如果你也在 怎样代写金融计量经济学Financial Econometrics这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
金融计量学是将统计方法应用于金融市场数据。金融计量学是金融经济学的一个分支,在经济学领域。研究领域包括资本市场、金融机构、公司财务和公司治理。
statistics-lab™ 为您的留学生涯保驾护航 在代写金融计量经济学Financial Econometrics方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写金融计量经济学Financial Econometrics代写方面经验极为丰富,各种代写金融计量经济学Financial Econometrics相关的作业也就用不着说。
我们提供的金融计量经济学Financial Econometrics及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
金融代写|金融计量经济学Financial Econometrics代考|Aspects of Information Quality
The view of information quality differs, depending on the domain of application and the kind of business generated by using data science (Batini and Scannapieco 2016 ; Capet and Revault d’Allonnes 2013; Revault d’Allonnes 2013; Lesot and Revault d’Allonnes 2017). The concept is complex and based on many components. Data quality has always been a major issue in databases, information systems and risk forecasting. The difficulties are accentuated in the environment of big data.
There exists a jungle of definitions of information quality and proposals of solutions in the framework of data mining and data science. In this jungle, you can recognize different aspects of information quality. Relevance, appropriateness, accessibility, compatibility correspond to the good matching between the retrieved information and the expectation of the user. Understandability, expressiveness describe the capacity of the system to speak a language familiar to the user. Accuracy may be necessary in specific domains. Comprehensibility, consistency, coherence, completeness represent the quality of the set of information as a whole. Timeliness, operationality, security are technical qualities. Veracity, validity, trust, reliability, plausibility, credibility represent various means to define the confidence the user can have in the obtained information.
The factors of information quality are dependent on the nature of sources, that can be news streams, databases, open source data, sensor records or social networks. They are also dependent on the form of data, for instance text, images, videos, temporal series, graphs or database records. The evaluation of information quality is also relatę to the expectations of the end usêr and purposes of the informaation extraction, the requirement of accuracy, for instance, not being the same in finance or for a student preparing a report.
To describe the chaining in the information quality components, we can consider that the source quality has an influence on data quality, which is one of the factors of information quality, as well as the artificial intelligence-based model quality. Finally, the user satisfaction rests on both information quality and model quality. To illustrate the diversity of views of information quality according to the considered domain of application, we can roughly consider that specialists of business intelligence and intelligence services pay a great attention to source quality, while financial engineering and econometrics are focused on data quality. In medical diagnosis, the quality of the model is very important to explain the diagnosis, whereas information retrieval is centered on global information quality. The user satisfaction is a priority for domains such as social networks or targeted advertising.
Each of these constituents of what we can call global information quality requires appropriate solutions to the best possible. In the following. we focus on fuzzy setbased solutions, among all those provided in computational intelligence, thanks to the capacity of fuzzy systems to handle uncertainties, imprecisions, incompleteness and reliability degrees in a common environment. The diversity of aggregation methods available for the fusion of elements and the richness of measures of similarity are additional reasons to choose fuzzy methods.
金融代写|金融计量经济学Financial Econometrics代考|Fuzzy Solutions to Data Quality Problems
Defaults in data quality are the most primary among the problems occurring in information quality, and they have been studied for years, in particular in databases (Ananthakrishna et al. 2002; Janta-Polczynski and Roventa 1999) and more generally in products and services (Loshin 2011). Accuracy, completeness and consistency of data (Huh et al. 1990) have always been major concerns in industrial products.
In the modern environments, it is necessary to have a more general approach of data quality and to consider both intrinsic and extrinsic factors. The former include defaults such as imprecision, measurement errors, vague linguistic descriptions, incompleteness, inaccuracies, inconsistencies and discrepancies in data elements. The latter mainly refers to insufficient trustworthiness of sources and inconsistency between various sources.
A general analysis of data quality is proposed in Pipino et al. (2002) by means of objective and subjective assessments of data quality. The question of measuring the quality of data is addressed in Bronselaer et al. $(2018 \mathrm{a}, \mathrm{b})$ through the presentation of a measure-theoretic foundation for data quality and the proposal of an operational measurement.
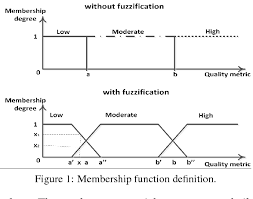
A fuzzy set-based knowledge representation is of course an interesting solution to the existence of inaccuracies, vagueness and incompleteness, as well as the necessary bridge between linguistic and numerical values.
The issue of incomplete data is very frequent in all environments, for various reasons such as the absence of answer to a specific request, the impossibility to obtain a measurement, a loss of pieces of information or the necessity to hide some elements to protect privacy. Various fuzzy methods have been proposed for the imputation of missing values, based on very different techniques. For instance, a fuzzy K-means clustering algorithm is used in Liao et al. (2009) and Li et al. (2004), a neuro-fuzzy $\mathrm{~ c l a ̊ s s i f i e r ~ i s ~ p r o p o ̄ o s e d ~ i n ~ G a ̉ b r y s ~ ( 2 0 0 2 ) , ~ e v o o l u t i o n a ̆ r y ~ f u z z y ~ s o ̄ l u t i o n s ~ a a r e ~ i n v e}$ in Carmona et al. (2012). Rough fuzzy sets are incorporated in a neuro-fuzzy structure to cope with missing data in Nowicki (2009). Various types of fuzzy rule-based classification systems are studied in Luengo et al. (2012) to overcome the problem of missing data. Missing pixels in images are also managed by means of fuzzy methods, for instance with the help of an intuitionistic fuzzy C-means clustering algorithm in Balasubramaniam and Ananthi (2016). All these works exemplify the variety of solutions available in a fuzzy setting.
金融代写|金融计量经济学Financial Econometrics代考|Fuzzy Approaches to Other Information Quality
Information is extracted from data by means of an artificial intelligence engine and it is supposed to fulfill users’ needs. The expected level of quality of information is different, depending on the purpose of information extraction. In information retrieval, the challenge is to find images, texts or videos corresponding to a user’s query and the information quality reflects the adequacy and completeness of the obtained information. In domains such as prevision, prediction, risk or trend forecasting, the quality of information is evaluated on the basis of the comparison between the forecasting and the real world. In real time decision making, where a diagnosis or a solution to a problem must be provided rapidly, the completeness and accuracy of information is crucial. In cases where data must be analyzed instantaneously to act on a system, for instance in targeted advertising, adaptive interfaces or online sales, the timeliness and operationality are more important than the accuracy. In business intelligence or e-reputation analysis, where opinions, blogs or customer’s evaluations are analyzed, the trustworthiness of information is crucial.
We propose to structure the analysis of information quality along three main dimensions, namely the relevance of information, its trust or veracity, and its understandability.
金融计量经济学代考
金融代写|金融计量经济学Financial Econometrics代考|Aspects of Information Quality
对信息质量的看法因应用领域和使用数据科学产生的业务类型而异(Batini 和 Scannapieco 2016;Capet 和 Revault d’Allonnes 2013;Revault d’Allonnes 2013;Lesot 和 Revault d’Allonnes 2017 )。这个概念很复杂,并且基于许多组件。数据质量一直是数据库、信息系统和风险预测的主要问题。在大数据环境下,这些困难更加突出。
在数据挖掘和数据科学的框架中,存在着信息质量的定义和解决方案建议的丛林。在这个丛林中,您可以识别信息质量的不同方面。相关性、适当性、可访问性、兼容性对应于检索到的信息与用户期望之间的良好匹配。可理解性、表达性描述了系统说出用户熟悉的语言的能力。在特定领域可能需要准确性。可理解性、一致性、连贯性、完整性代表了整个信息集的质量。及时性、可操作性、安全性是技术品质。真实性、有效性、可信度、可靠性、合理性,
信息质量的因素取决于来源的性质,可以是新闻流、数据库、开源数据、传感器记录或社交网络。它们还依赖于数据的形式,例如文本、图像、视频、时间序列、图表或数据库记录。信息质量的评估也与最终用户的期望和信息提取的目的、准确性的要求有关,例如,在金融或准备报告的学生中不同。
为了描述信息质量组件中的链接,我们可以认为源质量对数据质量有影响,数据质量是信息质量的因素之一,也是基于人工智能的模型质量。最后,用户满意度取决于信息质量和模型质量。为了说明根据所考虑的应用领域对信息质量的看法的多样性,我们可以粗略地认为,商业智能和情报服务专家非常关注源质量,而金融工程和计量经济学则关注数据质量。在医学诊断中,模型的质量对于解释诊断非常重要,而信息检索则以全局信息质量为中心。
我们可以称之为全球信息质量的这些组成部分中的每一个都需要适当的解决方案以达到最佳状态。在下面的。我们专注于基于模糊集的解决方案,在计算智能中提供的所有解决方案中,这要归功于模糊系统在通用环境中处理不确定性、不精确性、不完整性和可靠性程度的能力。可用于元素融合的聚合方法的多样性和相似性度量的丰富性是选择模糊方法的额外原因。
金融代写|金融计量经济学Financial Econometrics代考|Fuzzy Solutions to Data Quality Problems
数据质量默认值是信息质量问题中最主要的问题,并且已经研究了多年,特别是在数据库中(Ananthakrishna 等人 2002;Janta-Polczynski 和 Roventa 1999),更普遍的是在产品和服务中(洛欣 2011)。数据的准确性、完整性和一致性(Huh et al. 1990)一直是工业产品的主要关注点。
在现代环境中,有必要采用更通用的数据质量方法并同时考虑内在和外在因素。前者包括默认值,例如不精确、测量错误、模糊的语言描述、不完整、不准确、数据元素的不一致和差异。后者主要是指来源的可信度不足和各种来源之间的不一致。
Pipino 等人提出了对数据质量的一般分析。(2002 年)通过对数据质量的客观和主观评估。Bronselaer 等人解决了衡量数据质量的问题。(2018一个,b)通过介绍数据质量的测量理论基础和操作测量的建议。
基于模糊集的知识表示当然是解决不准确、模糊和不完整问题的有趣解决方案,也是语言和数值之间必要的桥梁。
数据不完整的问题在所有环境中都非常常见,原因有多种,例如没有对特定请求的回答、无法获得测量结果、丢失信息或需要隐藏某些元素以保护隐私。基于非常不同的技术,已经提出了各种模糊方法来估算缺失值。例如,Liao 等人使用了模糊 K 均值聚类算法。(2009)和李等人。(2004),神经模糊̉ Cl一个̊ss一世F一世和r 一世s pr○p○̄○s和d 一世n G一个̉br是s (2002), 和在○○l在吨一世○n一个̆r是 F在和和是 s○̄l在吨一世○ns 一个一个r和 一世n在和在卡莫纳等人。(2012)。在 Nowicki (2009) 中,粗糙的模糊集被合并到一个神经模糊结构中来处理缺失的数据。Luengo 等人研究了各种类型的基于模糊规则的分类系统。(2012)克服数据缺失的问题。图像中丢失的像素也通过模糊方法进行管理,例如在 Balasubramaniam 和 Ananthi (2016) 中的直觉模糊 C 均值聚类算法的帮助下。所有这些作品都举例说明了模糊设置中可用的各种解决方案。
金融代写|金融计量经济学Financial Econometrics代考|Fuzzy Approaches to Other Information Quality
信息是通过人工智能引擎从数据中提取出来的,它应该满足用户的需求。信息质量的预期水平是不同的,这取决于信息提取的目的。在信息检索中,挑战在于找到与用户查询相对应的图像、文本或视频,信息质量反映了所获取信息的充分性和完整性。在预测、预测、风险或趋势预测等领域,信息的质量是根据预测与现实世界之间的比较来评估的。在必须快速提供问题诊断或解决方案的实时决策中,信息的完整性和准确性至关重要。在必须立即分析数据以对系统起作用的情况下,例如在定向广告、自适应界面或在线销售中,及时性和可操作性比准确性更重要。在商业智能或电子声誉分析中,在分析意见、博客或客户评价时,信息的可信度至关重要。
我们建议从三个主要维度构建信息质量分析,即信息的相关性、信息的可信度或真实性以及信息的可理解性。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。