad \operatorname{Var}(X)-\sigma^2-\left(\frac{n k}{m}\right)\left(\frac{m-k}{m}\right)\left(\frac{m-n}{m-1}\right) .
$$
R超几何命令CDF,PDF、分位数和随机数是 phyper、dhyper、qhyper 和 rhyper。
示例 $2.1$ 基于交易的扑克牌游戏 $x$ 一副牌中的牌 $m$ 卡片类似于超几何分布。使用超几何 PMF
$$
p_X(x)=\frac{(k x)(m-k n-x)}{(m n)}
$$
如果 $k \rightarrow \infty$ 和 $m \rightarrow \infty$ 以这样的方式 $k / m \rightarrow p$ 对于一些 $0<p<1$, 那么 (2.2) 收敛于二项式概率
$$
(n x) p^x(1-p)^{n-x} \text {. }
$$
对于赌徒来说,如果奢场在 21 点或 21 点游戏中使用多个纸牌包,则此结果会使算牌变得徒劳。玩家在此 类游戏中的优势依赖于纸牌交易的无替代属性的超几何分布,这些属性会随着多副牌慢慢消失。该游戏最 终类似于具有替换计数问题,其特征在于二项分布。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。