如果你也在 怎样代写SLAM这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
同步定位和测绘(SLAM)是构建或更新一个未知环境的地图,同时跟踪一个代理人在其中的位置的计算问题。虽然这最初似乎是一个鸡生蛋蛋生鸡的问题,但有几种已知的算法可以解决这个问题,至少是近似解决,在某些环境下是可行的。流行的近似解决方法包括粒子过滤器、扩展卡尔曼过滤器、协方差交叉和GraphSLAM。SLAM算法是基于计算几何和计算机视觉的概念,并被用于机器人导航、机器人测绘和虚拟现实或增强现实的里程测量。
statistics-lab™ 为您的留学生涯保驾护航 在代写SLAM方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写SLAM代写方面经验极为丰富,各种代写SLAM相关的作业也就用不着说。
我们提供的SLAM及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
机器人代写|SLAM代写机器人导航代考|FastSLAM with Unknown Data Association
The biggest limitation of the FastSLAM algorithm described thus far is the assumption that the data associations $n^{t}$ are known. In practice, this is rarely the case. This section extends the FastSLAM algorithm to domains in which the mapping between observations and landmarks is not known [57]. The classical solution to the data association problem in SLAM is to chose $n_{t}$ such that it maximizes the likelihood of the sensor measurement $z_{t}$ given all available data [18].
$$
\hat{n}{t}=\underset{n{t}}{\operatorname{argmax}} p\left(z_{t} \mid n_{t}, \hat{n}^{t-1}, s^{t}, z^{t-1}, u^{t}\right)
$$
The term $p\left(z_{t} \mid n_{t}, \hat{n}^{t-1}, s^{t}, z^{t-1}, u^{t}\right)$ is referred to as a likelihood, and this approach is an example of a maximum likelihood (ML) estimator. ML data association is also called “nearest neighbor” data association, interpreting the negative log likelihood as a distance function. For Gaussians, the negative log likelihood is Mahalanobis distance, and the estimator selects data associations by minimizing this Mahalanobis distance.
In the EKF-based SLAM approaches described in Chapter 2, a single data association is chosen for the entire filter. As a result, these algorithms tend to be brittle to failures in data association. A single data association error can induce significant errors in the map, which in turn cause new data association errors, often with fatal consequences. A better understanding of how uncertainty in the SLAM posterior generates data association ambiguity will demonstrate how simple data association heuristics often fail.
机器人代写|SLAM代写机器人导航代考|Data Association Uncertainty
Two factors contribute to uncertainty in the SLAM posterior: measurement noise and motion noise. As measurement noise increases, the distributions of possible observations of every landmark become more uncertain. If measurement noise is sufficiently high, the distributions of observations from nearby landmarks will begin to overlap substantially. This overlap leads to ambiguity
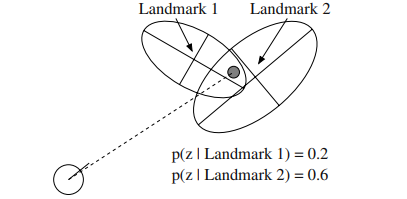
in the identity of the landmarks. We will refer to data association ambiguity caused by measurement noise as measurement ambiguity. An example of measurement ambiguity is shown in Figure 3.7. The two ellipses depict the range of probable observations from two different landmarks. The observation, shown as an black circle, plausibly could have come from either landmark.
Attributing an observation to the wrong landmark due to measurement ambiguity will increase the error of the map and robot pose, but its impact will be relatively minor. Since the observation could have been generated by either landmark with high probability, the effect of the observation on the landmark positions and the robot pose will be small. The covariance of one landmark will be slightly overestimated, while the covariance of the second will be slightly underestimated. If multiple observations are incorporated per control, a data association mistake due to measurement ambiguity of one observation will have relatively little impact on the data association decisions for the other observations.
Ambiguity in data association caused by motion noise can have much more severe consequences on estimation accuracy. Higher motion noise will lead to higher pose uncertainty after incorporating a control. If this pose uncertainty is high enough, assuming different robot poses in this distribution will imply drastically different ML data association hypotheses for the subsequent observations. This motion ambiguity, shown in Figure $3.8$, is easily induced if there is significant rotational error in the robot’s motion. Moreover, if multiple observations are incorporated per control, the pose of the robot will correlate the data association decisions of all of the observations. If the SLAM algorithm chooses the wrong data association for a single observation due to motion ambiguity, the rest of the data associations also will be wrong with high probability.
机器人代写|SLAM代写机器人导航代考|Per-Particle Data Association
Unlike most EKF-based SLAM algorithms, FastSLAM takes a multi-hypothesis approach to the data association problem. Each particle represents a different hypothesized path of the robot, so data association decisions can be made on a per-particle basis. Particles that pick the correct data association will receive high weights because they explain the observations well. Particles that pick wrong associations will receive low weights and be removed in a future resampling step.
Per-particle data association has several important advantages over standard ML data association. First, it factors robot pose uncertainty out of the data association problem. Since motion ambiguity is the more severe form of data association ambiguity, conditioning the data association decisions on hypothesized robot paths seems like a logical choice. Given the scenario in Figure 3.8, some of the particles would draw new robot poses consistent with data association hypothesis on the left, while others would draw poses consistent with the data association hypothesis on the right.
Doing data association on a per-particle basis also makes the data association problem easier. In the EKF, the uncertainty of a landmark position is due to both uncertainty in the pose of the robot and measurement error. In FastSLAM, uncertainty of the robot pose is represented by the entire particle set. The landmark filters in a single particle are not affected by motion noise because they are conditioned on a specific robot path. This is especially useful if the robot has noisy motion and an accurate sensor.
Another consequence of per-particle data association is implicit, delayeddecision making. At any given time, some fraction of the particles will receive plausible, yet wrong, data associations. In the future, the robot may receive a new observation that clearly refutes these previous assignments. At this point, the particles with wrong data associations will receive low weight and likely be removed from the filter. As a result of this process, the effect of a wrong data association decision made in the past can be removed from the filter. Moreover, no heuristics are needed in order to remove incorrect old associations from the filter. This is done in a statistically valid manner, simply as a consequence of the resampling step.
SLAM代写
机器人代写|SLAM代写机器人导航代考|FastSLAM with Unknown Data Association
迄今为止描述的 FastSLAM 算法的最大限制是假设数据关联n吨是已知的。在实践中,这种情况很少见。本节将 FastSLAM 算法扩展到观察值和地标之间的映射未知的领域 [57]。SLAM中数据关联问题的经典解决方案是选择n吨使其最大化传感器测量的可能性和吨给定所有可用数据[18]。
n^吨=最大参数n吨p(和吨∣n吨,n^吨−1,s吨,和吨−1,在吨)
术语p(和吨∣n吨,n^吨−1,s吨,和吨−1,在吨)被称为似然性,这种方法是最大似然(ML)估计器的一个例子。ML 数据关联也称为“最近邻”数据关联,将负对数似然解释为距离函数。对于高斯,负对数似然是马氏距离,估计器通过最小化这个马氏距离来选择数据关联。
在第 2 章描述的基于 EKF 的 SLAM 方法中,为整个过滤器选择单个数据关联。因此,这些算法往往会因数据关联失败而变得脆弱。单个数据关联错误可能会在地图中引发重大错误,进而导致新的数据关联错误,通常会带来致命的后果。更好地理解 SLAM 后验中的不确定性如何产生数据关联模糊性将证明简单的数据关联启发式方法经常失败。
机器人代写|SLAM代写机器人导航代考|Data Association Uncertainty
有两个因素会导致 SLAM 后验的不确定性:测量噪声和运动噪声。随着测量噪声的增加,每个地标的可能观测值的分布变得更加不确定。如果测量噪声足够高,来自附近地标的观测分布将开始大量重叠。这种重叠导致歧义
在地标的身份中。我们将由测量噪声引起的数据关联模糊度称为测量模糊度。图 3.7 显示了测量模糊度的一个示例。这两个椭圆描绘了来自两个不同地标的可能观测值的范围。显示为黑色圆圈的观察结果很可能来自任一地标。
由于测量模糊而将观察归因于错误的地标会增加地图和机器人位姿的误差,但其影响相对较小。由于观测可能是由任一界标产生的概率很高,因此观测对界标位置和机器人姿态的影响将很小。一个地标的协方差会被略微高估,而第二个地标的协方差会被略微低估。如果每个控制包含多个观察,则由于一个观察的测量模糊性导致的数据关联错误对其他观察的数据关联决策的影响相对较小。
由运动噪声引起的数据关联模糊会对估计精度产生更严重的影响。结合控制后,更高的运动噪声将导致更高的姿势不确定性。如果此姿势不确定性足够高,则假设此分布中的不同机器人姿势将意味着后续观察的 ML 数据关联假设大不相同。这种运动模糊,如图3.8, 如果机器人运动中存在明显的旋转误差,则很容易引起。此外,如果每个控件包含多个观测值,机器人的姿势将关联所有观测值的数据关联决策。如果 SLAM 算法由于运动模糊而为单个观察选择了错误的数据关联,那么其余数据关联也很有可能是错误的。
机器人代写|SLAM代写机器人导航代考|Per-Particle Data Association
与大多数基于 EKF 的 SLAM 算法不同,FastSLAM 对数据关联问题采用多假设方法。每个粒子代表机器人的不同假设路径,因此可以在每个粒子的基础上做出数据关联决策。选择正确数据关联的粒子将获得高权重,因为它们很好地解释了观察结果。选择错误关联的粒子将获得较低的权重,并在未来的重采样步骤中被移除。
与标准 ML 数据关联相比,每粒子数据关联具有几个重要优势。首先,它将机器人姿态不确定性排除在数据关联问题之外。由于运动模糊是数据关联模糊的更严重形式,因此根据假设的机器人路径调整数据关联决策似乎是一个合乎逻辑的选择。给定图 3.8 中的场景,一些粒子将绘制与左侧数据关联假设一致的新机器人姿态,而其他粒子将绘制与右侧数据关联假设一致的姿态。
在每个粒子的基础上进行数据关联也使数据关联问题更容易。在 EKF 中,地标位置的不确定性是由于机器人位姿的不确定性和测量误差造成的。在 FastSLAM 中,机器人姿态的不确定性由整个粒子集表示。单个粒子中的界标滤波器不受运动噪声的影响,因为它们以特定的机器人路径为条件。如果机器人有嘈杂的运动和准确的传感器,这将特别有用。
每粒子数据关联的另一个结果是隐含的、延迟的决策制定。在任何给定时间,一部分粒子都会收到似是而非的数据关联。将来,机器人可能会收到一个新的观察结果,该观察结果清楚地反驳了这些先前的任务。此时,具有错误数据关联的粒子将获得较低的权重,并可能从过滤器中移除。作为这个过程的结果,过去做出的错误数据关联决策的影响可以从过滤器中移除。此外,不需要启发式方法来从过滤器中删除不正确的旧关联。这是以统计上有效的方式完成的,只是作为重采样步骤的结果。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。