如果你也在 怎样代写凸优化Convex optimization 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。凸优化Convex optimization由于在大规模资源分配、信号处理和机器学习等领域的广泛应用,人们对凸优化的兴趣越来越浓厚。本书旨在解决凸优化问题的算法的最新和可访问的发展。
凸优化Convex optimization无约束可以很容易地用梯度下降(最陡下降的特殊情况)或牛顿方法解决,结合线搜索适当的步长;这些可以在数学上证明收敛速度很快,尤其是后一种方法。如果目标函数是二次函数,也可以使用KKT矩阵技术求解具有线性等式约束的凸优化(它推广到牛顿方法的一种变化,即使初始化点不满足约束也有效),但通常也可以通过线性代数消除等式约束或解决对偶问题来解决。
statistics-lab™ 为您的留学生涯保驾护航 在代写凸优化Convex Optimization方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写凸优化Convex Optimization代写方面经验极为丰富,各种代写凸优化Convex Optimization相关的作业也就用不着说。
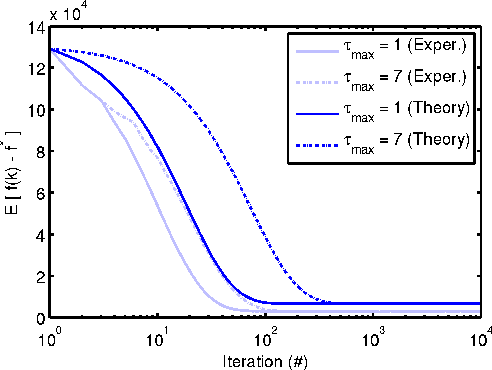
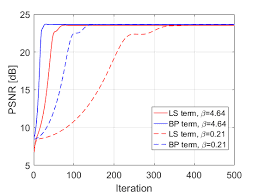
数学代写|凸优化作业代写Convex Optimization代考|Linear Convergence Rate of Incremental Gradient Method
This exercise quantifies the rate of convergence of the incremental gradient method to the “region of confusion” (cf. Fig. 2.1.11), for any order of processing the additive cost components, assuming these components are positive definite quadratic. Consider the incremental gradient method
$$
x_{k+1}=x_k-\alpha \nabla f_k\left(x_k\right) \quad k=0,1, \ldots,
$$
where $f_0, f_1, \ldots$, are quadratic functions with eigenvalues lying within some interval $[\gamma, \Gamma]$, where $\gamma>0$. Suppose that for a given $\epsilon>0$, there is a vector $x^$ such that $$ \left|\nabla f_k\left(x^\right)\right| \leq \epsilon, \quad \forall k=0,1, \ldots
$$
Show that for all $\alpha$ with $0<\alpha \leq 2 /(\gamma+\Gamma)$, the generated sequence $\left{x_k\right}$ converges to a $2 \epsilon / \gamma$-neighborhood of $x^$, i.e., $$ \limsup {k \rightarrow \infty}\left|x_k-x^\right| \leq \frac{2 \epsilon}{\gamma} . $$ Moreover the rate of convergence to this neighborhood is linear, in the sense that $$ \left|x_k-x^\right|>\frac{2 \epsilon}{\gamma} \quad \Rightarrow \quad\left|x{k+1}-x^\right|<\left(1-\frac{\alpha \gamma}{2}\right)\left|x_k-x^\right|, $$ while $$ \left|x_k-x^\right| \leq \frac{2 \epsilon}{\gamma} \quad \Rightarrow \quad\left|x_{k+1}-x^\right| \leq \frac{2 \epsilon}{\gamma} . $$ Hint: Let $f_k(x)=\frac{1}{2} x^{\prime} Q_k x-b_k^{\prime} x$, where $Q_k$ is positive definite symmetric, and write $$ x_{k+1}-x^=\left(I-\alpha Q_k\right)\left(x_k-x^\right)-\alpha \nabla f_k\left(x^\right) .
$$
For other related convergence rate results, see [NeB00] and [Sch14a].
数学代写|凸优化作业代写Convex Optimization代考|Proximal Gradient Method, £1-Regularization, and the Shrinkage Operation
The proximal gradient iteration (2.27) is well suited for problems involving a nondifferentiable function component that is convenient for a proximal iteration. This exercise considers the important case of the $\ell_1$ norm. Consider the problem
$$
\begin{aligned}
& \operatorname{minimize} f(x)+\gamma|x|_1 \
& \text { subject to } x \in \Re^n,
\end{aligned}
$$
where $f: \Re^n \mapsto \Re$ is a differentiable convex function, $|\cdot|_1$ is the $\ell_1$ norm, and $\gamma>0$. The proximal gradient iteration is given by the gradient step
$$
z_k=x_k-\alpha \nabla f\left(x_k\right)
$$
followed by the proximal step
$$
x_{k+1} \in \arg \min {x \in \Re^n}\left{\gamma|x|_1+\frac{1}{2 \alpha}\left|x-z_k\right|^2\right} $$ [cf. Eq. (2.28)]. Show that the proximal step can be performed separately for each coordinate $x^i$ of $x$, and is given by the so-called shrinkage operation: $$ x{k+1}^i=\left{\begin{array}{ll}
z_k^i-\alpha \gamma & \text { if } z_k^i>\alpha \gamma, \
0 & \text { if }\left|z_k^i\right| \leq \alpha \gamma, \
z_k^i+\alpha \gamma & \text { if } z_k^i<-\alpha \gamma,
\end{array} \quad i=1, \ldots, n .\right.
$$
Note: Since the shrinkage operation tends to set many coordinates $x_{k+1}^i$ to 0 , it tends to produce “sparse” iterates.
凸优化代写
数学代写|凸优化作业代写Convex Optimization代考|Linear Convergence Rate of Incremental Gradient Method
这个练习量化了增量梯度法在“混乱区域”的收敛速度(参见图2.1.11),对于任何处理附加成本分量的顺序,假设这些分量是正定的二次元。考虑增量梯度法
$$
x_{k+1}=x_k-\alpha \nabla f_k\left(x_k\right) \quad k=0,1, \ldots,
$$
式中$f_0, f_1, \ldots$为特征值位于某区间$[\gamma, \Gamma]$内的二次函数,式中$\gamma>0$。假设对于给定的$\epsilon>0$,有一个向量$x^$满足 $$ \left|\nabla f_k\left(x^\right)\right| \leq \epsilon, \quad \forall k=0,1, \ldots
$$
证明对于所有$\alpha$和$0<\alpha \leq 2 /(\gamma+\Gamma)$,生成的序列$\left{x_k\right}$收敛到$x^$的$2 \epsilon / \gamma$邻域,即$$ \limsup {k \rightarrow \infty}\left|x_k-x^\right| \leq \frac{2 \epsilon}{\gamma} . $$,并且收敛到该邻域的速度是线性的,即$$ \left|x_k-x^\right|>\frac{2 \epsilon}{\gamma} \quad \Rightarrow \quad\left|x{k+1}-x^\right|<\left(1-\frac{\alpha \gamma}{2}\right)\left|x_k-x^\right|, $$和$$ \left|x_k-x^\right| \leq \frac{2 \epsilon}{\gamma} \quad \Rightarrow \quad\left|x_{k+1}-x^\right| \leq \frac{2 \epsilon}{\gamma} . $$提示:设$f_k(x)=\frac{1}{2} x^{\prime} Q_k x-b_k^{\prime} x$,其中$Q_k$是正定对称的,并写$$ x_{k+1}-x^=\left(I-\alpha Q_k\right)\left(x_k-x^\right)-\alpha \nabla f_k\left(x^\right) .
$$
其他相关的收敛速率结果参见[NeB00]和[Sch14a]。
数学代写|凸优化作业代写Convex Optimization代考|Proximal Gradient Method, £1-Regularization, and the Shrinkage Operation
近端梯度迭代(2.27)非常适合于涉及不可微函数分量的问题,这便于近端迭代。这个练习考虑了$\ell_1$规范的重要情况。考虑这个问题
$$
\begin{aligned}
& \operatorname{minimize} f(x)+\gamma|x|1 \ & \text { subject to } x \in \Re^n, \end{aligned} $$ 其中$f: \Re^n \mapsto \Re$为可微凸函数,$|\cdot|_1$为$\ell_1$范数,$\gamma>0$。近端梯度迭代由梯度步长给出 $$ z_k=x_k-\alpha \nabla f\left(x_k\right) $$ 接着是近端步骤 $$ x{k+1} \in \arg \min {x \in \Re^n}\left{\gamma|x|1+\frac{1}{2 \alpha}\left|x-z_k\right|^2\right} $$[参见式(2.28)]。表明可以对$x$的每个坐标$x^i$分别执行近端步骤,并由所谓的收缩操作:$$ x{k+1}^i=\left{\begin{array}{ll} z_k^i-\alpha \gamma & \text { if } z_k^i>\alpha \gamma, \ 0 & \text { if }\left|z_k^i\right| \leq \alpha \gamma, \ z_k^i+\alpha \gamma & \text { if } z_k^i<-\alpha \gamma, \end{array} \quad i=1, \ldots, n .\right. $$给出 注意:由于收缩操作倾向于将许多坐标$x{k+1}^i$设置为0,因此它倾向于产生“稀疏”迭代。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。