如果你也在 怎样代写应用统计applied statistics这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
应用统计学包括计划收集数据,管理数据,分析、解释和从数据中得出结论,以及利用分析结果确定问题、解决方案和机会。本专业培养学生在数据分析和实证研究方面的批判性思维和解决问题的能力。
statistics-lab™ 为您的留学生涯保驾护航 在代写应用统计applied statistics方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写应用统计applied statistics代写方面经验极为丰富,各种代写应用统计applied statistics相关的作业也就用不着说。
我们提供的应用统计applied statistics及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础

统计代写|应用统计代写applied statistics代考|aka Thoughts on Proper Data Analysis
Before we embark on the journey that is learning $R$ and how to use it to analyze your data and make fantastic figures, it is useful to stop and think a little bit about best practices for data analysis.
$2.2$ BASIC PRINCIPLES OF EXPERIMENTAL DESIGN
If there are three words to remember when thinking about experimental design, they are balance, randomization, and replication. In a nutshell, what you are trying to prevent with these three factors is your data being correlated in some way that is unhelpful to your analysis. You are also trying to ensure that your data are independent from one another and that you have enough data to actually determine if your treatments did anything or not (see Boxes 2.1, 2.2, and 2.3).
Obviously, it is not always possible to control these aspects of your data, particularly if you have observational data (as compared to a controlled experiment which you design and run yourself). But, even in the case of observational studies, these principles are important to keep in mind and consider.
统计代写|应用统计代写applied statistics代考|BLOCKED EXPERIMENTAL DESIGNS
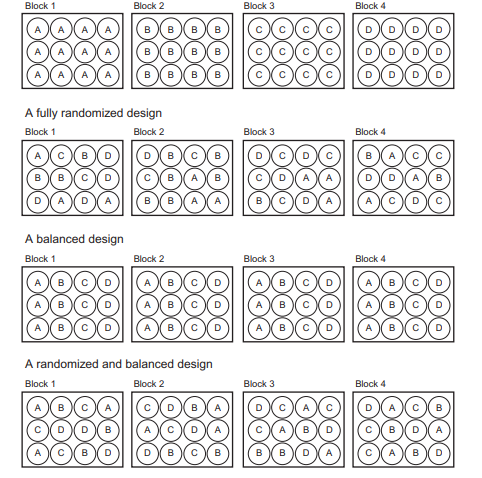
Consider the four experimental setups shown in Figure 2.1. Imagine that we are now testing the effects of four fertilizers on plant growth (labelled A, B, C, and D), each with 12 individuals. The experiment is conducted in four separate “blocks” What is a block? It could be many things. Maybe it is a physical way of setting up the experiment, for example, four shelves in an incubator that contain the experimental units or four rooms that contain the cages our individuals live in. Maybe, due to space or time limitations, only 12 individuals can be tested or measured at a time, and thus the experiment has to be run four separate times. Each of these can be considered a “block” so you can hopefully imagine how this idea relates to your own research. Blocks are only important to consider if there is some systematic difference among them.
In the first example, the four treatments will be perfectly correlated with the four blocks. Thus, if we imagine a significant difference is detected in one treatment, there is no way to know if it is because of the experimental treatment or if there was something else going on in that block (or room, or time point, or whatever you want to imagine that block represents). Once again, this is an example of pseudoreplication because it seems like we have a large sample size but in reality, we have a sample size of $\mathrm{N}=1$ in each of our treatments. Despite growing 48 different plants, this design is unreplicated.
The second example is a fully randomized design, where the four treatments are allocated across the four blocks completely at random. The third example is a fully balanced design, where each of the four treatments is assigned to each block in the same manner. Each of these setups has its own advantages and disadvantages.
The fully randomized design is good, and in theory should lead to the highest degree of replication, with all experimental units being truly independent. In reality it can actually work against the principle of balance, since some treatments might end up overrepresented in some blocks and underrepresented in others (e.g., in Figure 2.1, there are six individuals from treatment B in Block 2, but only one in Block 3). In the extreme, leaving your entire setup to random chance could lead to a horribly unbalanced and biased design, but this would be very rare. In general, fully randomizing your experiment is a very good idea!
统计代写|应用统计代写applied statistics代考|YOU CAN (AND SHOULD) PLAN YOUR ANALYSES BEFORE YOU HAVE THE DATA!
In addition to the aspects of experimental design described previously, the other most important thing to do is to have a clear idea of your predictor and response variables before you even start the experiment. Before you ever put a mouse in a testing box or a seed in growth chamber, you should identify what it is you are going to measure. Hopefully, if you know your study system pretty well or perhaps have some preliminary data, you can estimate what the data are going look like which will allow you to think about and plan for what type of analyses you will do. Maybe that sounds like wishful thinking, but this whole book is about the importance of knowing what your data look like, so don’t worry-you’ll get there!
Sir Ronald Fisher, one of the founders of modern statistics, offered one of the best statements about this issue in $1938 .$ Fisher’s point is that because your experimental design directly effects your data analysis, you should think about your analysis up front when planning the experiment.
应用统计代写
统计代写|应用统计代写applied statistics代考|aka Thoughts on Proper Data Analysis
在我们踏上学习之旅之前R以及如何使用它来分析您的数据并制作出色的数字,停下来思考一下数据分析的最佳实践是很有用的。
2.2实验设计的基本原则
如果在考虑实验设计时要记住三个词,它们是平衡、随机化和复制。简而言之,您试图通过这三个因素来防止您的数据以某种对您的分析无益的方式相关联。您还试图确保您的数据彼此独立,并且您有足够的数据来实际确定您的治疗是否有任何作用(参见方框 2.1、2.2 和 2.3)。
显然,控制数据的这些方面并不总是可能的,特别是如果您有观察数据(与您自己设计和运行的受控实验相比)。但是,即使在观察性研究的情况下,这些原则也很重要,需要牢记和考虑。
统计代写|应用统计代写applied statistics代考|BLOCKED EXPERIMENTAL DESIGNS
考虑图 2.1 中所示的四个实验设置。想象一下,我们现在正在测试四种肥料对植物生长的影响(标记为 A、B、C 和 D),每种有 12 个人。实验在四个独立的“块”中进行 什么是块?这可能是很多事情。也许这是一种物理的实验设置方式,例如,一个孵化器中的四个架子包含实验单元,或者四个房间包含我们个人居住的笼子。也许,由于空间或时间的限制,只有 12 个人可以一次测试或测量,因此实验必须单独运行四次。每一个都可以被认为是一个“块”,所以你可以想象这个想法与你自己的研究有什么关系。只有在它们之间存在一些系统差异时,才需要考虑块。
在第一个示例中,四种处理将与四个块完全相关。因此,如果我们想象在一种治疗中检测到显着差异,则无法知道这是因为实验性治疗还是在那个街区(或房间,或时间点,或任何你想想象那个块代表)。再一次,这是一个伪复制的例子,因为看起来我们的样本量很大,但实际上,我们的样本量为ñ=1在我们的每一次治疗中。尽管种植了 48 种不同的植物,但这种设计是不可复制的。
第二个示例是完全随机设计,其中四种处理完全随机分配到四个块中。第三个示例是完全平衡的设计,其中四种处理中的每一种都以相同的方式分配给每个区组。这些设置中的每一个都有其自身的优点和缺点。
完全随机的设计是好的,理论上应该导致最高程度的复制,所有实验单元都是真正独立的。实际上,它实际上可能违反平衡原则,因为某些治疗可能最终在某些区块中代表性过高而在其他区块中代表性不足(例如,在图 2.1 中,在区块 2 中有六个来自治疗 B 的个体,但在区块 3 中只有一个)。在极端情况下,将整个设置留给随机机会可能会导致严重的不平衡和有偏见的设计,但这非常罕见。一般来说,完全随机化你的实验是一个非常好的主意!
统计代写|应用统计代写applied statistics代考|YOU CAN (AND SHOULD) PLAN YOUR ANALYSES BEFORE YOU HAVE THE DATA!
除了前面描述的实验设计方面,另一个最重要的事情是在开始实验之前清楚地了解您的预测变量和响应变量。在将鼠标放入测试盒或将种子放入生长室之前,您应该确定要测量的是什么。希望如果您非常了解您的研究系统或者可能有一些初步数据,您可以估计数据的样子,这将使您能够思考和计划您将进行的分析类型。也许这听起来像是一厢情愿,但整本书都是关于了解您的数据是什么样子的重要性,所以不要担心 – 你会到达那里!
现代统计学的奠基人之一罗纳德·费舍尔爵士(Sir Ronald Fisher)在1938. Fisher 的观点是,因为您的实验设计直接影响您的数据分析,所以您应该在计划实验时预先考虑您的分析。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。