如果你也在 怎样代写数据科学data science这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
数据科学是一个跨学科领域,它使用科学方法、流程、算法和系统从嘈杂的、结构化和非结构化的数据中提取知识和见解,并在广泛的应用领域应用数据的知识和可操作的见解。
statistics-lab™ 为您的留学生涯保驾护航 在代写数据科学data science方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写数据科学data science方面经验极为丰富,各种代写数据科学data science相关的作业也就用不着说。
我们提供的数据科学data science及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|数据科学代写data science代考|Neural Network Models and Applications
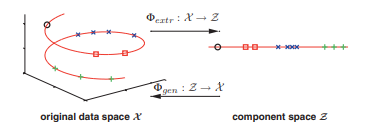
Many natural phenomena behave in a nonlinear way meaning that the observed data describe a curve or curved subspace in the original data space. Identifying such nonlinear manifolds becomes more and more important in the field of molecular biology. In general, molecular data are of very high dimensionality because of thousands of molecules that are simultaneously measured at a time. Since the data are usually located within a low-dimensional subspace, they can be well described by a single or low number of components. Experimental time course data are usually located within a curved subspace which requires a nonlinear dimensionality reduction as illustrated in Fig. 2.1.
Visualising the data is nne aspert of molecnlar data analysis, another important aspẹct is to módel the mapping from original epace to component
Fig. 2.1. Nonlinear dimensionality reduction. Illustrated are threedimensional samples that are located on a one-dimensional subspace, and hence can be described without loes of informution by a vingle variable (the component). The transformation is given by the two functions $\Phi_{\text {extr }}$ and $\Phi_{\text {gen. }}$. The extraction funccomponent value (right). The inverse mapping is given by the generation function $\Phi_{g e n}$ which transforms any scalar component value back into the original data space. Such helical trajectory over time is not uncommon in molecular data. The horizontal axes may represent molecule concentrations driven by a circadian rhythm, whereas the vertical axis might represent a molecule with an increase in concentration
space in order to interpret the impact of observed variables on the subspace (component space). Both the component values (scores) and the mapping function is provided by the neural network approach for nonlinear PCA.
Three important extensions of nonlinear $\mathrm{PCA}$ are discussed in this chapter: the hierarchical NLPCA, the circular PCA, and the inverse NLPCA. All of them can be used in combination. Hierarchical NLPCA means to enforce the nonlinear components to have the same hierarchical order as the linear components of standard PCA. This hierarchical condition yields a higher meaning of individual components. Circular $P C A$ enables nonlinear PCA to extract circular components which describe a closed curve instead of the standard curve with an open interval. This is very useful for analysing data from cyclic or oscillatory phenomena. Inverse $N L P C A$ defines nonlinear $\mathrm{PCA}$ as an inverse problem, where only the assumed data generation process is modelled, which has the advantage that more complex curves can be identified and NLPCA becomes applicable to incomplete data sets.
统计代写|数据科学代写data science代考|Bibliographic notes
Nonlinear PCA based on autoassociative neural networks was investigated in several studies $[1-4]$. Kirby and Miranda [5] constrained network units to work in a circular manner resulting in a circular $P C A$ whose components are closed curves. In the fields of atmospheric and oceanic sciences, circular PCA is applied to oscillatory geophysical phenomena, for example, the oceanatmosphere El Niño-Southern oscillation [6] or the tidal cycle at the German North Sea coast [7]. There are also applications in the field of robotics in
order to analyse and control periodic movements [8]. In molecular biology, circular PCA is used for gene expression analysis of the reproductive cycle of the malaria parasite Plasmodium falciparum in red blood cells $[9]$. Scholz and Vigário [10] proposed a hienanchical nonlinear $P C A$ which achieves a hierarchical order of nonlinear components similar to standard linear $\mathrm{PCA}$. This hierarchical NLPCA was applied to spectral data of stars and to electromyographic (EMG) recordings of muscle activities. Neural network models for inverse $N L P C A$ were first studied in $[11,12]$. A more general Bayesian framework based on such inverse network architecture was proposed by Valpola and Honkela ${13,14}$ for a nonlinear factor analysis (NFA) and a nonlinear independent factor analysis (NIFA). In $[15]$, such inverse NLPCA model was adapted to handle missing data in order to use it for molecular data analysis. It was applied to metabolite data of a cold stress experiment with the model plant A rabidopsis thaliana. Hinton and Salakhutdinov [16] have demonstrated the use of the autoassociative network architecture for visualisation and dimensionality reduction by using a special initialisation technique.
Even though the term nonlinear PCA (NLPCA) is commonly referred to as the autoassociative approach, there are many other methods which visualise data and extract components in a nonlinear manner. Locally linear embedding (LLE) $[17,18]$ and Isomap [19] were developed to visualise high dimensional data by projecting (embedding) them into a two or low-dimensional space, but the mapping function is not explicitly given. Principal curves [20] and self organising maps (SOM) [21] are useful for detecting nonlinear curves and two-dimensional nonlinear planes. Practically both methods are limited in the number of extracted components, usually two, due to high computational costs. Kernel $P C A[22]$ is useful for visualisation and noise reduction [23].
Several efforts are made to extend independent component analysis (ICA) into a nonlinear ICA. However, the nonlinear extension of ICA is not only very challenging, but also intractable or non-unique in the absence of any a priori knowledge of the nonlinear mixing process. Therefore, special nonlinear ICA models simplify the problem to particular applications in which some information about the mixing system and the factors (source signals) is available, e.g., by using sequence information [24]. A discussion of nonlinear approaches to $\mathrm{ICA}$ can be found in $[25,26]$. This chapter focuses on the less difficult task of nonlinear PCA. A perfect nonlinear PCA should, in principle, be able to remove all nonlinearities in the data such that a standard linear ICA can be applied subsequently to achieve, in total, a nonlinear ICA. This chapter is mainly based on $[9,10,15,27]$.
统计代写|数据科学代写data science代考|Data generation and component extraction
To extract components, linear as well as nonlinear, we assume that the data are determined by a number of factors and hence can be considered as being generated from them. Since the number of varied factors is often smaller than
the number of observed variables, the data are located within a subspace of the given data space. The aim is to represent these factors by components which together describe this subspace. Nonlinear PCA is not limited to linear components, the subspace can be curved, as illustrated in Fig. 2.1.
Suppose we have a data space $\mathcal{X}$ given by the observed variables and a component space $Z$ which is a subspace of $\mathcal{X}$. Nonlinear PCA aims to provide both the subspace $\mathcal{Z}$ and the mapping between $\mathcal{X}$ and $\mathcal{Z}$. The mapping is given by nonlinear functions $\Phi_{\text {extr }}$ and $\Phi_{g e n}$. The extruction function $\Phi_{\text {extr }}: \mathcal{X} \rightarrow \mathcal{Z}$ transforms the sample coordinates $x=\left(x_{1}, x_{2}, \ldots, x_{d}\right)^{T}$ of the $d$-dimensional data space $\mathcal{X}$ into the corresponding coordinates $z=\left(z_{1}, z_{2}, \ldots, z_{k}\right)^{T}$ of the component space $\mathcal{Z}$ of usually lower dimensionality $k$. The generation function $\bar{\Phi}{g e n}: \mathcal{Z} \rightarrow \hat{\mathcal{X}}$ is the inverse mapping which reconstructs the original sample vector $x$ from their lower-dimensional component representation $z$. Thus, $\Phi{g e n}$ approximates the assumed data generation process.
数据可视化代写
统计代写|数据科学代写data science代考|Neural Network Models and Applications
许多自然现象以非线性方式表现,这意味着观察到的数据描述了原始数据空间中的曲线或弯曲子空间。识别这种非线性流形在分子生物学领域变得越来越重要。通常,由于一次同时测量数千个分子,分子数据具有非常高的维度。由于数据通常位于低维子空间中,因此可以通过单个或少量组件很好地描述它们。实验时程数据通常位于需要非线性降维的弯曲子空间内,如图 2.1 所示。
可视化数据是分子数据分析的一个重要方面,另一个重要方面是模拟从原始空间到组件的映射
图 2.1。非线性降维。说明的是位于一维子空间上的三维样本,因此可以通过 vingle 变量(分量)在没有信息的情况下进行描述。转换由两个函数给出披提取物 和披gen. . 提取 funccomponent 值(右)。逆映射由生成函数给出披G和n它将任何标量分量值转换回原始数据空间。这种随时间变化的螺旋轨迹在分子数据中并不少见。水平轴可能代表由昼夜节律驱动的分子浓度,而垂直轴可能代表浓度空间增加的分子,
以解释观察到的变量对子空间(分量空间)的影响。分量值(分数)和映射函数都由非线性 PCA 的神经网络方法提供。
非线性的三个重要扩展磷C一种本章将讨论:分层 NLPCA、循环 PCA 和逆 NLPCA。它们都可以组合使用。分层 NLPCA 意味着强制非线性组件具有与标准 PCA 的线性组件相同的层次顺序。这种分层条件产生了单个组件的更高含义。圆磷C一种使非线性 PCA 能够提取描述闭合曲线而不是具有开区间的标准曲线的圆形分量。这对于分析来自循环或振荡现象的数据非常有用。逆ñ大号磷C一种定义非线性磷C一种作为一个逆问题,仅对假设的数据生成过程进行建模,其优点是可以识别更复杂的曲线,并且 NLPCA 可适用于不完整的数据集。
统计代写|数据科学代写data science代考|Bibliographic notes
在多项研究中研究了基于自关联神经网络的非线性 PCA[1−4]. Kirby 和 Miranda [5] 约束网络单元以循环方式工作,导致循环磷C一种其分量是闭合曲线。在大气和海洋科学领域,圆形 PCA 应用于振荡地球物理现象,例如海洋大气厄尔尼诺-南方振荡 [6] 或德国北海沿岸的潮汐循环 [7]。在机器人领域也有应用
为了分析和控制周期性运动[8]。在分子生物学中,环状PCA用于红细胞中疟原虫恶性疟原虫生殖周期的基因表达分析[9]. Scholz 和 Vigário [10] 提出了一种高阶非线性磷C一种它实现了类似于标准线性的非线性组件的层次顺序磷C一种. 这种分层的 NLPCA 被应用于恒星的光谱数据和肌肉活动的肌电图 (EMG) 记录。逆向神经网络模型ñ大号磷C一种最初研究于[11,12]. Valpola 和 Honkela 提出了一种基于这种逆向网络架构的更通用的贝叶斯框架13,14用于非线性因子分析 (NFA) 和非线性独立因子分析 (NIFA)。在[15],这种逆 NLPCA 模型适用于处理缺失数据,以便将其用于分子数据分析。它应用于模式植物拟南芥的冷应激实验的代谢物数据。Hinton 和 Salakhutdinov [16] 已经通过使用特殊的初始化技术证明了使用自动关联网络架构进行可视化和降维。
尽管术语非线性 PCA (NLPCA) 通常被称为自动关联方法,但还有许多其他方法可以以非线性方式可视化数据和提取组件。局部线性嵌入 (LLE)[17,18]和 Isomap [19] 被开发用于通过将高维数据投影(嵌入)到二维或低维空间来可视化高维数据,但没有明确给出映射函数。主曲线 [20] 和自组织图 (SOM) [21] 可用于检测非线性曲线和二维非线性平面。实际上,由于计算成本高,这两种方法都受限于提取的组件数量,通常是两个。核心磷C一种[22]对可视化和降噪很有用[23]。
为将独立分量分析 (ICA) 扩展到非线性 ICA 进行了一些努力。然而,ICA 的非线性扩展不仅非常具有挑战性,而且在没有任何关于非线性混合过程的先验知识的情况下,也是难以处理或非唯一的。因此,特殊的非线性 ICA 模型将问题简化为特定应用,在这些应用中,可以获得一些关于混合系统和因素(源信号)的信息,例如,通过使用序列信息 [24]。非线性方法的讨论一世C一种可以在[25,26]. 本章重点介绍非线性 PCA 的难度较低的任务。原则上,完美的非线性 PCA 应该能够消除数据中的所有非线性,以便随后可以应用标准线性 ICA 以总体上实现非线性 ICA。本章主要基于[9,10,15,27].
统计代写|数据科学代写data science代考|Data generation and component extraction
为了提取成分,线性和非线性,我们假设数据是由许多因素决定的,因此可以被认为是从它们产生的。由于变化因子的数量通常小于
观察变量的数量,数据位于给定数据空间的子空间内。目的是通过共同描述该子空间的组件来表示这些因素。非线性 PCA 不限于线性分量,子空间可以弯曲,如图 2.1 所示。
假设我们有一个数据空间X由观察到的变量和分量空间给出从这是一个子空间X. 非线性 PCA 旨在同时提供子空间从以及之间的映射X和从. 映射由非线性函数给出披提取物 和披G和n. 提取函数披提取物 :X→从变换样本坐标X=(X1,X2,…,Xd)吨的d维数据空间X进入对应的坐标和=(和1,和2,…,和ķ)吨组件空间从通常是低维的ķ. 生成函数披¯G和n:从→X^是重建原始样本向量的逆映射X从它们的低维分量表示和. 因此,披G和n近似于假设的数据生成过程。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。统计代写|python代写代考
随机过程代考
在概率论概念中,随机过程是随机变量的集合。 若一随机系统的样本点是随机函数,则称此函数为样本函数,这一随机系统全部样本函数的集合是一个随机过程。 实际应用中,样本函数的一般定义在时间域或者空间域。 随机过程的实例如股票和汇率的波动、语音信号、视频信号、体温的变化,随机运动如布朗运动、随机徘徊等等。
贝叶斯方法代考
贝叶斯统计概念及数据分析表示使用概率陈述回答有关未知参数的研究问题以及统计范式。后验分布包括关于参数的先验分布,和基于观测数据提供关于参数的信息似然模型。根据选择的先验分布和似然模型,后验分布可以解析或近似,例如,马尔科夫链蒙特卡罗 (MCMC) 方法之一。贝叶斯统计概念及数据分析使用后验分布来形成模型参数的各种摘要,包括点估计,如后验平均值、中位数、百分位数和称为可信区间的区间估计。此外,所有关于模型参数的统计检验都可以表示为基于估计后验分布的概率报表。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
statistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
机器学习代写
随着AI的大潮到来,Machine Learning逐渐成为一个新的学习热点。同时与传统CS相比,Machine Learning在其他领域也有着广泛的应用,因此这门学科成为不仅折磨CS专业同学的“小恶魔”,也是折磨生物、化学、统计等其他学科留学生的“大魔王”。学习Machine learning的一大绊脚石在于使用语言众多,跨学科范围广,所以学习起来尤其困难。但是不管你在学习Machine Learning时遇到任何难题,StudyGate专业导师团队都能为你轻松解决。
多元统计分析代考
基础数据: $N$ 个样本, $P$ 个变量数的单样本,组成的横列的数据表
变量定性: 分类和顺序;变量定量:数值
数学公式的角度分为: 因变量与自变量
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。