如果你也在 怎样代写深度学习deep learning这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
深度学习是机器学习的一个子集,它本质上是一个具有三层或更多层的神经网络。这些神经网络试图模拟人脑的行为–尽管远未达到与之匹配的能力–允许它从大量数据中 “学习”。
statistics-lab™ 为您的留学生涯保驾护航 在代写深度学习deep learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写深度学习deep learning代写方面经验极为丰富,各种代写深度学习deep learning相关的作业也就用不着说。
我们提供的深度学习deep learning及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
机器学习代写|深度学习project代写deep learning代考|HyShalini Agrahari* and Arvind Kumar Tiwari
Text recognition has risen in popularity in the area of computer vision and natural language processing due to its use in different fields. For character recognition in a handwriting recognition system, several methods have been suggested. There are enough studies that define the techniques for translating text information from a piece of paper to an electronic format. Text recognition systems may play a key role in creating a paper-free environment in the future by digitizing and handling existing paper records. This chapter provides a thorough analysis of the field of Text Recognition.
We are all familiar with the convenience of having an editable text document that can be easily read by a computer and the information can be used for a variety of uses. People always wanted to use the text that is present in various forms all around them, such as handwritten documents, receipts, images, signboards, hoardings, street signs, nameplates, number plates of automobiles, as subtitles in videos, as captions for photos, and in a variety of other ways. However, we are unable to make use of this information because our computer is unable to recognize these texts purely based on their raw images. Hence, researchers around the world have been trying hard to make computers worthy of directly recognizing text by acquiring images to use the several information sources that could be used in a variety of ways by our computers. In most cases, we have no choice but to typewrite handwritten information, which is very timeconsuming. So, here we have a text recognition system that overcomes these problems. We can see the importance of a ‘Text Recognition System’ just by having to look at these scenarios, which have a wide range of applications in security, robotics, official documentation, content filtering, and many more.
Due to digitalization, there is a huge demand for storing data into the computer by converting documents into digital format. It is difficult to recognize text in various sources like text documents, images, and videos, etc. due to some noise. The text recognition system is a technique by which recognizer recognizes the characters or texts or various symbols. The text recognition system consists of a procedure of transforming input images into machine-understandable format $[1,2]$.
The use of text recognition has a lot of benefits. For example, we find a lot of historical papers in offices and other places that can be easily replaced with editable text and archived instead of taking up too much space with their hard copies. Online and offline text recognition are the two main types of recognition whether online recognition system includes tablet and digital pen, while offline recognition includes printed or handwritten documents [3].
机器学习代写|深度学习project代写deep learning代考|Convolutional Neural Network
CNN [6] is a method of deep learning algorithm that is specifically trained to perform with image files. A simple class that perfectly represents the image in CNN, processed through a series of convolutional layers, a pooling layer, and fully connected layers. CNN can learn multiple layers of feature representations of an image by applying
different techniques. Low-level features such as edges and curves are examined by image classification in this method and a sequence of convolutional layers helps in building up to more abstract. CNN provides greater precision and improves performance because of its exclusive characteristics, such as local connectivity and parameter sharing. The input layer, multiple hidden layers (convolutional, normalization, pooling), and a fully connected and output layer make up the system of CNN. Neurons in one layer communicate with some neurons in the next layer, making the scaling simpler for higher resolutions.
In the input layer, the input file is recorded and collected. This layer contains information about the input image’s height, width, and several channels (RGB information). To recognize the features, the network will use a sequence of convolutions and pooling operations in multiple hidden layers. Convolution is one of the most important components of a CNN. The numerical mixture of multiple functions to produce a new function is known as convolution. Convolution is applied to the input image via a filter or, to produce a feature map in the case of a CNN. The input layer contains $n \times n$ input neurons which are convoluted with the filter size of $m$ $\times m$ and return output size of $(n-m+1) \times(n-m+1)$. On our input, we perform several convolutions, each with a different filter. As a result, different feature maps emerge. Finally, we combine these entire feature maps to create the convolution layer final output. To reduce the input feature space and hence reduces the higher computation; a pooling layer is placed between two convolutional layers. Pooling allows passing only the values you want to the next layer, leaving the unnecessary behind. This reduces training time, prevents overfitting, and helps in feature selection. The max-pooling operation takes the highest value from each sub-region of the image vector while keeping the most information, this operation is generally preferred in modern applications. CNN’s architecture, like regular neural network architecture, includes an activation function to present non-linearity into the system. Among the various activation functions used extensively in deep learning models, the sigmoid function rectified linear unit (ReLu), and softmax are some wellknown examples. In CNN architecture, the classification layer is the final
layer. It’s a fully connected feed-forward network that’s most commonly used as a classifier. This layer determines predicted classes by categorizing the input image, which is accomplished by combining all the previous layers’ features.
Image recognition, image classification, object detection, and face recognition are just a few of the applications for CNN. The most important section in CNN is the feature extraction section and classification section.
机器学习代写|深度学习project代写deep learning代考|Recurrent Neural Network
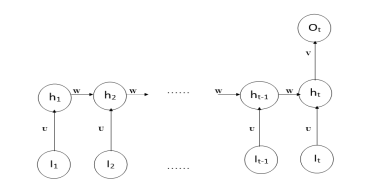
RNN is a deep learning technique that is both effective and robust, and it is one of the most promising methods currently in use because it is the only one with internal storage. RNN is useful when it is required to predict the next word of sequence [7]. When dealing with sequential data (financial data or the DNA sequence), recurrent neural networks are commonly used. The reason for this is that the model employs layers, which provide a short-term memory for the model. Using this memory, it can more accurately determine the next data and memorize all the information about what was calculated. If we want to use sequence matches in such data, we’ll need a network with previous knowledge of the data. The output from the previous step is fed into the current step in this approach. The architecture of RNN includes three layers: input layer, hidden layer, and output layer. The hidden layer remembers information about sequences.
If compare RNN with a traditional feed-forward neural network(FNN), FNN cannot remember the sequence of data. Suppose we give a word “hello” as input to FNN, FNN processes it character by character. It has already forgotten about ‘ $h$ ‘ ‘e’ and ‘ $l$ ‘ by the time it gets to the character ‘ $o$ ‘. Fortunately, because of its internal memory, a recurrent neural network can remember those characters. This is important because the data sequence comprises important information about what will happen next, that’s why an RNN can perform tasks that some other techniques cannot.
深度学习代写
机器学习代写|深度学习project代写deep learning代考|HyShalini Agrahari* and Arvind Kumar Tiwari
由于文本识别在不同领域的应用,文本识别在计算机视觉和自然语言处理领域越来越受欢迎。对于手写识别系统中的字符识别,已经提出了几种方法。有足够多的研究定义了将文本信息从一张纸转换为电子格式的技术。文本识别系统可能在未来通过数字化和处理现有纸质记录来创建无纸环境中发挥关键作用。本章提供了对文本识别领域的全面分析。
我们都熟悉拥有可编辑的文本文档的便利性,该文档可以通过计算机轻松阅读,并且信息可用于多种用途。人们总是想把身边以各种形式存在的文字,如手写文件、收据、图像、招牌、围板、路牌、铭牌、汽车号牌,作为视频的字幕,作为照片的标题,并以各种其他方式。但是,我们无法利用这些信息,因为我们的计算机无法仅根据原始图像识别这些文本。因此,世界各地的研究人员一直在努力使计算机能够通过获取图像来直接识别文本,以使用我们的计算机可以以多种方式使用的多种信息源。大多数情况下,我们只好打字手写信息,非常耗时。所以,这里我们有一个克服这些问题的文本识别系统。只需查看这些场景,我们就可以看到“文本识别系统”的重要性,这些场景在安全、机器人技术、官方文档、内容过滤等方面有广泛的应用。
由于数字化,通过将文档转换为数字格式将数据存储到计算机中的需求巨大。由于一些噪声,难以识别各种来源(如文本文档、图像和视频等)中的文本。文本识别系统是识别器识别字符或文本或各种符号的技术。文本识别系统由将输入图像转换为机器可理解格式的过程组成[1,2].
使用文本识别有很多好处。例如,我们在办公室和其他地方发现了很多历史论文,可以很容易地用可编辑的文本替换并存档,而不是用硬拷贝占用太多空间。在线和离线文本识别是两种主要的识别类型,在线识别系统包括平板电脑和数字笔,而离线识别包括印刷或手写文档[3]。
机器学习代写|深度学习project代写deep learning代考|Convolutional Neural Network
CNN [6] 是一种深度学习算法,专门训练用于处理图像文件。一个简单的类,完美地表示 CNN 中的图像,通过一系列卷积层、一个池化层和全连接层进行处理。CNN 可以通过应用来学习图像的多层特征表示
不同的技术。在这种方法中,通过图像分类检查边缘和曲线等低级特征,一系列卷积层有助于构建更抽象的特征。CNN 因其独有的特性(例如局部连通性和参数共享)而提供了更高的精度并提高了性能。输入层、多个隐藏层(卷积、归一化、池化)以及全连接和输出层构成了 CNN 系统。一层中的神经元与下一层中的一些神经元通信,使得缩放更简单以获得更高的分辨率。
在输入层,记录和收集输入文件。该层包含有关输入图像的高度、宽度和几个通道的信息(RGB 信息)。为了识别特征,网络将在多个隐藏层中使用一系列卷积和池化操作。卷积是 CNN 最重要的组成部分之一。多个函数的数值混合以产生一个新函数称为卷积。卷积通过过滤器应用于输入图像,或者在 CNN 的情况下生成特征图。输入层包含n×n与滤波器大小卷积的输入神经元米 ×米并返回输出大小(n−米+1)×(n−米+1). 在我们的输入上,我们执行了几个卷积,每个卷积都有一个不同的过滤器。结果,出现了不同的特征图。最后,我们结合这些完整的特征图来创建卷积层的最终输出。减少输入特征空间,从而减少更高的计算量;池化层放置在两个卷积层之间。池化允许仅将您想要的值传递给下一层,而将不必要的值留在后面。这减少了训练时间,防止过拟合,并有助于特征选择。最大池化操作从图像向量的每个子区域中获取最高值,同时保留最多的信息,这种操作在现代应用程序中通常是首选。CNN 的架构与常规的神经网络架构一样,包括一个激活函数来将非线性呈现到系统中。在深度学习模型中广泛使用的各种激活函数中,sigmoid 函数整流线性单元 (ReLu) 和 softmax 是一些众所周知的例子。在 CNN 架构中,分类层是最终的
层。它是一个全连接的前馈网络,最常用作分类器。该层通过对输入图像进行分类来确定预测类别,这是通过组合所有先前层的特征来完成的。
图像识别、图像分类、对象检测和人脸识别只是 CNN 的一些应用。CNN 中最重要的部分是特征提取部分和分类部分。
机器学习代写|深度学习project代写deep learning代考|Recurrent Neural Network
RNN 是一种既有效又健壮的深度学习技术,它是目前使用的最有前途的方法之一,因为它是唯一具有内部存储的方法。当需要预测序列的下一个单词时,RNN 很有用 [7]。在处理顺序数据(财务数据或 DNA 序列)时,通常使用循环神经网络。原因是模型使用了层,这些层为模型提供了短期记忆。使用此内存,它可以更准确地确定下一个数据并记住有关计算内容的所有信息。如果我们想在此类数据中使用序列匹配,我们需要一个具有数据先前知识的网络。在这种方法中,上一步的输出被馈送到当前步骤。RNN的架构包括三层:输入层,隐藏层和输出层。隐藏层记住有关序列的信息。
如果将 RNN 与传统的前馈神经网络(FNN)进行比较,FNN 无法记住数据的序列。假设我们将单词“hello”作为 FNN 的输入,FNN 会逐字符处理它。它已经忘记了’H”e’ 和 ‘l’当它到达角色’这’。幸运的是,由于其内部记忆,循环神经网络可以记住这些字符。这很重要,因为数据序列包含有关接下来会发生什么的重要信息,这就是为什么 RNN 可以执行一些其他技术无法执行的任务的原因。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。