如果你也在 怎样代写机器学习Machine Learning 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning是一个致力于理解和建立 “学习 “方法的研究领域,也就是说,利用数据来提高某些任务的性能的方法。机器学习算法基于样本数据(称为训练数据)建立模型,以便在没有明确编程的情况下做出预测或决定。机器学习算法被广泛用于各种应用,如医学、电子邮件过滤、语音识别和计算机视觉,在这些应用中,开发传统算法来执行所需任务是困难的或不可行的。
机器学习Machine Learning程序可以在没有明确编程的情况下执行任务。它涉及到计算机从提供的数据中学习,从而执行某些任务。对于分配给计算机的简单任务,有可能通过编程算法告诉机器如何执行解决手头问题所需的所有步骤;就计算机而言,不需要学习。对于更高级的任务,由人类手动创建所需的算法可能是一个挑战。在实践中,帮助机器开发自己的算法,而不是让人类程序员指定每一个需要的步骤,可能会变得更加有效 。
statistics-lab™ 为您的留学生涯保驾护航 在代写机器学习 machine learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写机器学习 machine learning代写方面经验极为丰富,各种代写机器学习 machine learning相关的作业也就用不着说。

计算机代写|机器学习代写machine learning代考|Choosing the right tech for the platform and the team
The forecasting scenario we’ve been walking through, when executed in a virtual machine (VM) container and running automated tuning optimization and forecasting for a single airport, worked quite well. We got fairly good results for each airport. By using Hyperopt, we also managed to eliminate the unmaintainable burden of manually tuning each model. While impressive, it doesn’t change the fact that we’re not looking to forecast passengers at just a single airport. We need to create forecasts for thousands of airports.
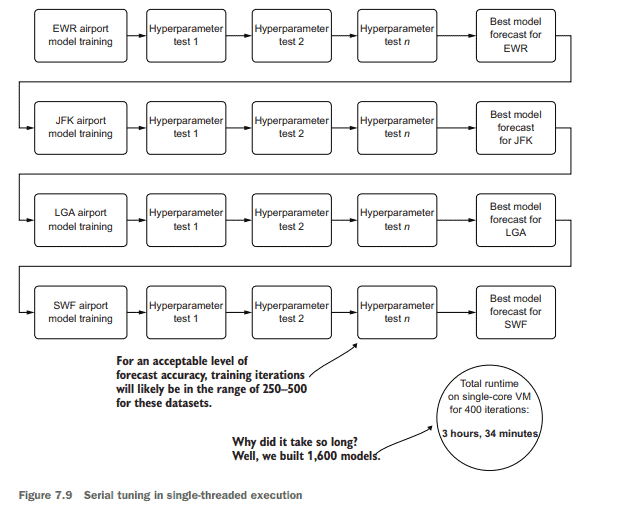
Figure 7.9 shows what we’ve built, in terms of wall-clock time, in our efforts thus far. The synchronous nature of each airport’s models (in a for loop) and Hyperopt’s Bayesian optimizer (also a serial loop) means that we’re waiting for models to be built one by one, each next step waiting on the previous to be completed, as we discussed in section 7.1.2.
This problem of ML at scale, as shown in this diagram, is a stumbling block for many teams, mostly because of complexity, time, and cost (and is one the primary reasons why projects of this scale are frequently cancelled). Solutions exist for these scalability issues for ML project work; each involves stepping away from the realm of serial execution and moving into the world of distributed, asynchronous, or a mixture of both of these paradigms of computing.
The standard structured code approach for most Python ML tasks is to execute in a serial fashion. Whether it be a list comprehension, a lambda, or a for (while) loop, ML is steeped in sequential execution. This approach can be a benefit, as it reduces memory pressure for many algorithms that have a high memory requirement, particularly those that use recursion, which are many. But this approach can also be a handicap, as it takes much longer to execute, since each subsequent task is waiting for the previous to complete.
We will discuss concurrency in ML briefly in section 7.4 and in more depth in later chapters (both safe and unsafe ways of doing it). For now, with the issue of scalability with respect to wall-clock time for our project, we need to look into a distributed approach to this problem in order to explore our search spaces faster for each airport. It is at this point that we stray from the world of our single-threaded VM approach and move into the distributed computing world of Apache Spark.
计算机代写|机器学习代写machine learning代考|Why Spark?
Why use Spark? In a word: speed.
For the problem that we’re dealing with here, forecasting each month the passenger expectations at each major airport in the United States, we’re not bound by SLAs that are measured in minutes or hours, but we still need to think about the amount of time it takes to run our forecasting. There are multiple reasons for this, chiefly
- Time-If we’re building this job as a monolithic modeling event, any failures in an extremely long-running job will require a restart (imagine the job failing after it was $99 \%$ complete, running for 11 days straight).
- Stability-We want to be very careful about object references within our job and ensure that we don’t create a memory leak that could cause the job to fail.
- Risk-Keeping machines dedicated to extremely long-running jobs (even in cloud providers) risks platform issues that could bring down the job.
- Cost-Regardless of where your virtual machines are running, someone is paying the bill for them.
When we focus on tackling these high-risk factors, distributed computing offers a compelling alternative to serial looped execution, not only because of cost, but mostly because of the speed of execution. Were any issues to arise in the job, unforeseen issues with the data, or problems with the underlying hardware that the VMs are running on, these dramatically reduced execution times for our forecasting job will give us flexibility to get the job up and running again with predicted values returning much faster.
A brief note on Spark
Spark is a large topic, a monumentally large ecosystem, and an actively contributed-to open source distributed computing platform based on the Java Virtual Machine (JVM). Because this isn’t a book about Spark per se, I won’t go too deep into the inner workings of it.
Several notable books have been written on the subject, and I recommend reading them if you are inclined to learn more about the technology: Learning Spark by Jules Damji et al. (O’Reilly, 2020), Spark: The Definitive Guide by Bill Chambers and Matei Zaharia (O’Reilly, 2018), and Spark in Action by Jean-Georges Perrin (Manning, 2020).
Suffice it to say, in this book, we will explore how to effectively utilize Spark to perform $\mathrm{ML}$ tasks. Many examples from this point forward are focused on leveraging the power of the platform to perform large-scale $\mathrm{ML}$ (both training and inference).
For the current section, the information covered is relatively high level with respect to how Spark works for these examples; instead, we focus entirely on how we can use it to solve our problems.

机器学习代考
计算机代写|机器学习代写machine learning代考|Choosing the right tech for the platform and the team
当我们在虚拟机(VM)容器中执行预测场景并运行针对单个机场的自动调优优化和预测时,它运行得非常好。我们在每个机场都得到了相当不错的结果。通过使用Hyperopt,我们还设法消除了手动调优每个模型的不可维护的负担。虽然令人印象深刻,但这并不能改变一个事实,即我们并不打算预测单个机场的乘客数量。我们需要为数千个机场做天气预报。
图7.9显示了到目前为止我们所构建的内容,以时钟时间的形式表示。每个机场的模型(在for循环中)和Hyperopt的贝叶斯优化器(也是一个串行循环)的同步特性意味着我们正在等待一个接一个地构建模型,每个下一步等待前一个完成,正如我们在7.1.2节中讨论的那样。
如图所示,大规模的ML问题是许多团队的绊脚石,主要是因为复杂性、时间和成本(这也是这种规模的项目经常被取消的主要原因之一)。针对ML项目工作的这些可扩展性问题存在解决方案;每一种方法都涉及脱离串行执行领域,进入分布式、异步或混合这两种计算范式的世界。
大多数Python ML任务的标准结构化代码方法是以串行方式执行的。无论是列表推导式、lambda还是for (while)循环,ML都沉浸在顺序执行中。这种方法是有好处的,因为它减少了许多对内存要求很高的算法的内存压力,特别是那些使用递归的算法。但是这种方法也可能是一个障碍,因为它需要更长的时间来执行,因为每个后续任务都要等待前一个任务完成。
我们将在第7.4节简要讨论ML中的并发性,并在后面的章节中更深入地讨论并发性(安全和不安全的方法)。现在,由于我们项目的可伸缩性问题与时钟时间有关,我们需要研究一种分布式方法来解决这个问题,以便更快地探索每个机场的搜索空间。正是在这一点上,我们偏离了单线程VM方法的世界,进入了Apache Spark的分布式计算世界。
计算机代写|机器学习代写machine learning代考|Why Spark?
用火花吗?一言以蔽之:速度。
对于我们正在处理的问题,预测每个月在美国各主要机场的乘客期望,我们不受以分钟或小时衡量的sla的约束,但我们仍然需要考虑运行我们的预测所需的时间。主要原因有很多
时间—如果我们将此作业构建为单个建模事件,那么长时间运行的作业中的任何失败都需要重新启动(想象作业在完成99%后失败,连续运行了11天)。
稳定性——我们要非常小心作业中的对象引用,并确保不会造成可能导致作业失败的内存泄漏。
将机器专用于长时间运行的作业(即使在云提供商中),可能会导致平台问题导致作业中断。
成本—无论您的虚拟机在哪里运行,总有人要为它们买单。
当我们专注于处理这些高风险因素时,分布式计算为串行循环执行提供了一个令人信服的替代方案,不仅是因为成本,而且主要是因为执行速度。如果作业中出现任何问题,数据出现不可预见的问题,或者运行vm的底层硬件出现问题,这些显著减少的预测作业的执行时间将使我们能够灵活地启动并再次运行作业,并以更快的速度返回预测值。
关于Spark的一个简短说明
Spark是一个庞大的主题,一个巨大的生态系统,也是一个基于Java虚拟机(JVM)的开源分布式计算平台。因为这不是一本关于Spark本身的书,所以我不会深入探讨它的内部工作原理。
关于这个主题已经写了几本著名的书,如果你想了解更多关于这项技术的知识,我建议你阅读它们:Jules Damji等人的《学习Spark》(O’Reilly, 2020), Bill Chambers和Matei Zaharia的《Spark:权威指南》(O’Reilly, 2018),以及Jean-Georges Perrin的《Spark in Action》(Manning, 2020)。
可以这么说,在本书中,我们将探索如何有效地利用Spark来执行$\ mathm {ML}$任务。从这一点开始,许多例子都集中在利用平台的功能来执行大规模的$\ mathm {ML}$(包括训练和推理)。
对于当前的部分,所涵盖的信息是相对高层次的,关于Spark如何在这些例子中工作;相反,我们完全专注于如何用它来解决我们的问题。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。