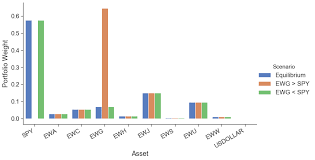
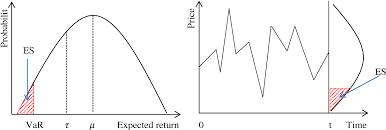
统计代写|风险建模代写Financial risk modeling代考|News effects on the exchange rate
如果你也在 怎样代写风险建模Financial risk modeling这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
风险建模是确定有多少风险存在于一个特定的企业、投资或一系列的现金流中。
statistics-lab™ 为您的留学生涯保驾护航 在代写风险建模Financial risk modeling方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写风险建模Financial risk modeling代写方面经验极为丰富,各种代写风险建模Financial risk modeling相关的作业也就用不着说。
我们提供的风险建模Financial risk modeling及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
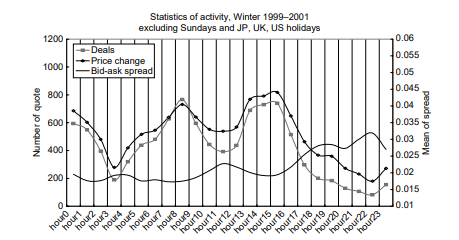
统计代写|风险建模代写Financial risk modeling代考|News effects on the exchange rate
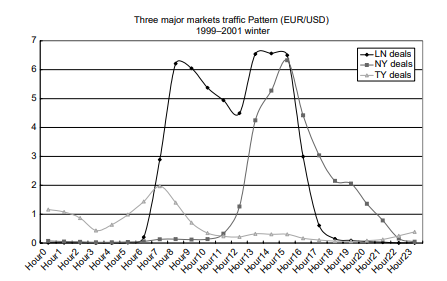
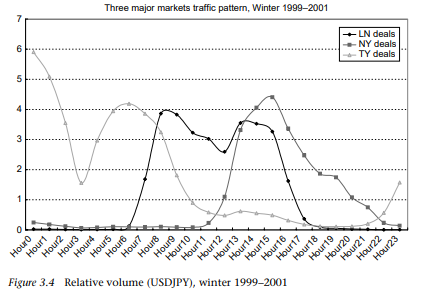
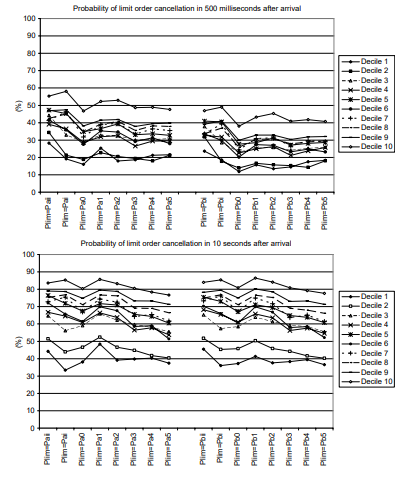
As shown in the previous section, transaction volume tends to surge during a particular time of the day. One of the reasons for a surge in transactions is a concentrated arrival of new macro information in the markets. The possible existence of private information may cause a different trading response by dealers, some of them informed and some uninformed, to the arrival of new information. Then the trading may be intensified between these two types of dealers, as described in the “private information model” of Easley and O’Hara (1992).
In this section, the exchange rate reaction to the release of major macroeconomic statistics is examined. In particular, this section examines how the dollar/yen exchange rate market digests information contained in the various macroeconomic statistics’ releases – to what extent transactions and prices react to the macroeconomic statistics’ news, how long the news effect lasts and which news has the most/least impact on the exchange rate. In the analysis, the unexpected component of macroeconomic announcements, a “surprise,” is defined by the difference between the actual indicator announcement and the average of predicted indicators by the market. The sample period is from 2001 to 2005 and we examine the impacts from 12 Japanese macroeconomic statistics’ releases on the exchange rate returns, volatility and the transaction volume.
统计代写|风险建模代写Financial risk modeling代考|Japanese macroeconomic announcements
Chaboud et al. (2004) study the impact of US macroeconomic announcements on exchange rates using the following US macro variables: payroll, GDP advanced, PPI, retail sales, trade balance and Fed funds rate (target). These authors found a significant impact on exchange rate returns from a surprise component in the announcement. In the European perspective, Ehrmann and Fratzscher (2005) used GDP, Ifo business climate index, business confidence balance, PPI, CPI, retail sales, trade balance, M3, unemployment, industrial production and manufacturing orders as proxies for Germany news releases. 22
In contrast to US macroeconomic announcements, most of which come out at $8.30 \mathrm{am}$ (EST), the release time of Japanese news announcements varies from news to news. Some of the announcements are released in the morning and others in the afternoon. Most of the major macroeconomic statistics come out at either $8.30 \mathrm{am}, 8.50 \mathrm{am}, 10.30 \mathrm{am}$, $2.00 \mathrm{pm}$ or $2.30 \mathrm{pm}$.
After 2001, the announcement time for Japanese macroeconomic statistics has become fairly standardized. Until 2000 , however, a lot of news was released one hour earlier than the current release time, while some news releases were fixed later or went back and forth. For example, the current CPI release time was set at $8.30$ only in 2002 . Release time of three news announcements (balance of payments [8:50], trade balance [8:50] and retail sales [14:30]) changed once in early 2000 and moved back to the original time about six months later.
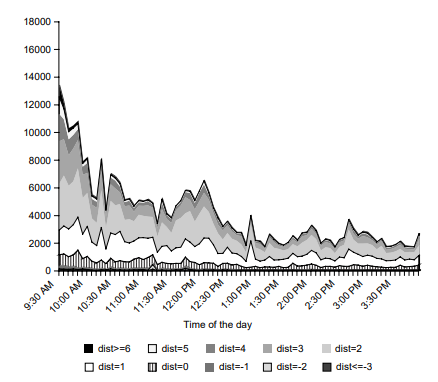
Figures $3.6$ and $3.7$ show the average of number of deals on newsrelease days and non-announcement days for Tankan (Bank of Japan, business survey) and GDP preliminary (GDPP, at $8.50 \mathrm{am}$ JST). This announcement time is just before the first peak in transactions within the day and, therefore, this surge of activity may likely reflect the impact of news releases. ${ }^{23}$ Each figure plots the 15 -minute averages in the number of transactions from 6 am to 12 noon for 2001-2005. The red line shows the benchmark of no macro announcement, and the black line shows the deal activity on announcement days. The top panel of the figure shows the difference in the number of deals between news-announcement days and non-announcement days.
统计代写|风险建模代写Financial risk modeling代考|Impact of surprises on exchange rate activities
When an announcement has unexpected content the announcement is expected to be followed by a change in the exchange rate, because market participants react to this unexpected part by rebalancing their portfolio positions. That is, a surprise would result in changes – positively or negatively – in the exchange rate returns through changes in the number of deals. The release of a news announcement itself, regardless of surprises, may affect price volatility. Suppose that the actual announcement of a macro announcement is exactly the same as the average of market expectations. Then there should not be any positive or negative returns that follow the announcement of no surprise. However, even if the “average” expectation is confirmed by the actual announcement, individuals may be heterogeneous and some are positively surprised and some negatively surprised. Hence, those who were off the average have incentives to trade and price volatility may rise with returns being zero. The total amount of deals may increase at the time of macroeconomic announcement. Unless market participants are homogeneous in expectations on the news – which is very unlikely – some deals are bound to occur right after the announcement. When there is a surprise component in the news, additional deal activities will be stimulated.
Hashimoto and Ito (2009) examined whether and how much an unexpected component of a macroeconomic news announcement, a “surprise, ” will affect returns, volatility and the number of transactions in the dollar/yen exchange market with the following estimations: ${ }^{24}$ Return regression:
$$
\begin{aligned}
\Delta s(t, u) &=\sum_{i(u)=1}^{n(u)} \alpha_{i(u)} N_{i(u)}(t, u)+\varepsilon(t, u) \
\Delta s(t, u) &=\sum_{i(u)=1}^{n(u)} \alpha_{i(u)} N_{i(u)}(t, u)+\delta \Delta s(t, u-k)+\theta N D(t, u-k)+\varepsilon(t, u)
\end{aligned}
$$
风险建模代写
统计代写|风险建模代写Financial risk modeling代考|News effects on the exchange rate
如上一节所示,交易量往往会在一天中的特定时间激增。交易激增的原因之一是新宏观信息集中涌入市场。私人信息的可能存在可能会导致交易商对新信息的到来产生不同的交易反应,其中一些是知情的,一些是不知情的。然后,这两种类型的经销商之间的交易可能会加剧,如 Easley 和 O’Hara(1992)的“私人信息模型”中所述。
在本节中,研究了主要宏观经济统计数据发布后的汇率反应。特别是,本节研究美元/日元汇率市场如何消化各种宏观经济统计数据发布中包含的信息——交易和价格对宏观经济统计数据新闻的反应程度、新闻效应持续多长时间以及哪些新闻具有对汇率的影响最大/最小。在分析中,宏观经济公告的意外成分,即“意外”,定义为实际指标公告与市场预测指标平均值之间的差异。样本期为 2001 年至 2005 年,我们考察了 12 项日本宏观经济统计数据发布对汇率回报、波动性和交易量的影响。
统计代写|风险建模代写Financial risk modeling代考|Japanese macroeconomic announcements
查布德等人。(2004 年)使用以下美国宏观变量研究美国宏观经济公告对汇率的影响:工资、GDP 增长、PPI、零售额、贸易差额和联邦基金利率(目标)。这些作者发现公告中的一个意外部分对汇率回报产生了重大影响。从欧洲的角度来看,Ehrmann 和 Fratzscher (2005) 使用 GDP、Ifo 商业景气指数、商业信心平衡、PPI、CPI、零售销售、贸易平衡、M3、失业率、工业生产和制造业订单作为德国新闻发布的代理。22
与美国宏观经济公告相反,其中大部分发布于8.30一种米(EST),日本新闻公告的发布时间因新闻而异。有些公告在上午发布,有些则在下午发布。大多数主要的宏观经济统计数据都是在8.30一种米,8.50一种米,10.30一种米, 2.00p米或者2.30p米.
2001年以后,日本宏观经济统计数据的公布时间已经相当规范。然而,直到 2000 年,很多新闻都比当前发布时间提前了一个小时发布,而一些新闻发布则更晚一些,或者来回走动。例如,当前 CPI 发布时间设置为8.30仅在 2002 年。三个新闻公告(国际收支[8:50]、贸易平衡[8:50]和零售[14:30])的发布时间在2000年初改变了一次,大约六个月后又回到了原来的时间。
数据3.6和3.7显示短观(日本银行,商业调查)和 GDP 初步(GDPP,at8.50一种米JST)。该公告时间正好在当天交易的第一个高峰之前,因此,这种活动激增可能反映了新闻发布的影响。23每个图都绘制了 2001-2005 年从早上 6 点到中午 12 点的 15 分钟平均交易次数。红线表示没有宏观公告的基准,黑线表示公告日的交易活动。该图的顶部显示了新闻公告日和非公告日之间交易数量的差异。
统计代写|风险建模代写Financial risk modeling代考|Impact of surprises on exchange rate activities
当公告包含意外内容时,预计该公告之后会出现汇率变化,因为市场参与者通过重新平衡其投资组合头寸来应对这一意外部分。也就是说,意外将通过交易数量的变化导致汇率回报发生积极或消极的变化。新闻公告本身的发布,无论是否意外,都可能影响价格波动。假设宏观公告的实际公告与市场预期的平均值完全相同。那么在毫无意外的宣布之后不应该有任何正或负的回报。然而,即使“平均”预期得到实际公告的证实,个人可能是异质的,有些人感到惊讶,有些人感到惊讶。因此,那些偏离平均水平的人有交易动机,价格波动可能会随着回报为零而上升。在宏观经济公布时,交易总量可能会增加。除非市场参与者对新闻的预期一致——这是非常不可能的——否则一些交易肯定会在宣布后立即发生。当新闻中有惊喜成分时,会刺激额外的交易活动。除非市场参与者对新闻的预期一致——这是非常不可能的——否则一些交易肯定会在宣布后立即发生。当新闻中有惊喜成分时,会刺激额外的交易活动。除非市场参与者对消息的预期一致——这是非常不可能的——否则一些交易肯定会在消息发布后立即发生。当新闻中有惊喜成分时,会刺激额外的交易活动。
Hashimoto 和 Ito (2009) 研究了宏观经济新闻公告中的意外组成部分,即“意外”,是否以及在多大程度上会影响美元/日元交易市场的回报、波动性和交易数量,并做出以下估计:24返回回归:
Δs(吨,在)=∑一世(在)=1n(在)一种一世(在)ñ一世(在)(吨,在)+e(吨,在) Δs(吨,在)=∑一世(在)=1n(在)一种一世(在)ñ一世(在)(吨,在)+dΔs(吨,在−ķ)+θñD(吨,在−ķ)+e(吨,在)