如果你也在 怎样代写统计推断statistics interference这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
统计推断是利用数据分析来推断概率基础分布的属性的过程。 推断性统计分析推断人口的属性,例如通过测试假设和得出估计值。
statistics-lab™ 为您的留学生涯保驾护航 在代写统计推断statistics interference方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写统计推断statistics interference方面经验极为丰富,各种代写统计推断statistics interference相关的作业也就用不着说。
我们提供的属性统计推断statistics interference及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|统计推断作业代写statistics interference代考|General remarks
We can now consider some issues involved in formulating and comparing the different approaches.
In some respects the Bayesian formulation is the simpler and in other respects the more difficult. Once a likelihood and a prior are specified to a reasonable approximation all problems are, in principle at least, straightforward. The resulting posterior distribution can be manipulated in accordance with the ordinary laws of probability. The difficulties centre on the concepts underlying the definition of the probabilities involved and then on the numerical specification of the prior to sufficient accuracy.
Sometimes, as in certain genetical problems, it is reasonable to think of $\theta$ as generated by a stochastic mechanism. There is no dispute that the Bayesian approach is at least part of a reasonable formulation and solution in such situations. In other cases to use the formulation in a literal way we have to regard probability as measuring uncertainty in a sense not necessarily directly linked to frequencies. We return to this issue later. Another possible justification of some Bayesian methods is that they provide an algorithm for extracting from the likelihood some procedures whose fundamental strength comes from frequentist considerations. This can be regarded, in particular, as supporting
$5.2$ Broad roles of probability
a broad class of procedures, known as shrinkage methods, including ridge regression.
The emphasis in this book is quite often on the close relation between answers possible from different approaches. This does not imply that the different views never conflict. Also the differences of interpretation between different numerically similar answers may be conceptually important.
统计代写|统计推断作业代写statistics interference代考|Broad roles of probability
A recurring theme in the discussion so far has concerned the broad distinction between the frequentist and the Bayesian formalization and meaning of probability. Kolmogorov’s axiomatic formulation of the theory of probability largely decoupled the issue of meaning from the mathematical aspects; his axioms were, however, firmly rooted in a frequentist view, although towards the end of his life he became concerned with a different interpretation based on complexity. But in the present context meaning is crucial.
There are two ways in which probability may be used in statistical discussions. The first is phenomenological, to describe in mathematical form the empirical regularities that characterize systems containing haphazard variation. This typically underlies the formulation of a probability model for the data, in particular leading to the unknown parameters which are regarded as a focus of interest. The probability of an event $\mathcal{E}$ is an idealized limiting proportion of times in which $\mathcal{E}$ occurs in a large number of repeat observations on the system under the same conditions. In some situations the notion of a large number of repetitions can be reasonably closely realized; in others, as for example with economic time series, the notion is a more abstract construction. In both cases the working assumption is that the parameters describe features of the underlying data-generating process divorced from special essentially accidental features of the data under analysis.
That first phenomenological notion is concerned with describing variability. The second role of probability is in connection with uncertainty and is thus epistemological. In the frequentist theory we adapt the frequency-based view of probability, using it only indirectly to calibrate the notions of confidence intervals and significance tests. In most applications of the Bayesian view we need an extended notion of probability as measuring the uncertainty of $\mathcal{E}$ given $\mathcal{F}$, where now $\mathcal{E}$, for example, is not necessarily the outcome of a random system, but may be a hypothesis or indeed any feature which is unknown to the investigator. In statistical applications $\mathcal{E}$ is typically some statement about the unknown parameter $\theta$ or more specifically about the parameter of interest $\psi$. The present
discussion is largely confined to such situations. The issue of whether a single number could usefully encapsulate uncertainty about the correctness of, say, the Fundamental Theory underlying particle physics is far outside the scope of the present discussion. It could, perhaps, be applied to a more specific question such as a prediction of the Fundamental Theory: will the Higgs boson have been discovered by 2010 ?
One extended notion of probability aims, in particular, to address the point that in interpretation of data there are often sources of uncertainty additional to those arising from narrow-sense statistical variability. In the frequentist approach these aspects, such as possible systematic errors of measurement, are addressed qualitatively, usually by formal or informal sensitivity analysis, rather than incorporated into a probability assessment.
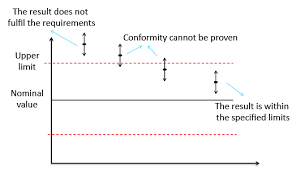
统计代写|统计推断作业代写statistics interference代考|Frequentist interpretation of upper limits
First we consider the frequentist interpretation of upper limits obtained, for example, from a suitable pivot. We take the simplest example, Example 1.1, namely the normal mean when the variance is known, but the considerations are fairly general. The upper limit
$$
\bar{y}+k_{c}^{} \sigma_{0} / \sqrt{n}, $$ derived here from the probability statement $$ P\left(\mu<\bar{Y}+k_{c}^{} \sigma_{0} / \sqrt{n}\right)=1-c,
$$
is a particular instance of a hypothetical long run of statements a proportion $1-c$ of which will be true, always, of course, assuming our model is sound. We can, at least in principle, make such a statement for each $c$ and thereby generate a collection of statements, sometimes called a confidence distribution. There is no restriction to a single $c$, so long as some compatibility requirements hold.
Because this has the formal properties of a distribution for $\mu$ it was called by R. A. Fisher the fiducial distribution and sometimes the fiducial probability distribution. A crucial question is whether this distribution can be interpreted and manipulated like an ordinary probability distribution. The position is:
- a single set of limits for $\mu$ from some data can in some respects be considered just like a probability statement for $\mu$;
- such probability statements cannot in general be combined or manipulated by the laws of probability to evaluate, for example, the chance that $\mu$ exceeds some given constant, for example zero. This is clearly illegitimate in the present context.
That is, as a single statement a $1-c$ upper limit has the evidential force of a statement of a unique event within a probability system. But the rules for manipulating probabilities in general do not apply. The limits are, of course, directly based on probability calculations.
Nevertheless the treatment of the confidence interval statement about the parameter as if it is in some respects like a probability statement contains the important insights that, in inference for the normal mean, the unknown parameter is more likely to be near the centre of the interval than near the end-points and that, provided the model is reasonably appropriate, if the mean is outside the interval it is not likely to be far outside.
A more emphatic demonstration that the sets of upper limits defined in this way do not determine a probability distribution is to show that in general there is an inconsistency if such a formal distribution determined in one stage of analysis is used as input into a second stage of probability calculation. We shall not give details; see Note 5.2.
The following example illustrates in very simple form the care needed in passing from assumptions about the data, given the model, to inference about the model, given the data, and in particular the false conclusions that can follow from treating such statements as probability statements.
属性数据分析
统计代写|统计推断作业代写statistics interference代考|General remarks
我们现在可以考虑制定和比较不同方法所涉及的一些问题。
在某些方面,贝叶斯公式更简单,而在其他方面则更困难。一旦将可能性和先验指定为合理的近似值,所有问题至少在原则上都是直截了当的。由此产生的后验分布可以根据普通的概率定律进行操作。困难集中在所涉及的概率定义背后的概念上,然后是足够准确度的先验数值规范。
有时,就像在某些遗传问题中一样,有理由认为θ由随机机制产生。毫无疑问,贝叶斯方法至少是在这种情况下合理制定和解决方案的一部分。在其他情况下,要以字面的方式使用该公式,我们必须将概率视为在某种意义上测量不确定性,不一定与频率直接相关。我们稍后会回到这个问题。一些贝叶斯方法的另一个可能的理由是它们提供了一种算法,用于从可能性中提取一些基本优势来自频率论考虑的过程。这尤其可以被视为支持
5.2概率
的广泛作用 一类广泛的程序,称为收缩方法,包括岭回归。
本书的重点往往是不同方法可能得出的答案之间的密切关系。这并不意味着不同的观点永远不会冲突。此外,不同数值相似答案之间的解释差异在概念上可能很重要。
统计代写|统计推断作业代写statistics interference代考|Broad roles of probability
到目前为止,讨论中反复出现的主题涉及频率论和贝叶斯形式化之间的广泛区别以及概率的含义。Kolmogorov 对概率论的公理化表述在很大程度上将意义问题与数学方面脱钩了。然而,他的公理坚定地植根于频率论观点,尽管在他生命的最后阶段,他开始关注基于复杂性的不同解释。但在目前的语境中,意义是至关重要的。
有两种方法可以在统计讨论中使用概率。第一个是现象学的,以数学形式描述表征包含随意变化的系统的经验规律。这通常是数据概率模型制定的基础,特别是导致被视为关注焦点的未知参数。事件的概率和是一个理想化的极限比例,其中和发生在相同条件下对系统的大量重复观察中。在某些情况下,可以合理地接近地实现大量重复的概念;在其他情况下,例如经济时间序列,这个概念是一个更抽象的结构。在这两种情况下,工作假设是参数描述了底层数据生成过程的特征,与所分析数据的特殊本质上的偶然特征相分离。
第一个现象学概念与描述可变性有关。概率的第二个作用与不确定性有关,因此是认识论的。在频率论理论中,我们采用基于频率的概率观点,仅间接使用它来校准置信区间和显着性检验的概念。在贝叶斯观点的大多数应用中,我们需要一个扩展的概率概念来衡量不确定性和给定F, 现在在哪里和例如,不一定是随机系统的结果,而可能是一个假设,或者实际上是调查人员不知道的任何特征。在统计应用中和通常是关于未知参数的一些陈述θ或更具体地说,关于感兴趣的参数ψ. 现在
讨论主要限于这种情况。单个数字是否可以有效地封装关于粒子物理学基础理论正确性的不确定性的问题远远超出了本讨论的范围。也许,它可以应用于更具体的问题,例如对基本理论的预测:到 2010 年会发现希格斯玻色子吗?
一个扩展的概率概念旨在解决这一点,即在解释数据时,除了狭义统计可变性引起的不确定性之外,还经常存在不确定性来源。在频率论方法中,这些方面,例如可能的系统测量误差,通常通过正式或非正式的敏感性分析来定性地解决,而不是纳入概率评估中。
统计代写|统计推断作业代写statistics interference代考|Frequentist interpretation of upper limits
首先,我们考虑例如从合适的支点获得的上限的常客解释。我们采用最简单的例子,例 1.1,即方差已知时的正态均值,但考虑相当普遍。上限
是¯+到Cσ0/n,这里从概率陈述中得出磷(μ<是¯+到Cσ0/n)=1−C,
是假设的长期陈述的特定实例 比例1−C当然,假设我们的模型是合理的,这将是正确的。至少在原则上,我们可以为每个C从而生成一组语句,有时称为置信度分布。没有单一的限制C,只要一些兼容性要求成立。
因为这具有分布的形式属性μRA Fisher 将其称为基准分布,有时也称为基准概率分布。一个关键问题是这个分布是否可以像普通概率分布一样被解释和操纵。职位是:
- 一组限制μ从某些数据中可以在某些方面被认为就像一个概率陈述μ;
- 这种概率陈述通常不能被概率法则组合或操纵来评估,例如,μ超过某个给定的常数,例如零。在目前的情况下,这显然是非法的。
也就是说,作为一个单一的陈述1−C上限具有陈述概率系统中唯一事件的证据力。但一般来说,操纵概率的规则并不适用。当然,这些限制直接基于概率计算。
然而,将关于参数的置信区间陈述视为在某些方面类似于概率陈述的处理包含了重要的见解,即在推断正态均值时,未知参数更可能靠近区间中心而不是接近端点,并且只要模型合理合适,如果平均值在区间之外,它不太可能在区间之外很远。
以这种方式定义的上限集合并不能确定概率分布的更强有力的证明是表明,如果将在一个分析阶段确定的正式分布用作第二阶段的输入,则通常存在不一致。概率计算。我们不会提供细节;见注 5.2。
以下示例以非常简单的形式说明了从对数据的假设(给定模型)到对模型的推断(给定数据)所需的谨慎,特别是通过将此类陈述视为概率陈述可能得出的错误结论。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。统计代写|python代写代考
随机过程代考
在概率论概念中,随机过程是随机变量的集合。 若一随机系统的样本点是随机函数,则称此函数为样本函数,这一随机系统全部样本函数的集合是一个随机过程。 实际应用中,样本函数的一般定义在时间域或者空间域。 随机过程的实例如股票和汇率的波动、语音信号、视频信号、体温的变化,随机运动如布朗运动、随机徘徊等等。
贝叶斯方法代考
贝叶斯统计概念及数据分析表示使用概率陈述回答有关未知参数的研究问题以及统计范式。后验分布包括关于参数的先验分布,和基于观测数据提供关于参数的信息似然模型。根据选择的先验分布和似然模型,后验分布可以解析或近似,例如,马尔科夫链蒙特卡罗 (MCMC) 方法之一。贝叶斯统计概念及数据分析使用后验分布来形成模型参数的各种摘要,包括点估计,如后验平均值、中位数、百分位数和称为可信区间的区间估计。此外,所有关于模型参数的统计检验都可以表示为基于估计后验分布的概率报表。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
statistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
机器学习代写
随着AI的大潮到来,Machine Learning逐渐成为一个新的学习热点。同时与传统CS相比,Machine Learning在其他领域也有着广泛的应用,因此这门学科成为不仅折磨CS专业同学的“小恶魔”,也是折磨生物、化学、统计等其他学科留学生的“大魔王”。学习Machine learning的一大绊脚石在于使用语言众多,跨学科范围广,所以学习起来尤其困难。但是不管你在学习Machine Learning时遇到任何难题,StudyGate专业导师团队都能为你轻松解决。
多元统计分析代考
基础数据: $N$ 个样本, $P$ 个变量数的单样本,组成的横列的数据表
变量定性: 分类和顺序;变量定量:数值
数学公式的角度分为: 因变量与自变量
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。