如果你也在 怎样代写Probabilistic Reasoning With Bayesian Networks这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
贝叶斯网络默认是概率性的,并且 “原生 “处理不确定性。贝叶斯网络模型可以直接处理概率输入和概率关系,并提供正确计算的概率输出。
statistics-lab™ 为您的留学生涯保驾护航 在代写 Probabilistic Reasoning With Bayesian Networks方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写CMPT 310 Probabilistic Reasoning With Bayesian Networks方面经验极为丰富,各种代写 Probabilistic Reasoning With Bayesian Networks相关的作业也就用不着说。
我们提供的Probabilistic Reasoning With Bayesian Networks及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|贝叶斯网络概率解释代写Probabilistic Reasoning With Bayesian Networks代考|Stochastic process with exogenous constraint
As shown in [WEB 04], a hidden Markov model (HMM) [RAB 89] can represent the degradation of components. The modeling of component degradation by HMM has also been used in [MOG 12, ROB 13, LE 14].
Time is usually considered as a conditional factor in component reliability, as shown in the previous section. It can be insufficient [SIN 95]. The conditions of use and the environmental context (like humidity, temperature, etc.) can alter the component reliability. All factors that alter component reliability are called co-variables or exogenous variables [BAG 01]. As described in [COX 55], the component reliability can be modeled precisely by taking into account the effects of exogenous variables.
In [WEB 04], several models of MC are defined according to the operational context of the component. A Markov switching model (MSM) is introduced to model the switching from one MC to another subsequent to the state variation of the exogenous variables. These models are also considered as conditional $\mathrm{MC}$ where the transitions are conditional to exogenous variables.
The MSM models are non-stationary because of the fast modifications of parameter values [BEN 99, p. 147]. A MSM represents the conditional distribution $P\left(x_{i}^{(k)}, u_{i}^{(k)}\right)$ given the input state sequence $\left(u_{i}^{(0)}, u_{i}^{(1)}, \ldots u_{i}^{(k)}\right)$, where $u_{i}^{(k)}$ represents the state of the exogenous variable. The simulation of the MSM is based on discontinuous changes of parameters associated with each modification of the exogenous variable state. It is very hard to obtain an analytical solution as with MC, and it is quite simple to use a simulation.
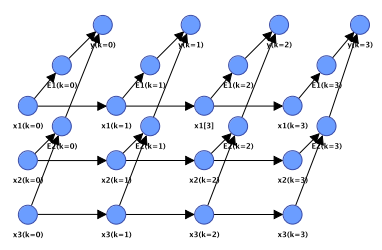
The modeling solution by a DBN is really simple [WEB 04]. One or several exogenous variables modeling the constraints or the operational conditions are added as new discrete variables $u_{i}^{(k)}$ in the time slice $k$. The CPT that defines the transition between two consecutive time steps, $x_{i}^{(k+1)} \mid x_{i}^{(k)}$, is defined conditional on $u_{i}^{(k)}$, as shown in Figure $4.5$ for one variable.
统计代写|贝叶斯网络概率解释代写Probabilistic Reasoning With Bayesian Networks代考|Model of a dynamic multi-state system
A DBN is particularly interesting when dealing with several components in a system. The DBN presented in section $4.2$ allows us to represent several multi-state stochastic processes in a system model. A multi-state model, as presented in Chapter 3 , can easily combine the models of dynamic multi-state components as presented in section $4.2$
to give a whole model of the dynamic multi-state system. The computation in a DBN with several stochastic processes is solved by different inference mechanisms well suited to this problem and to the conditions of use of the models.
The exact inference algorithms are based on a junction tree [JEN 96]. This mechanism is applied to unroll up models. If all time slices are defined in the model, then the usual inference algorithm can be used to compute the exact results (Figure 4.8) but with high computation costs. The models can be of high complexity with much dependence between the components (Figure 4.9) and thus are not practical for such a modeling step. Moreover, they are not adapted for a large time horizon.
统统计代写|贝叶斯网络概率解释代写Probabilistic Reasoning With Bayesian Networks代考|Discussion on dependent processes
The components of systems are not always independant. To decrease the model complexity in the case of dependent processes, it is possible to mix the dependent components in only one stochastic process that is combined with other independent processes by a multi-state BN, as shown previously. According to this method, the
DBN models only independent processes. The whole structure of the global system is then simplified, but the number of states of some variables increases.
Nevertheless if some dependence exists between stochastic processes, as in the roll up of DBN shown in Figure 4.9, it is necessary to use a specific inference algorithm that computes the joint distribution at each time step with significant computing and memory costs. The approximate inference algorithm proposed by [BOY 98, KOL 99] or particular filtering [KOL 00] can estimate the marginal distribution with a bounded error, which is often sufficient for dependability purposes.Unfortunately, another phenomenon introduces difficulties in computing the marginal distribution even in the case of the independent structure shown in Figure 4.10. In the analysis of the functioning scenarios, it is of interest to integrate observations or evidence like events in the DBN. If evidence about a component is introduced in the DBN for a state variable $x_{i}^{(k)}$ or an exogenous variable $u_{i}^{(k)}$, the inference is correct until the processes are independent. However, if evidence is introduced on a variable, for instance $y_{i}^{(k+1)}$, and this evidence introduces a dependence between the variables $x_{i}^{(k+1)}$, then a computing problem appears. This dependence requires the use of specific algorithms. So, it is necessary to be cautious when using DBN and evidence to compute the distributions correctly by considering the right hypothesis.
贝叶斯网络代写
统计代写|贝叶斯网络概率解释代写Probabilistic Reasoning With Bayesian Networks代考|Stochastic process with exogenous constraint
如 [WEB 04] 所示,隐马尔可夫模型 (HMM) [RAB 89] 可以表示组件的退化。HMM 对组件退化的建模也已在 [MOG 12, ROB 13, LE 14] 中使用。
如上一节所示,时间通常被认为是组件可靠性的一个条件因素。它可能是不够的 [SIN 95]。使用条件和环境(如湿度、温度等)会改变组件的可靠性。所有改变组件可靠性的因素都称为协变量或外生变量 [BAG 01]。如 [COX 55] 中所述,组件可靠性可以通过考虑外生变量的影响来精确建模。
在 [WEB 04] 中,根据组件的操作上下文定义了几种 MC 模型。引入马尔可夫切换模型 (MSM) 来模拟在外生变量的状态变化之后从一个 MC 到另一个 MC 的切换。这些模型也被认为是有条件的米C其中转换以外生变量为条件。
由于参数值的快速修改,MSM 模型是非平稳的 [BEN 99, p. 147]。MSM 表示条件分布磷(X一世(ķ),在一世(ķ))给定输入状态序列(在一世(0),在一世(1),…在一世(ķ)), 在哪里在一世(ķ)表示外生变量的状态。MSM 的模拟基于与外生变量状态的每次修改相关的参数的不连续变化。使用 MC 很难获得解析解,使用模拟非常简单。
DBN 的建模解决方案非常简单 [WEB 04]。添加一个或多个对约束或操作条件进行建模的外生变量作为新的离散变量在一世(ķ)在时间片ķ. 定义两个连续时间步长之间转换的 CPT,X一世(ķ+1)∣X一世(ķ), 定义为在一世(ķ),如图4.5对于一个变量。
统计代写|贝叶斯网络概率解释代写Probabilistic Reasoning With Bayesian Networks代考|Model of a dynamic multi-state system
DBN 在处理系统中的多个组件时特别有趣。部分介绍的 DBN4.2允许我们在系统模型中表示几个多状态随机过程。第 3 章中介绍的多状态模型可以很容易地组合第 3 章中介绍的动态多状态组件模型4.2
给出动态多状态系统的整体模型。具有多个随机过程的 DBN 中的计算通过非常适合该问题和模型使用条件的不同推理机制来解决。
精确的推理算法基于连接树 [JEN 96]。此机制适用于展开模型。如果在模型中定义了所有时间片,则可以使用通常的推理算法来计算精确的结果(图 4.8),但计算成本很高。这些模型可能具有很高的复杂性,并且组件之间存在很大的依赖性(图 4.9),因此对于这样的建模步骤是不切实际的。此外,它们不适用于大的时间范围。
统统计代写|贝叶斯网络概率解释代写Probabilistic Reasoning With Bayesian Networks代考|Discussion on dependent processes
系统的组件并不总是独立的。为了在依赖过程的情况下降低模型复杂性,可以将依赖组件混合在一个随机过程中,该随机过程通过多状态 BN 与其他独立过程相结合,如前所示。根据这种方法,
DBN 仅对独立进程建模。然后全局系统的整个结构被简化,但是一些变量的状态数量增加了。
然而,如果随机过程之间存在某种依赖关系,如图 4.9 所示的 DBN 汇总,则有必要使用特定的推理算法来计算每个时间步的联合分布,计算和内存成本很高。[BOY 98, KOL 99] 或特定过滤 [KOL 00] 提出的近似推理算法可以估计有界误差的边际分布,这通常足以达到可靠性目的。不幸的是,另一种现象即使在计算边际分布时也会遇到困难在图 4.10 所示的独立结构的情况下。在分析功能场景时,将观察或证据(如 DBN 中的事件)整合起来是很有意义的。如果在 DBN 中为状态变量引入有关组件的证据X一世(ķ)或外生变量在一世(ķ),推理是正确的,直到过程是独立的。但是,如果在变量上引入证据,例如是一世(ķ+1), 这个证据引入了变量之间的依赖关系X一世(ķ+1),然后出现计算问题。这种依赖需要使用特定的算法。因此,在使用 DBN 和证据通过考虑正确的假设来正确计算分布时必须谨慎。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。统计代写|python代写代考
随机过程代考
在概率论概念中,随机过程是随机变量的集合。 若一随机系统的样本点是随机函数,则称此函数为样本函数,这一随机系统全部样本函数的集合是一个随机过程。 实际应用中,样本函数的一般定义在时间域或者空间域。 随机过程的实例如股票和汇率的波动、语音信号、视频信号、体温的变化,随机运动如布朗运动、随机徘徊等等。
贝叶斯方法代考
贝叶斯统计概念及数据分析表示使用概率陈述回答有关未知参数的研究问题以及统计范式。后验分布包括关于参数的先验分布,和基于观测数据提供关于参数的信息似然模型。根据选择的先验分布和似然模型,后验分布可以解析或近似,例如,马尔科夫链蒙特卡罗 (MCMC) 方法之一。贝叶斯统计概念及数据分析使用后验分布来形成模型参数的各种摘要,包括点估计,如后验平均值、中位数、百分位数和称为可信区间的区间估计。此外,所有关于模型参数的统计检验都可以表示为基于估计后验分布的概率报表。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
statistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
机器学习代写
随着AI的大潮到来,Machine Learning逐渐成为一个新的学习热点。同时与传统CS相比,Machine Learning在其他领域也有着广泛的应用,因此这门学科成为不仅折磨CS专业同学的“小恶魔”,也是折磨生物、化学、统计等其他学科留学生的“大魔王”。学习Machine learning的一大绊脚石在于使用语言众多,跨学科范围广,所以学习起来尤其困难。但是不管你在学习Machine Learning时遇到任何难题,StudyGate专业导师团队都能为你轻松解决。
多元统计分析代考
基础数据: $N$ 个样本, $P$ 个变量数的单样本,组成的横列的数据表
变量定性: 分类和顺序;变量定量:数值
数学公式的角度分为: 因变量与自变量
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。