如果你也在 怎样代写流形学习manifold data learning这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
流形学习是机器学习的一个流行且快速发展的子领域,它基于一个假设,即一个人的观察数据位于嵌入高维空间的低维流形上。本文介绍了流形学习的数学观点,深入探讨了核学习、谱图理论和微分几何的交叉点。重点放在图和流形之间的显著相互作用上,这构成了流形正则化技术的广泛使用的基础。
statistics-lab™ 为您的留学生涯保驾护航 在代写流形学习manifold data learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写流形学习manifold data learning代写方面经验极为丰富,各种代写流形学习manifold data learning相关的作业也就用不着说。
我们提供的流形学习manifold data learning及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
机器学习代写|流形学习代写manifold data learning代考|Diffusion Maps
The basic idea of Diffusion MaPs (Nadler, Lafon, Coifman, and Kevrekidis, 2005; Coifman and Lafon, 2006) uses a Markov chain constructed over a graph of the data points, followed by an eigenanalysis of the probability transition matrix of the Markov chain. As with the other algorithms in this Section, there are three steps in this algorithm, with the first and second steps the same as for Laplacian eigenmaps. Although a nearest-neighbor search (Step 1) was not explicitly considered in the above papers on diffusion maps as a means of constructing the graph (Step 2), a nearest-neighbor search is included in software packages for computing diffusion maps. For an example in astronomy of a diffusion map incorporating a nearest-neighbor search, see Freeman, Newman, Lee, Richards, and Schafer (2009).
- Nearest-Neighbor Search. Fix an integer $K$ or an $\epsilon>0$. Define a $K$-neighborhood $N_{i}^{K}$ or an $\epsilon$-neighborhood $N_{i}^{e}$ of the point $\mathbf{x}{i}$ as in Step 1 of Laplacian eigenmaps. In general, let $N{i}$ denote the neighborhood of $\mathbf{x}_{i}$.Pairwise Adjacency Matrix. The $n$ data points $\left{\mathbf{x}{i}\right}$ in $\Re^{r}$ can be regarded as a graph $\mathcal{G}=\mathcal{G}(\mathcal{V}, \mathcal{E})$ with the data points playing the role of vertices $\mathcal{V}=\left{\mathbf{x}{1}, \ldots, \mathbf{x}{n}\right}$, and the set of edges $\mathcal{E}$ are the connection strengths (or weights), $w\left(\mathbf{x}{i}, \mathbf{x}{j}\right)$, between pairs of adjacent vertices, $$ w{i j}=w\left(\mathbf{x}{i}, \mathbf{x}{j}\right)= \begin{cases}\exp \left{-\frac{\left|\mathbf{x}{i}-\mathbf{x}{i}\right|^{2}}{2 \sigma^{2}}\right}, & \text { if } \mathbf{x}{j} \in N{i} \ 0, & \text { otherwise. }\end{cases}
- $$
- This is a Gaussian kernel with width $\sigma$; however, other kernels may be used. Kernels such as (1.52) ensure that the closer two points are to each other, the larger the value of $w$. For convenience in exposition, we will suppress the fact that the elements of most of the matrices depend upon the value of $\sigma$. Then, $\mathbf{W}=\left(w_{i j}\right)$ is a pairwise adjacency matrix between the $n$ points. To make the matrix $\mathbf{W}$ even more sparse, values of its entries that are smaller than some given threshold (i.e., the points in question are far apart from each other) can be set to zero. The graph $\mathcal{G}$ with weight matrix W gives information on the local geometry of the data.
- Spectral embedding. Define $\mathbf{D}=\left(d_{i j}\right)$ to be a diagonal matrix formed from the matrix W by setting the diagonal elements, $d_{i i}=\sum_{j} w_{i j}$, to be the column sums of $\mathbf{W}$ and the off-diagonal elements to be zero. The $(n \times n)$ symmetric matrix $\mathbf{L}=\mathbf{D}-\mathbf{W}$ is the graph Laplacian for the graph $\mathcal{G}$. We are interested in the solutions of the generalized eigenequation, $\mathbf{L v}=\lambda \mathbf{D v}$, or, equivalently, of the matrix
- $$
- \mathbf{P}=\mathbf{D}^{-1 / 2} \mathbf{L} \mathbf{D}^{-1 / 2}=\mathbf{I}_{n}-\mathbf{D}^{-1 / 2} \mathbf{W} \mathbf{D}^{-1 / 2},
- $$
- which is the normalized graph Laplacian. The matrix $\mathbf{H}=e^{t \mathbf{P}}, t \geq 0$, is usually referred to as the heat kernel. By construction, $\mathbf{P}$ is a stochastic matrix with all row sums equal to one, and, thus, can be interpreted as defining a random walk on the graph $\mathcal{G}$.
机器学习代写|流形学习代写manifold data learning代考|Hessian Eigenmaps
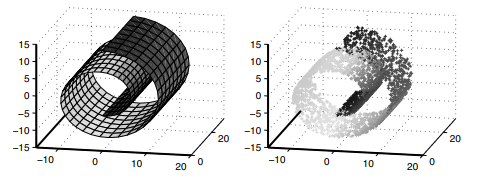
Recall that, in certain situations, the convexity assumption for IsOMAP may be too restrictive. Instead, we may require that the manifold $\mathcal{M}$ be locally isometric to an open, connected subset of $\Re^{t}$. Popular examples include families of “articulated” images (i.e., translated or rotated images of the same object, possibly through time) that are found in a high-dimensional, digitized-image library (e.g., faces, pictures, handwritten numbers or letters). However, if the pixel elements of each 64 -pixel-by-64-pixel digitized image are represented as a 4,096 -dimensional vector in “pixel space,” it would be very difficult to show that the images really live on a low-dimensional manifold, especially if that image manifold is unknown.
We can model such images using a vector of smoothly varying articulation parameters $\boldsymbol{\theta} \in \boldsymbol{\Theta}$. For example, digitized images of a person’s face that are varied by pose and illumination can be parameterized by two pose parameters (expression [happy, sad, sleepy, surprised, wink] and glasses-no glasses) and a lighting direction (centerlight, leftlight, rightlight, normal); similarly, handwritten ” 2 “s appear to be parameterized essentially by two features, bottom loop and top arch (Tenenbaum, de Silva, and Langford, 2000; Roweis and Saul, 2000). To some extent, learning about an underlying image manifold depends upon whether the images are sufficiently scattered around the manifold and how good is the quality of digitization of each image?
HESSIAN EIGENMAPS (Donoho and Grimes, 2003b) were proposed for recovering manifolds of high-dimensional libraries of articulated images where the convexity assumption is often violated. Let $\Theta \subset \Re^{t}$ be the parameter space and suppose that $\phi: \Theta \rightarrow R^{r}$, where $t<r$. Assume $\mathcal{M}=\phi(\Theta)$ is a smooth manifold of articulated images. The isometry and convexity requirements of IsoMAP are replaced by the following weaker requirements:
- Local Isometry: $\phi$ is a locally isometric embedding of $\Theta$ into $\Re^{r}$. For any point $\mathbf{x}^{\prime}$ in a sufficiently small neighborhood around each point $x$ on the manifold $\mathcal{M}$, the geodesic distance equals the Euclidean distance between their corresponding parameter points $\boldsymbol{\theta}, \boldsymbol{\theta}^{\prime} \in \Theta ;$ that is,
$$
d^{M}\left(\mathbf{x}, \mathbf{x}^{\prime}\right)=\left|\theta-\theta^{\prime}\right|_{\Theta+}
$$
where $\mathbf{x}=\phi(\boldsymbol{\theta})$ and $\mathbf{x}^{\prime}=\phi\left(\boldsymbol{\theta}^{\prime}\right)$ - Connectedness: The parameter space $\theta$ is an open, connected subset of $\Omega^{t}$.
The goal is to recover the parameter vector $\boldsymbol{\theta}$ (up to a rigid motion).
机器学习代写|流形学习代写manifold data learning代考|Nonlinear PCA
Another way of dealing with nonlinear manifold learning is to construct nonlinear versions of linear manifold learning techniques. We have already seen how Isomap provides a nonlinear generalization of MDS. How can we generalize PCA to the nonlinear case? In this Section,
we briefly describe the basic ideas behind POLYNOMIAL PCA, PRINCIPAL CuRVES AND SURFACES, MULTILAYER AUTOASSOCIATIVE NEURAL NETWORKS, and KerneL PCA.
Polynomial PCA
There have been several different attempts to generalize PCA to data living on or near nonlinear manifolds of a lower-dimensional space than input space. The first such idea was to add to the set of $r$ input variables quadratic, cubic, or higher-degree polynomial transformations of those input variables, and then apply linear PCA. The result is POLYNOMIAL PCA (Gnanadesikan and Wilk, 1969), whose embedding coordinates are the eigenvectors corresponding to the smallest few eigenvalues of the expanded covariance matrix.
In the original study of polynomial PCA, the method was illustrated with a quadratic transformation of bivariate input variables. In this scenario, $\left(X_{1}, X_{2}\right)$ expands to become $\left(X_{1}, X_{2}, X_{1}^{2}, X_{2}^{2}, X_{1} X_{2}\right)$. This formulation is feasible, but for larger problems, the possibilities become more complicated. First, the variables in the expanded set will not be scaled in a uniform manner, so that standardization will be necessary, and second, the number of variables in the expanded set will increase rapidly with large $r$, which will lead to bigger computational problems. Gnanadesikan and Wilk’s article, however, gave rise to a variety of attempts to define a more general nonlinear version of PCA.
Principal Curves and Surfaces
The next attempt at creating a nonlinear PCA was PRINCIPAL CURVES AND SURFACES (Hastie, 1984; Hastie and Stuetzle, 1989). A principal curve is a smooth one-dimensional curve that passes through the “middle” of the data, and a principal surface (or principal manifold) is a generalization of a principal curve to a smooth two- or higher-dimensional manifold. So, we can visualize principal curves and surfaces as defining a nonlinear manifold in higher-dimensional input space.
Let $\mathbf{x} \in \Re^{r}$ be a data point and let $\mathbf{f}(\lambda)$ be a curve, $\lambda \in \Lambda$; see Section $1.2 .4$ for definitions. Project $\mathbf{x}$ to a point on $\mathbf{f}(\lambda)$ that is closest in Euclidean distance to $\mathbf{x}$. Define the projection index
$$
\lambda_{\mathbf{f}}(\mathbf{x})=\sup {\lambda}\left{\lambda:|\mathbf{x}-\mathbf{f}(\lambda)|=\inf {\mu}|\mathbf{x}-\mathbf{f}(\mu)|\right}
$$
流形学习代写
机器学习代写|流形学习代写manifold data learning代考|Diffusion Maps
Diffusion Maps 的基本思想(Nadler、Lafon、Coifman 和 Kevrekidis,2005 年;Coifman 和 Lafon,2006 年)使用在数据点图上构建的马尔可夫链,然后对马尔可夫链的概率转移矩阵进行特征分析. 与本节中的其他算法一样,该算法有三个步骤,第一步和第二步与拉普拉斯特征图相同。尽管在上述关于扩散图的论文中没有明确考虑最近邻搜索(步骤 1)作为构建图的一种手段(步骤 2),但最近邻搜索包含在用于计算扩散图的软件包中。有关包含最近邻搜索的扩散图的天文学示例,请参见 Freeman、Newman、Lee、Richards 和 Schafer (2009)。
- 最近邻搜索。修复一个整数ķ或一个ε>0. 定义一个ķ-邻里ñ一世ķ或一个ε-邻里ñ一世和点的X一世如拉普拉斯特征图的第 1 步。一般来说,让ñ一世表示邻域X一世.成对邻接矩阵。这n数据点\left{\mathbf{x}{i}\right}\left{\mathbf{x}{i}\right}在ℜr可以看成图G=G(在,和)数据点扮演顶点的角色\mathcal{V}=\left{\mathbf{x}{1}, \ldots, \mathbf{x}{n}\right}\mathcal{V}=\left{\mathbf{x}{1}, \ldots, \mathbf{x}{n}\right}, 和边的集合和是连接强度(或权重),在(X一世,Xj),在相邻顶点对之间,$$ w{ij}=w\left(\mathbf{x}{i}, \mathbf{x}{j}\right)=\begin{cases}\exp \left{-\frac{\left|\mathbf{x}{i}-\mathbf{x}{i}\right|^{2}}{2 \sigma^{2} }\right}, & \text { if } \mathbf{x}{j} \in N{i} \ 0, & \text { 否则。}\结束{案例}\begin{cases}\exp \left{-\frac{\left|\mathbf{x}{i}-\mathbf{x}{i}\right|^{2}}{2 \sigma^{2} }\right}, & \text { if } \mathbf{x}{j} \in N{i} \ 0, & \text { 否则。}\结束{案例}
- $$
- 这是一个具有宽度的高斯核σ; 但是,可以使用其他内核。(1.52)等内核保证两点距离越近,值越大在. 为方便说明,我们将隐藏大多数矩阵的元素取决于σ. 然后,在=(在一世j)是之间的成对邻接矩阵n点。制作矩阵在甚至更稀疏,其条目的值小于某个给定阈值(即,所讨论的点彼此相距很远)可以设置为零。图表G权重矩阵 W 给出了数据的局部几何信息。
- 光谱嵌入。定义D=(d一世j)是通过设置对角元素由矩阵 W 形成的对角矩阵,d一世一世=∑j在一世j, 为的列总和在和非对角线元素为零。这(n×n)对称矩阵大号=D−在是图的拉普拉斯算子G. 我们对广义特征方程的解感兴趣,大号在=λD在, 或者, 等价的, 矩阵
- $$
- \mathbf{P}=\mathbf{D}^{-1 / 2} \mathbf{L} \mathbf{D}^{-1 / 2}=\mathbf{I}_{n}-\mathbf{D }^{-1 / 2} \mathbf{W} \mathbf{D}^{-1 / 2},
- $$
- 这是归一化图拉普拉斯算子。矩阵H=和吨磷,吨≥0, 通常称为热核。通过施工,磷是一个随机矩阵,所有行和都等于 1,因此可以解释为在图上定义随机游走G.
机器学习代写|流形学习代写manifold data learning代考|Hessian Eigenmaps
回想一下,在某些情况下,IsOMAP 的凸性假设可能过于严格。相反,我们可能要求流形米局部等距到一个开放的、连通的子集ℜ吨. 流行的例子包括在高维数字化图像库(例如,面孔、图片、手写数字或字母)中找到的“铰接”图像系列(即,同一对象的翻译或旋转图像,可能随着时间的推移) . 但是,如果每个 64 像素×64 像素的数字化图像的像素元素在“像素空间”中表示为 4,096 维向量,那么很难证明这些图像真的存在于低维空间中。流形,特别是如果该图像流形是未知的。
我们可以使用平滑变化的关节参数向量对此类图像进行建模θ∈θ. 例如,可以通过两个姿势参数(表情 [快乐、悲伤、困倦、惊讶、眨眼] 和不戴眼镜)和照明方向(中心光、左光, 右光, 正常); 类似地,手写的“2”似乎基本上由两个特征参数化,底部环和顶部拱(Tenenbaum、de Silva 和 Langford,2000;Roweis 和 Saul,2000)。在某种程度上,了解底层图像流形取决于图像是否充分分散在流形周围以及每个图像的数字化质量有多好?
HESSIAN EIGENMAPS (Donoho and Grimes, 2003b) 被提出用于恢复经常违反凸性假设的铰接图像的高维库的流形。让θ⊂ℜ吨是参数空间并假设φ:θ→Rr, 在哪里吨<r. 认为米=φ(θ)是铰接图像的平滑流形。IsoMAP 的等距和凸度要求被以下较弱的要求取代:
- 局部等距:φ是一个局部等距嵌入θ进入ℜr. 对于任何一点X′在每个点周围足够小的邻域中X在歧管上米,测地线距离等于它们对应的参数点之间的欧几里得距离θ,θ′∈θ;那是,
d米(X,X′)=|θ−θ′|θ+
在哪里X=φ(θ)和X′=φ(θ′) - 连通性:参数空间θ是一个开放的、连通的子集Ω吨.
目标是恢复参数向量θ(直到刚性运动)。
机器学习代写|流形学习代写manifold data learning代考|Nonlinear PCA
处理非线性流形学习的另一种方法是构建线性流形学习技术的非线性版本。我们已经看到 Isomap 如何提供 MDS 的非线性泛化。我们如何将 PCA 推广到非线性情况?在这个部分,
我们简要描述了多项式 PCA、主曲线和曲面、多层自关联神经网络和内核 PCA 背后的基本思想。
多项式 PCA
有几种不同的尝试将 PCA 推广到生活在比输入空间低维空间的非线性流形上或附近的数据。第一个这样的想法是添加到集合r输入变量对这些输入变量进行二次、三次或更高次多项式变换,然后应用线性 PCA。结果是 POLYNOMIAL PCA (Gnanadesikan and Wilk, 1969),其嵌入坐标是对应于扩展协方差矩阵的最小几个特征值的特征向量。
在多项式 PCA 的原始研究中,该方法通过二元输入变量的二次变换来说明。在这种情况下,(X1,X2)展开成为(X1,X2,X12,X22,X1X2). 这个公式是可行的,但是对于更大的问题,可能性变得更加复杂。首先,扩展集中的变量不会以统一的方式缩放,因此需要标准化,其次,扩展集中的变量数量会随着较大的r,这将导致更大的计算问题。然而,Gnanadesikan 和 Wilk 的文章引发了各种尝试来定义更一般的非线性 PCA 版本。
主曲线和曲面
创建非线性 PCA 的下一个尝试是主曲线和曲面(Hastie,1984;Hastie 和 Stuetzle,1989)。主曲线是通过数据“中间”的平滑一维曲线,主曲面(或主流形)是主曲线向平滑二维或更高维流形的推广。因此,我们可以将主曲线和曲面可视化为在高维输入空间中定义非线性流形。
让X∈ℜr是一个数据点,让F(λ)成为曲线,λ∈Λ; 见部分1.2.4用于定义。项目X到一点F(λ)在欧几里得距离上最接近X. 定义投影索引
\lambda_{\mathbf{f}}(\mathbf{x})=\sup {\lambda}\left{\lambda:|\mathbf{x}-\mathbf{f}(\lambda)|=\inf { \mu}|\mathbf{x}-\mathbf{f}(\mu)|\right}

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。