如果你也在 怎样代写AP统计这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
AP 统计主要是介绍收集、分析和从数据中得出结论的主要概念和工具。
statistics-lab™ 为您的留学生涯保驾护航 在代写AP统计方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写AP统计方面经验极为丰富,各种代写AP统计相关的作业也就用不着说。
我们提供的AP统计及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|AP统计作业代写代考|Technology Hints: Creating Histograms
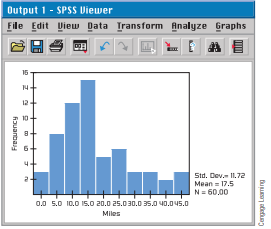
The default histograms produced by the TI-84Plus/ TI-83Plus/TI-mspire calculators, Minitab, and Excel all determine automatically the number of classes to use. To control the number of classes the technology uses, follow the key steps as indicated. The display screens are generated for data found in Table 2-1, One-Way Commuting Distances (in Miles) for 60 Workers in Downtown Dallas.
TI-84Plus/TI-83Plus/TI-nspire
(with TI-84Plus keypad)
Determine the class width for the number of classes you want and the lower class boundary for the first class. Enter the data in list Ll.
Press STATPLOT and highlight On and the histogram plot.
Press WINDOW and set $\mathrm{X}$ min $=$ lowest class boundary, $\mathrm{Xscl}=$ class width. Use appropriate values for the other settings.
Press GRAPH. TRACE gives boundaries and frequency.
统计代写|AP统计作业代写代考|SPSS
The SPSS screen shot shows the default histogram created by the menu choices Analyze – Descriptive Statistics Frequencies. In the dialogue box, move the variable containing the data into the variables window. Click Charts and select Histograms. Click the Continue button and then the OK button.
In SPSS Student Version 17 there are a number of additional ways to create histograms and other graphs. These options utilize the Chart Builder or Graphboard Template Chooser items in the Graphs menu. Under these options you can set the number of classes and the boundaries of the histogram. Specific instructions for using these options are provided in the Technology Guide for SPSS that accompanies this text.
Note that SPSS requires that the measurement level of the data be set before using the Chart Builder. In SPSS, the scale level includes both interval and ratio levels of measurement. The nominal and ordinal levels are as described in this text.
Specific instructions for setting class boundaries (cutpoints) of a histogram are provided in the Technology Guide that aceompanies this text.
统计代写|AP统计作业代写代考|Data Science, Big Data, Statistics
Data science, big data, and statistics are interdisciplinary fields of study. There is not yet a universally accepted consensus defining data science and big data. Both fields are relatively new. However, the American Statistical Association (see references below) points out that data science includes the following major areas:
(i) Database management and data organization
(ii) Statistics with computer applications
(iii) Parallel systems of computer support for data collection
The American Statistical Association and the Royal Statistical Society (London) describe big data in terms of the three $V \mathrm{~s}$.
Volume: Data sets are very, very large, approaching population size.
Velocity: Frequency of observation is very high, often minute by minute or even second by second.
Variety: A wide variety of sensor data is collected rather than data of specific characteristics. This is also known as messy or muddy data.
Graphical displays such as the ones presented in this chapter are an important tool for gleaning information from big data and presenting it. Computer programs designed to filter data according to specific categorical variables or to detect relationships among variables are also essential. In fact, computer programming and expertise in computer software is a major component in a data science curriculum. Training in statistics helps data scientists formulate relevant questions.
Big data are often collected though sensory cameras, shopping rewards programs, social media posts, emails, Internet searches, location tracking of vehicles or cell phones, and so on. Then data fields are fused. This merging of data often results in a great deal of personal information being revealed about an individual. A growing challenge is to develop analytic approaches to preserve the rights of individuals to control their privacy. This is an issue that requires the attention of both data scientists and statisticians.
Big data have a great deal to offer in many disciplines of study. However, there are many, many small data problems that occur inside all big data. These problems require a knowledge of statistics such as you will learn in this text.
References: American Statistical Society and the Royal Statistical Society (London) publications,
Amstatnews, Issue 460 ; Significance, Vol. 12, Issue 3; Significance, Vol. 11, Issue 5: Chance, Vol. 28, No. $1 .$
AP统计代写
统计代写|AP统计作业代写代考|Technology Hints: Creating Histograms
TI-84Plus/TI-83Plus/TI-mspire 计算器、Minitab 和 Excel 生成的默认直方图都自动确定要使用的类数。要控制技术使用的类别数量,请按照所示的关键步骤进行操作。显示屏幕是针对表 2-1,达拉斯市中心 60 名工人的单程通勤距离(英里)中的数据生成的。
TI-84Plus/TI-83Plus/TI-nspire
(带 TI-84Plus 键盘)
确定所需班级数量的班级宽度和第一班级的下班边界。在列表 Ll 中输入数据。
按 STATPLOT 并突出显示 On 和直方图。
按窗口并设置X分钟=最低类边界,XsC一世=班级宽度。为其他设置使用适当的值。
按图形。TRACE 给出了界限和频率。
统计代写|AP统计作业代写代考|SPSS
SPSS 屏幕截图显示了由菜单选项分析 – 描述性统计频率创建的默认直方图。在对话框中,将包含数据的变量移动到变量窗口中。单击图表并选择直方图。单击继续按钮,然后单击确定按钮。
在 SPSS Student Version 17 中,有许多其他方法可以创建直方图和其他图表。这些选项利用图表菜单中的图表生成器或图表模板选择器项目。在这些选项下,您可以设置类的数量和直方图的边界。本文随附的 SPSS 技术指南中提供了使用这些选项的具体说明。
请注意,SPSS 要求在使用 Chart Builder 之前设置数据的测量级别。在 SPSS 中,尺度级别包括测量的区间和比率级别。名义和有序级别如本文所述。
与本文一起提供的技术指南中提供了设置直方图类别边界(切点)的具体说明。
统计代写|AP统计作业代写代考|Data Science, Big Data, Statistics
数据科学、大数据和统计学是跨学科的研究领域。目前还没有一个普遍接受的共识来定义数据科学和大数据。这两个领域都相对较新。然而,美国统计协会(见下文参考资料)指出,数据科学包括以下主要领域:
(i)数据库管理和数据组织
(ii)计算机应用统计(iii)用于数据收集的
计算机支持并行系统
Statistical Association 和 Royal Statistical Society (London) 用三者来描述大数据五 s.
数量:数据集非常非常大,接近人口规模。
速度:观察频率非常高,通常是一分一秒甚至一秒一秒。
多样性:收集的传感器数据种类繁多,而不是特定特征的数据。这也称为混乱或混乱的数据。
本章介绍的图形显示是从大数据中收集信息并进行展示的重要工具。旨在根据特定分类变量过滤数据或检测变量之间关系的计算机程序也是必不可少的。事实上,计算机编程和计算机软件专业知识是数据科学课程的主要组成部分。统计培训有助于数据科学家提出相关问题。
大数据通常通过感官摄像头、购物奖励计划、社交媒体帖子、电子邮件、互联网搜索、车辆或手机的位置跟踪等方式收集。然后融合数据字段。这种数据合并通常会导致个人的大量个人信息被泄露。一个日益严峻的挑战是开发分析方法来保护个人控制其隐私的权利。这是一个需要数据科学家和统计学家关注的问题。
大数据在许多研究学科中都可以提供很多东西。但是,在所有大数据中都会出现很多很多小数据问题。这些问题需要你将在本文中学习到的统计学知识。
参考文献:美国统计学会和皇家统计学会(伦敦)出版物,
Amstatnews,第 460 期;意义,卷。12,第3期;意义,卷。11,第 5 期:机会,卷。28,没有。1.

Course Overview
AP Statistics is an introductory college-level statistics course that introduces students to the major concepts and tools for collecting, analyzing, and drawing conclusions from data. Students cultivate their understanding of statistics using technology, investigations, problem solving, and writing as they explore concepts like variation and distribution; patterns and uncertainty; and data-based predictions, decisions, and conclusions.
- AP Statistics Course OverviewThis resource provides a succinct description of the course and exam.PDF180.39 KB
- AP Statistics Course and Exam Description Walk-ThroughLearn more about the CED in this interactive walk-through.
- AP Statistics Course at a GlanceExcerpted from the AP Statistics Course and Exam Description, the Course at a Glance document outlines the topics and skills covered in the AP Statistics course, along with suggestions for sequencing.PDF585.66 KB
- AP Statistics Course and Exam DescriptionThis is the core document for this course. Unit guides clearly lay out the course content and skills and recommend sequencing and pacing for them throughout the year. The CED was updated in March 2021.PDF17.9 MB
- AP Statistics CED Errata SheetThis document details the updates made to the course and exam description (CED) in March 2021.PDF934.27 KB
- AP Statistics CED Scoring GuidelinesThis document details how each of the sample free-response questions in the course and exam description (CED) would be scored. This information is now in the online CED, but was not included in the binders teachers received in 2019.PDF245.87 KB
Course Content
Based on the Understanding by Design® (Wiggins and McTighe) model, this course framework provides a clear and detailed description of the course requirements necessary for student success. The framework specifies what students must know, be able to do, and understand, with a focus on three big ideas that encompass the principles and processes in the discipline of statistics. The framework also encourages instruction that prepares students for advanced coursework in statistics or other fields using statistical reasoning and for active, informed engagement with a world of data to be interpreted appropriately and applied wisely to make informed decisions.
The AP Statistics framework is organized into nine commonly taught units of study that provide one possible sequence for the course. As always, you have the flexibility to organize the course content as you like.
| Unit | Exam Weighting (Multiple-Choice Section) |
| Unit 1: Exploring One-Variable Data | 15%–23% |
| Unit 2: Exploring Two-Variable Data | 5%–7% |
| Unit 3: Collecting Data | 12%–15% |
| Unit 4: Probability, Random Variables, and Probability Distributions | 10%–20% |
| Unit 5: Sampling Distributions | 7%–12% |
| Unit 6: Inference for Categorical Data: Proportions | 12%–15% |
| Unit 7: Inference for Quantitative Data: Means | 10%–18% |
| Unit 8: Inference for Categorical Data: Chi-Square | 2%–5% |
| Unit 9: Inference for Quantitative Data: Slopes | 2%–5% |
Course Skills
The AP Statistics framework included in the course and exam description outlines distinct skills that students should practice throughout the year—skills that will help them learn to think and act like statisticians.
| Skill | Description | Exam Weighting (Multiple-Choice Section) |
| 1. Selecting Statistical Methods | Select methods for collecting and/or analyzing data for statistical inference. | 15%–23% |
| 2. Data Analysis | Describe patterns, trends, associations, and relationships in data. | 15%–23% |
| 3. Using Probability and Simulation | Explore random phenomena. | 30%–40% |
| 4. Statistical Argumentation | Develop an explanation or justify a conclusion using evidence from data, definitions, or statistical inference. | 25%–35% |
统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。统计代写|python代写代考
随机过程代考
在概率论概念中,随机过程是随机变量的集合。 若一随机系统的样本点是随机函数,则称此函数为样本函数,这一随机系统全部样本函数的集合是一个随机过程。 实际应用中,样本函数的一般定义在时间域或者空间域。 随机过程的实例如股票和汇率的波动、语音信号、视频信号、体温的变化,随机运动如布朗运动、随机徘徊等等。
贝叶斯方法代考
贝叶斯统计概念及数据分析表示使用概率陈述回答有关未知参数的研究问题以及统计范式。后验分布包括关于参数的先验分布,和基于观测数据提供关于参数的信息似然模型。根据选择的先验分布和似然模型,后验分布可以解析或近似,例如,马尔科夫链蒙特卡罗 (MCMC) 方法之一。贝叶斯统计概念及数据分析使用后验分布来形成模型参数的各种摘要,包括点估计,如后验平均值、中位数、百分位数和称为可信区间的区间估计。此外,所有关于模型参数的统计检验都可以表示为基于估计后验分布的概率报表。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
statistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
机器学习代写
随着AI的大潮到来,Machine Learning逐渐成为一个新的学习热点。同时与传统CS相比,Machine Learning在其他领域也有着广泛的应用,因此这门学科成为不仅折磨CS专业同学的“小恶魔”,也是折磨生物、化学、统计等其他学科留学生的“大魔王”。学习Machine learning的一大绊脚石在于使用语言众多,跨学科范围广,所以学习起来尤其困难。但是不管你在学习Machine Learning时遇到任何难题,StudyGate专业导师团队都能为你轻松解决。
多元统计分析代考
基础数据: $N$ 个样本, $P$ 个变量数的单样本,组成的横列的数据表
变量定性: 分类和顺序;变量定量:数值
数学公式的角度分为: 因变量与自变量
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。