如果你也在 怎样代写机器学习Machine Learning 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning是一个致力于理解和建立 “学习 “方法的研究领域,也就是说,利用数据来提高某些任务的性能的方法。机器学习算法基于样本数据(称为训练数据)建立模型,以便在没有明确编程的情况下做出预测或决定。机器学习算法被广泛用于各种应用,如医学、电子邮件过滤、语音识别和计算机视觉,在这些应用中,开发传统算法来执行所需任务是困难的或不可行的。
机器学习Machine Learning程序可以在没有明确编程的情况下执行任务。它涉及到计算机从提供的数据中学习,从而执行某些任务。对于分配给计算机的简单任务,有可能通过编程算法告诉机器如何执行解决手头问题所需的所有步骤;就计算机而言,不需要学习。对于更高级的任务,由人类手动创建所需的算法可能是一个挑战。在实践中,帮助机器开发自己的算法,而不是让人类程序员指定每一个需要的步骤,可能会变得更加有效 。
statistics-lab™ 为您的留学生涯保驾护航 在代写机器学习 machine learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写机器学习 machine learning代写方面经验极为丰富,各种代写机器学习 machine learning相关的作业也就用不着说。

计算机代写|机器学习代写machine learning代考|Logging: Code, metrics, and results
Chapters 2 and 3 covered the critical importance of communication about modeling activities, both to the business and among a team of fellow data scientists. Being able to not only show our project solutions, but also have a provenance history for reference, is just as important to the project’s success, if not more so, than the algorithms used to solve it.
For the forecasting project that we’ve been covering through the last few chapters, the ML aspect of the solution isn’t particularly complex, but the magnitude of the problem is. With thousands of airports to model (which, in turn, means thousands of models to tune and keep track of), handling communication and having a reference for historical data for each execution of the project code is a daunting task.
What happens when, after running our forecasting project in production, a member of the business unit team wants an explanation as to why a particular forecast was so far off from the eventual reality of the data that is collected? This is a common question from many companies that rely on ML predictions to inform the business about actions that should be taken in running the business. The very last thing that you would want to have to deal with if a black swan event occurs and the business is asking questions about why the modeled forecast solution didn’t foresee it, is having to try to regenerate what the model might have forecasted at a certain point in time in order to fully explain how unpredictable events cannot be modeled.
NOTE A black swan event is an unforeseeable and many times catastrophic event that changes the nature of acquired data. While rare, they can have disastrous effects on models, businesses, and entire industries. Some recent black swan events include the September 11th terrorist attacks, the financial collapse of 2008, and the Covid-19 pandemic. Due to the far-reaching and entirely unpredictable nature of these events, the impact to models can be absolutely devastating. The term “black swan” was coined and popularized in reference to data and business in the book The Black Swan: The Impact of the Highly Improbable by Nassim Nicholas Taleb (Random House, 2007).
To solve these intractable issues that ML practitioners have had to deal with historically, MLflow was created. The aspect of MLflow that we’re going to look at in this section is the Tracking API, giving us a place to record all of our tuning iterations, our metrics from each model’s tuning runs, and pre-generated visualizations that can be easily retrieved and referenced from a unified graphical user interface (GUI).
计算机代写|机器学习代写machine learning代考|MLflow tracking
Let’s look at what is going on with the two Spark-based implementations from chapter 7 (section 7.2) as they pertain to MLflow logging. In the code examples shown in that chapter, the initialization of the context for MLflow was instantiated in two distinct places.
In the first approach, using SparkTrials as the state-management object (running on the driver), the MLflow context was placed as a wrapper around the entire tuning run within the function run_tuning (). This is the preferred method of orchestrating the tracking of runs when using SparkTrials so that a parent run’s individual children runs can be associated easily for querying from within the tracking server’s GUI as well as from REST API requests to the tracking server that involve filter predicates.
Figure 8.1 shows a graphical representation of this code when interacting with MLflow’s tracking server. The code records not only the metadata of the parent encapsulating run, but the per iteration logging that occurs from the workers as each hyperparameter evaluation happens.
When looking at the actual code manifestation within the MLflow tracking server’s GUI, we can see the results of this parent-child relationship, shown in figure 8.2.
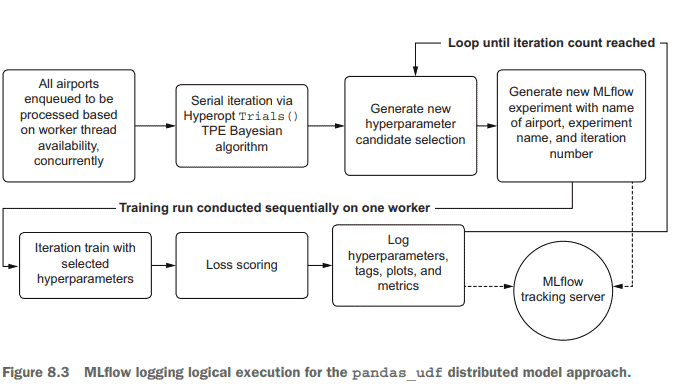
Conversely, the approach used for the pandas_udf implementation is slightly different. In chapter 7’s listing 7.10, each individual iteration that Hyperopt executes requires the creation of a new experiment. Since there is no child-parent relationship to group the data together, the application of custom naming and tagging is required to allow for searchability within the GUI and-more important for production-capable code-the REST API. The overview of the logging mechanics for this alternative (and more scalable implementation for this use case of thousands of models) is shown in figure 8.3.

机器学习代考
计算机代写|机器学习代写machine learning代考|Logging: Code, metrics, and results
第2章和第3章讨论了关于建模活动的沟通的关键重要性,无论是对业务还是在数据科学家团队之间。不仅能够显示我们的项目解决方案,而且能够有一个可供参考的出处历史,这对于项目的成功同样重要,如果不是更重要的话,甚至比用于解决它的算法更重要。
对于我们在前几章中介绍的预测项目,解决方案的ML方面并不是特别复杂,但问题的严重性却很复杂。由于要对数千个机场进行建模(这反过来意味着要对数千个模型进行调优和跟踪),处理通信并为每次项目代码的执行提供历史数据参考是一项艰巨的任务。
当在生产中运行我们的预测项目之后,业务单元团队的成员想要解释为什么特定的预测与所收集的数据的最终现实相距甚远时,会发生什么情况?这是许多公司的一个常见问题,这些公司依赖机器学习预测来告知业务运行中应该采取的行动。如果黑天鹅事件发生了,而企业在质疑为什么建模的预测解决方案没有预见到它,你最不想处理的事情就是尝试重新生成模型在某个时间点可能预测到的内容,以便完全解释不可预测的事件是如何无法建模的。
黑天鹅事件是一种不可预见的、多次灾难性的事件,它改变了所获取数据的性质。虽然罕见,但它们会对模特、企业和整个行业产生灾难性的影响。最近的一些黑天鹅事件包括9 / 11恐怖袭击、2008年金融崩溃和Covid-19大流行。由于这些事件的深远和完全不可预测的性质,对模型的影响绝对是毁灭性的。“黑天鹅”一词是纳西姆·尼古拉斯·塔勒布在《黑天鹅:极不可能事件的影响》(兰登书屋,2007年)一书中创造并普及的,涉及到数据和商业。
为了解决ML从业者必须处理的这些棘手问题,MLflow被创建。在本节中,我们将研究MLflow的一个方面是跟踪API,它为我们提供了一个地方来记录所有的调优迭代、每个模型调优运行的指标,以及可以从统一的图形用户界面(GUI)轻松检索和引用的预生成的可视化。
计算机代写|机器学习代写machine learning代考|MLflow tracking
让我们看看第7章(第7.2节)中关于MLflow日志记录的两个基于spark的实现是怎么回事。在该章的代码示例中,在两个不同的地方实例化了MLflow上下文的初始化。
在第一种方法中,使用SparkTrials作为状态管理对象(在驱动程序上运行),MLflow上下文被放置为run_tuning()函数中整个调优运行的包装器。当使用SparkTrials时,这是编排运行跟踪的首选方法,这样可以很容易地将父运行的各个子运行关联起来,以便从跟踪服务器的GUI中进行查询,以及从REST API请求到涉及过滤器谓词的跟踪服务器进行查询。
图8.1显示了与MLflow的跟踪服务器交互时该代码的图形化表示。代码不仅记录了父封装运行的元数据,还记录了在每个超参数求值发生时来自工作线程的每次迭代日志记录。
在MLflow跟踪服务器的GUI中查看实际的代码表现时,我们可以看到父子关系的结果,如图8.2所示。
相反,用于pandas_udf实现的方法略有不同。在第7章的清单7.10中,Hyperopt执行的每次迭代都需要创建一个新的实验。由于没有父子关系将数据分组在一起,因此需要使用自定义命名和标记的应用程序来支持GUI中的可搜索性,并且对于具有生产能力的代码来说更重要的是REST API。图8.3显示了这种替代方法的日志记录机制的概述(以及这个包含数千个模型的用例的更可伸缩的实现)。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。