如果你也在 怎样代写商业分析Statistical Modelling for Business这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
商业分析就是利用数据分析和统计的方法,来分析企业之前的商业表现,从而通过分析结果来对未来的商业战略进行预测和指导 。
statistics-lab™ 为您的留学生涯保驾护航 在代写商业分析Statistical Modelling for Business方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写商业分析Statistical Modelling for Business方面经验极为丰富,各种代写商业分析Statistical Modelling for Business相关的作业也就用不着说。
我们提供的商业分析Statistical Modelling for Business及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|商业分析作业代写Statistical Modelling for Business代考|The Brokerage Firm Case: Studying Client Satisfaction
Previous sections in this chapter have presented methods for summarizing data for a single variable. Often, however, we wish to use statistics to study possible relationships between several variables. In this section we present a simple way to study the relationship between two variables. Crosstabulation is a process that classifies data on two dimensions. This process results in a table that is called a contingency table. Such a table consists of rows and columns – the rows classify the data according to one dimension and the columns classify the data according to a second dimension. Together, the rows and columns represent all possibilities (or contingencies).An investment broker sells several kinds of investment products-a stock fund, a bond fund, and a tax-deferred annuity. The broker wishes to study whether client satisfaction with its products and services depends on the type of investment product purchased. To do this, 100 of the broker’s clients are randomly selected from the population of clients who have
purchased shares in exactly one of the funds. The broker records the fund type purchased by each client and has one of its investment counselors personally contact the client. When contacted, the client is asked to rate his or her level of satisfaction with the purchased fund as high, medium, or low. The resulting data are given in Table 2.16.
Looking at the raw data in Table $2.16$, it is difficult to see whether the level of client satisfaction varies depending on the fund type. We can look at the data in an organized way by constructing a contingency table. A crosstabulation of fund type versus level of client satisfaction is shown in Table $2.17$. The classification categories for the two variables are defined along the left and top margins of the table. The three row labels-bond fund, stock fund, and tax deferred annuity-define the three fund categories and are given in the left table margin. The three column labels-high, medium, and low-define the three levels of client satisfaction and are given along the top table margin. Each row and column combination, that is, each fund type and level of satisfaction combination, defines what we call a “cell” in the table. Because each of the randomly selected clients has invested in exactly one fund type and has reported exactly one level of satisfaction, each client can be placed in a particular cell in the contingency table. For example, because client number 1 in Table $2.16$ has invested in the bond fund and reports a high level of client satisfaction, client number 1 can be placed in the upper left cell of the table (the cell defined by the Bond Fund row and High Satisfaction column).
统计代写|商业分析作业代写Statistical Modelling for Business代考|column percentages
One good way to investigate relationships such as these is to compute row percentages and column percentages. We compute row percentages by dividing each cell’s freguency by its corresponding row total and by expressing the resulting fraction as a percentage. For instance, the row percentage for the upper left-hand cell (bond fund and high level of satisfaction) in Table $2.17$ is $(15 / 30) \times 100 \%=50 \%$. Similarly, column percentages are computed by dividing each cell’s frequency by its corresponding column total and by expressing the resulting fraction as a percentage. For example, the column percentage for the upper left-hand cell in Table $2.17$ is $(15 / 40) \times 100 \%=37.5 \%$. Table $2.18$ summarizes all of the row percentages for the different fund types in Table 2.17. We see that each row in Table $2.18$ gives a percentage frequency distribution of level of client satisfaction given a particular fund type.
For example, the first row in Table $2.18$ gives a percent frequency distribution of client satisfaction for investors who have purchased shares in the bond fund. We see that 50 percent of bond fund investors report high satisfaction, while 40 percent of these investors report medium satisfaction, and only 10 percent report low satisfaction. The other mows in Tahle $2.18$ provide. Гepcent freynency distrikutions of client satisfaction for stock fund and annuity parchasers
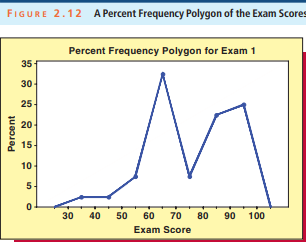
All three percent frequency distributions of client satisfaction-for the bond fund, the stock fund, and the tax deferred annuity-are illustrated using bar charts in Figure $2.23$. In this figure, the bar heights for each chart are the respective row percentages in Table $2.18$. For example, these distributions tell us that 80 percent of stock fund investors report high satisfaction, while $97.5$ percent of tax deferred annuity purchasers report medium or low satisfaction. Looking at the entire table of row percentages (or the bar charts in Figure 2.23), we might conclude that stock fund investors are highly satisfied, that bond fund investors are quite satisfied (but, somewhat less so than stock fund investors), and that tax-deferred-annuity purchasers are less satisfied than either stock fund or bond fund investors. In general, row percentages and column percentages help us to quantify relationships such as these.
In the investment example, we have cross-tabulated two qualitative variables. We can also cross-tabulate a quantitative variable versus a qualitative variable or two quantitative variables against each other. If we are cross-tabulating a quantitative variable, we often define categories by using appropriate ranges. For example, if we wished to cross-tabulate level of education (grade school, high school, college, graduate school) versus income, we might define income classes $\$ 0-\$ 50,000, \$ 50,001-\$ 100,000, \$ 100,001-\$ 150,000$, and above $\$ 150,000$.
统计代写|商业分析作业代写Statistical Modelling for Business代考|Scatter Plots
We often study relationships between variables by using graphical methods. A simple graph that can be used to study the relationship between two variables is called a scatter plot. As an example, suppose that a marketing manager wishes to investigate the relationship between the sales volume (in thousands of units) of a product and the amount spent (in units of $\$ 10,000$ ) on advertising the product. To do this, the marketing manager randomly selects 10 sales regions having equal sales potential. The manager assigns a different level of advertising expenditure for January 2016 to each sales region as shown in Table 2.20. At the end of the month, the sales volume for each region is recorded as also shown in Table $2.20$.
A scatter plot of these data is given in Figure 2.24. To construct this plot, we place the variable advertising expenditure (denoted $x$ ) on the horizontal axis and we place the variable sales volume (denoted $y$ ) on the vertical axis. For the first sales region, advertising expenditure equals 5 and sales volume equals 89 . We plot the point with coordinates $x=5$ and $y=89$ on the scatter plot to represent this sales region. Points for the other sales regions are plotted similarly. The scatter plot shows that there is a positive relationship between advertising expenditure and sales volumethat is, higher values of sales volume are associated with higher levels of advertising expenditure.
We have drawn a straight line through the plotted points of the scatter plot to represent the relationship between advertising expenditure and sales volume. We often do this when the relationship between two variables appears to be a straight line, or linear, relationship. Of course, the relationship between $x$ and $y$ in Figure $2.24$ is not perfectly linear-not all of the points in the scatter plot are exactly on the line. Nevertheless, because the relationship between $x$ and $y$ appears to be approximately linear, it seems reasonable to represent the general relationship between these variables using a straight line. In future chapters we will explain ways to quantify such a relationship that is, describe such a relationship numerically. Moreover, not all linear relationships between two variables $x$ and $y$ are positive linear relationships (that is, have a positive slope). For example, Table $2.21$ on the next page gives the average hourly outdoor temperature $(x)$ in a city during a week and the city’s natural gas consumption (y) during the week for each of the previous eight weeks. The temperature readings are expressed in degrees Fahrenheit and the natural gas consumptions are expressed in millions of cubic feet of natural gas. The scatter plot in Figure $2.25$ shows that there is a
negative linear relationship between $x$ and $y$-that is, as average hourly temperature in the city increases, the city’s natural gas consumption decreases in a linear fashion. Finally, not all relationships are linear. In Chapter 14 we will consider how to represent and quantify curved relationships, and, as illustrated in Figure $2.26$, there are situations in which two variables $x$ and $y$ do not appear to have any relationship.
To conclude this section, recall from Chapter 1 that a time series plot (also called a runs plot) is a plot of individual process measurements versus time. This implies that a time series plot is a scatter plot, where values of a process variable are plotted on the vertical axis versus corresponding values of time on the horizontal axis.
金融中的随机方法代写
统计代写|商业分析作业代写Statistical Modelling for Business代考|The Brokerage Firm Case: Studying Client Satisfaction
本章的前几节介绍了汇总单个变量数据的方法。然而,我们通常希望使用统计数据来研究几个变量之间可能存在的关系。在本节中,我们提出了一种研究两个变量之间关系的简单方法。交叉制表是在两个维度上对数据进行分类的过程。此过程产生一个称为列联表的表。这样的表由行和列组成——行根据一维对数据进行分类,列根据第二维对数据进行分类。行和列一起代表所有可能性(或意外情况)。投资经纪人销售几种投资产品——股票基金、债券基金和延税年金。经纪商希望研究客户对其产品和服务的满意度是否取决于所购买的投资产品类型。为此,经纪人的 100 名客户是从拥有
购买了其中一只基金的股票。经纪人记录每个客户购买的基金类型,并让其一名投资顾问亲自与客户联系。联系时,客户被要求将他或她对所购买基金的满意度评定为高、中或低。结果数据在表 2.16 中给出。
查看表中的原始数据2.16,很难看出客户满意度是否因基金类型而异。我们可以通过构建列联表以有组织的方式查看数据。表中显示了基金类型与客户满意度的交叉表2.17. 两个变量的分类类别沿表格的左边缘和上边缘定义。三行标签——债券基金、股票基金和延税年金——定义了三个基金类别,并在左表边距中给出。三列标签(高、中和低)定义了客户满意度的三个级别,并沿顶部表格边缘给出。每个行和列的组合,即每个基金类型和满意度组合,定义了我们所说的表格中的“单元格”。因为每个随机选择的客户都只投资了一种基金类型并报告了一种满意程度,所以每个客户都可以放在列联表的特定单元格中。例如,因为表中的客户编号 12.16已投资债券基金并报告客户满意度高,客户编号 1 可放置在表格的左上角单元格(由债券基金行和高满意度列定义的单元格)。
统计代写|商业分析作业代写Statistical Modelling for Business代考|column percentages
调查此类关系的一种好方法是计算行百分比和列百分比。我们通过将每个单元格的频率除以其相应的行总数并将结果分数表示为百分比来计算行百分比。例如,表中左上角单元格(债券基金和高满意度)的行百分比2.17是(15/30)×100%=50%. 类似地,通过将每个单元格的频率除以其相应的列总数并将所得分数表示为百分比来计算列百分比。例如,表中左上角单元格的列百分比2.17是(15/40)×100%=37.5%. 桌子2.18总结了表 2.17 中不同基金类型的所有行百分比。我们看到 Table 中的每一行2.18给出给定特定基金类型的客户满意度水平的百分比频率分布。
例如,表中的第一行2.18给出已购买债券基金股份的投资者的客户满意度百分比分布。我们看到 50% 的债券基金投资者表示高满意度,而这些投资者中有 40% 表示中等满意度,只有 10% 表示低满意度。塔勒的其他刈草2.18提供。股票基金和年金购买者的客户满意度的 epcent
频率分布 债券基金、股票基金和税收递延年金的客户满意度的所有 3% 频率分布都用图 1 中的条形图说明2.23. 在此图中,每个图表的条形高度是表中相应的行百分比2.18. 例如,这些分布告诉我们,80% 的股票基金投资者表示非常满意,而97.5百分之几的延税年金购买者表示满意度中等或低。查看整个行百分比表(或图 2.23 中的条形图),我们可能会得出结论,股票基金投资者非常满意,债券基金投资者非常满意(但略低于股票基金投资者),并且与股票基金或债券基金投资者相比,延税年金购买者的满意度较低。一般来说,行百分比和列百分比可以帮助我们量化诸如此类的关系。
在投资示例中,我们对两个定性变量进行了交叉制表。我们还可以将一个定量变量与一个定性变量或两个定量变量相互交叉制表。如果我们对定量变量进行交叉制表,我们通常会使用适当的范围来定义类别。例如,如果我们希望将教育水平(小学、高中、大学、研究生院)与收入进行交叉制表,我们可以定义收入等级$0−$50,000,$50,001−$100,000,$100,001−$150,000, 以上$150,000.
统计代写|商业分析作业代写Statistical Modelling for Business代考|Scatter Plots
我们经常使用图解法来研究变量之间的关系。可用于研究两个变量之间关系的简单图形称为散点图。例如,假设营销经理希望调查产品的销售量(以千为单位)与花费的金额(以$10,000) 宣传产品。为此,营销经理随机选择 10 个具有相同销售潜力的销售区域。经理为每个销售区域分配了 2016 年 1 月不同水平的广告支出,如表 2.20 所示。月末各地区的销量记录如表所示2.20.
图 2.24 给出了这些数据的散点图。为了构建这个图,我们将变量广告支出(表示为X)在横轴上,我们将变量销售量(表示为是) 在垂直轴上。对于第一个销售区域,广告支出为 5,销量为 89 。我们用坐标绘制点X=5和是=89在散点图上表示该销售区域。其他销售区域的点也以类似方式绘制。散点图表明,广告支出与销售额之间存在正相关关系,即销售额越高,广告支出水平越高。
我们通过散点图的绘制点画了一条直线来表示广告支出和销量之间的关系。当两个变量之间的关系看起来是直线或线性关系时,我们经常这样做。当然,两者之间的关系X和是如图2.24不是完全线性的——并不是散点图中的所有点都完全在线上。然而,由于两者之间的关系X和是似乎是近似线性的,用直线表示这些变量之间的一般关系似乎是合理的。在以后的章节中,我们将解释量化这种关系的方法,即用数字描述这种关系。此外,并非两个变量之间的所有线性关系X和是是正线性关系(即,具有正斜率)。例如,表2.21下一页给出了平均每小时室外温度(X)一周内城市的天然气消耗量(y),前八周的每一周。温度读数以华氏度表示,天然气消耗量以百万立方英尺天然气表示。图中的散点图2.25表明有一个
之间的负线性关系X和是-也就是说,随着城市平均每小时温度的升高,城市的天然气消耗量呈线性下降。最后,并非所有关系都是线性的。在第 14 章中,我们将考虑如何表示和量化曲线关系,如图所示2.26, 有两个变量的情况X和是似乎没有任何关系。
总结本节,回顾第 1 章,时间序列图(也称为运行图)是单个过程测量值与时间的关系图。这意味着时间序列图是散点图,其中过程变量的值绘制在垂直轴上,而相应的时间值绘制在水平轴上。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。统计代写|python代写代考
随机过程代考
在概率论概念中,随机过程是随机变量的集合。 若一随机系统的样本点是随机函数,则称此函数为样本函数,这一随机系统全部样本函数的集合是一个随机过程。 实际应用中,样本函数的一般定义在时间域或者空间域。 随机过程的实例如股票和汇率的波动、语音信号、视频信号、体温的变化,随机运动如布朗运动、随机徘徊等等。
贝叶斯方法代考
贝叶斯统计概念及数据分析表示使用概率陈述回答有关未知参数的研究问题以及统计范式。后验分布包括关于参数的先验分布,和基于观测数据提供关于参数的信息似然模型。根据选择的先验分布和似然模型,后验分布可以解析或近似,例如,马尔科夫链蒙特卡罗 (MCMC) 方法之一。贝叶斯统计概念及数据分析使用后验分布来形成模型参数的各种摘要,包括点估计,如后验平均值、中位数、百分位数和称为可信区间的区间估计。此外,所有关于模型参数的统计检验都可以表示为基于估计后验分布的概率报表。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
statistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
机器学习代写
随着AI的大潮到来,Machine Learning逐渐成为一个新的学习热点。同时与传统CS相比,Machine Learning在其他领域也有着广泛的应用,因此这门学科成为不仅折磨CS专业同学的“小恶魔”,也是折磨生物、化学、统计等其他学科留学生的“大魔王”。学习Machine learning的一大绊脚石在于使用语言众多,跨学科范围广,所以学习起来尤其困难。但是不管你在学习Machine Learning时遇到任何难题,StudyGate专业导师团队都能为你轻松解决。
多元统计分析代考
基础数据: $N$ 个样本, $P$ 个变量数的单样本,组成的横列的数据表
变量定性: 分类和顺序;变量定量:数值
数学公式的角度分为: 因变量与自变量
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。