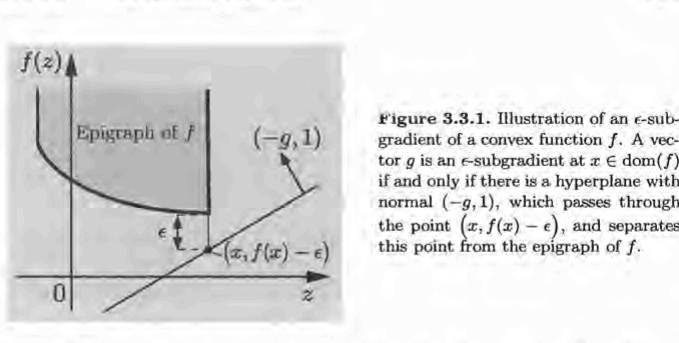
如果你也在 怎样代写凸优化Convex optimization 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。凸优化Convex optimization由于在大规模资源分配、信号处理和机器学习等领域的广泛应用,人们对凸优化的兴趣越来越浓厚。本书旨在解决凸优化问题的算法的最新和可访问的发展。
凸优化Convex optimization无约束可以很容易地用梯度下降(最陡下降的特殊情况)或牛顿方法解决,结合线搜索适当的步长;这些可以在数学上证明收敛速度很快,尤其是后一种方法。如果目标函数是二次函数,也可以使用KKT矩阵技术求解具有线性等式约束的凸优化(它推广到牛顿方法的一种变化,即使初始化点不满足约束也有效),但通常也可以通过线性代数消除等式约束或解决对偶问题来解决。
statistics-lab™ 为您的留学生涯保驾护航 在代写凸优化Convex Optimization方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写凸优化Convex Optimization代写方面经验极为丰富,各种代写凸优化Convex Optimization相关的作业也就用不着说。
数学代写|凸优化作业代写Convex Optimization代考|Connection with Incremental Subgradient Methods
We discussed in Section 2.1.5 incremental variants of gradient methods, which apply to minimization over a closed convex set $X$ of an additive cost function of the form
$$
f(x)=\sum_{i=1}^m f_i(x),
$$
where the functions $f_i: \Re^n \mapsto \Re$ are differentiable. Incremental variants of the subgradient method are also possible in the case where the $f_i$ are nondifferentiable but convex. The idea is to sequentially take steps along the subgradients of the component functions $f_i$, with intermediate adjustment of $x$ after processing each $f_i$. We simply use an arbitrary subgradient of $f_i$ at a point where $f_i$ is nondifferentiable, in place of the gradient that would be used if $f_i$ were differentiable at that point.
Incremental methods are particularly interesting when the number of cost terms $m$ is very large. Then a full subgradient step is very costly, and one hopes to make progress with approximate but much cheaper incremental steps. We will discuss in detail incremental subgradient methods and their combinations with other methods, such as incremental proximal methods, in Section 6.4. In this section we will discuss the most common type of incremental subgradient method, and highlight its connection with the $\epsilon$-subgradient method.
Let us consider the minimization of $\sum_{i=1}^m f_i$ over $x \in X$, for the case where each $f_i$ is a convex real-valued function. Similar to the incremental gradient methods of Section 2.1.5, we view an iteration as a cycle of $m$ subiterations. If $x_k$ is the vector obtained after $k$ cycles, the vector $x_{k+1}$ obtained after one more cycle is
$$
x_{k+1}=\psi_{m, k},
$$
where starting with $\psi_{0, k}=x_k$, we obtain $\psi_{m, k}$ after the $m$ steps
$$
\psi_{i, k}=P_X\left(\psi_{i-1, k}-\alpha_k g_{i, k}\right), \quad i=1, \ldots, m,
$$
with $g_{i, k}$ being an arbitrary subgradient of $f_i$ at $\psi_{i-1, k}$.
数学代写|凸优化作业代写Convex Optimization代考|NOTES, SOURCES, AND EXERCISES
Section 3.1: Subgradients are central in the work of Fenchel [Fen51]. The original theorem by Danskin [Dan67] provides a formula for the directional derivative of the maximum of a (not necessarily convex) directionally differentiable function. When adapted to a convex function $f$, this formula yields Eq. (3.10) for the subdifferential of $f$; see Exercise 3.5.
Another important subdifferential formula relates to the subgradients of an expected value function
$$
f(x)=E{F(x, \omega)},
$$
where $\omega$ is a random variable taking values in a set $\Omega$, and $F(\cdot, \omega): \Re^n \mapsto \Re$ is a real-valued convex function such that $f$ is real-valued (note that $f$ is easily verified to be convex). If $\omega$ takes a finite number of values with probabilities $p(\omega)$, then the formulas
$$
f^{\prime}(x ; d)=E\left{F^{\prime}(x, \omega ; d)\right}, \quad \partial f(x)=E{\partial F(x, \omega)},
$$
hold because they can be written in terms of finite sums as
$$
f^{\prime}(x ; d)=\sum_{\omega \in \Omega} p(\omega) F^{\prime}(x, \omega ; d), \quad \partial f(x)=\sum_{\omega \in \Omega} p(\omega) \partial F(x, \omega),
$$
so Prop. 3.1.3(b) applies. However, the formulas (3.32) hold even in the case where $\Omega$ is uncountably infinite, with appropriate mathematical interpretation of the integral of set-valued functions $E{\partial F(x, \omega)}$ as the set of integrals
$$
\int_{\omega \in \Omega} g(x, \omega) d P(\omega)
$$
where $g(x, \omega) \in \partial F(x, \omega), \omega \in \Omega$ (measurability issues must be addressed in this context). For a formal proof and analysis, see the author’s papers [Ber72], [Ber73], which also provide a necessary and sufficient condition for $f$ to be differentiable, even when $F(\cdot, \omega)$ is not. In this connection, it is important to note that the integration over $\omega$ in Eq. (3.33) may smooth out the nondifferentiabilities of $F(\cdot, \omega)$ if $\omega$ is a “continuous” random variable. This property can be used in turn in algorithms, including schemes that bring to bear the methodology of differentiable optimization; see e.g., Yousefian, Nedić, and Shanbhag [YNS10], [YNS12], Agarwal and Duchi [AgD11], Duchi, Bartlett, and Wainwright [DBW12], Brown and Smith [BrS13], Abernethy et al. [ALS14], and Jiang and Zhang [JiZ14].
凸优化代写
数学代写|凸优化作业代写Convex Optimization代考|Connection with Incremental Subgradient Methods
我们在2.1.5节中讨论了梯度方法的增量变体,它适用于在闭凸集$X$上最小化形式为的附加代价函数
$$
f(x)=\sum_{i=1}^m f_i(x),
$$
这里的函数$f_i: \Re^n \mapsto \Re$是可微的。在$f_i$不可微但是凸的情况下,子梯度方法的增量变体也是可能的。其思想是沿着组件函数$f_i$的子梯度依次采取步骤,在处理每个$f_i$之后对$x$进行中间调整。我们只需在$f_i$不可微的一点上使用$f_i$的任意子梯度,来代替$f_i$在该点可微时使用的梯度。
当成本项$m$的数量非常大时,增量方法特别有趣。然后,一个完整的次梯度步骤是非常昂贵的,人们希望通过近似但更便宜的增量步骤取得进展。我们将在第6.4节详细讨论增量亚梯度方法及其与其他方法的组合,例如增量近端方法。在本节中,我们将讨论最常见的增量子梯度方法类型,并强调其与$\epsilon$ -subgradient方法的联系。
让我们考虑$\sum_{i=1}^m f_i$ / $x \in X$的最小化,对于每个$f_i$都是凸实值函数的情况。与第2.1.5节的增量梯度方法类似,我们将迭代视为$m$子迭代的循环。若$x_k$为$k$次循环后得到的矢量,则再经过一次循环后得到的矢量$x_{k+1}$为
$$
x_{k+1}=\psi_{m, k},
$$
从$\psi_{0, k}=x_k$开始,我们在$m$步骤之后得到$\psi_{m, k}$
$$
\psi_{i, k}=P_X\left(\psi_{i-1, k}-\alpha_k g_{i, k}\right), \quad i=1, \ldots, m,
$$
其中$g_{i, k}$是$f_i$ at $\psi_{i-1, k}$的任意子梯度。
数学代写|凸优化作业代写Convex Optimization代考|NOTES, SOURCES, AND EXERCISES
第3.1节:次梯度是Fenchel [Fen51]工作的核心。Danskin [Dan67]的原始定理提供了一个方向可微函数(不一定是凸的)最大值的方向导数公式。当适用于凸函数$f$时,该公式为$f$的次微分产生Eq. (3.10);参见练习3.5。
另一个重要的次微分公式与期望值函数的次梯度有关
$$
f(x)=E{F(x, \omega)},
$$
其中$\omega$是在集合$\Omega$中取值的随机变量,$F(\cdot, \omega): \Re^n \mapsto \Re$是实值凸函数,因此$f$是实值(注意$f$很容易被验证为凸)。如果$\omega$取有限个数的值,概率为$p(\omega)$,则公式
$$
f^{\prime}(x ; d)=E\left{F^{\prime}(x, \omega ; d)\right}, \quad \partial f(x)=E{\partial F(x, \omega)},
$$
因为它们可以写成有限和的形式
$$
f^{\prime}(x ; d)=\sum_{\omega \in \Omega} p(\omega) F^{\prime}(x, \omega ; d), \quad \partial f(x)=\sum_{\omega \in \Omega} p(\omega) \partial F(x, \omega),
$$
因此,第3.1.3(b)号提案适用。然而,公式(3.32)即使在$\Omega$是不可数无穷的情况下也成立,将集值函数的积分$E{\partial F(x, \omega)}$适当地解释为积分集
$$
\int_{\omega \in \Omega} g(x, \omega) d P(\omega)
$$
其中$g(x, \omega) \in \partial F(x, \omega), \omega \in \Omega$(可度量性问题必须在此上下文中解决)。对于正式的证明和分析,参见作者的论文[Ber72], [Ber73],它们也提供了$f$可微的充分必要条件,即使$F(\cdot, \omega)$不可微。在这方面,重要的是要注意,如果$\omega$是一个“连续”随机变量,则Eq.(3.33)中对$\omega$的积分可以平滑$F(\cdot, \omega)$的不可微性。这个性质可以依次用于算法中,包括采用可微优化方法的方案;参见Yousefian, nedidic, and Shanbhag [YNS10], [YNS12], Agarwal and Duchi [AgD11], Duchi, Bartlett, and Wainwright [DBW12], Brown and Smith [BrS13], Abernethy et al. [ALS14], Jiang and Zhang [JiZ14]。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。