数学代写|数值方法作业代写numerical methods代考|CS514
如果你也在 怎样代写数值方法numerical methods这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
如果所有导数的近似值(有限差分、有限元、有限体积等)在步长(Δt、Δx等)趋于零时都趋于精确值,则称该数值方法为一致的。如果误差不随时间(或迭代)增长,则表示数值方法是稳定的(如IVPs)。
statistics-lab™ 为您的留学生涯保驾护航 在代写数值方法numerical methods方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写数值方法numerical methods代写方面经验极为丰富,各种代写数值方法numerical methods相关的作业也就用不着说。
我们提供的数值方法numerical methods及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
数学代写|数值方法作业代写numerical methods代考|Vehicular pollution
Vehicular pollution is significantly when ozone harming substances and other destructive contaminations are discharged into the environment from vehicles. These unsafe toxins negatively affect both the ecosystem and the human body. Constituents of vehicular pollution includes carbon monoxide, oxides of nitrogen, particles of soot, metal and pollen, sulfur dioxide other dangerous pollutants.
From Fig. 2.5, you will see a few gases leaving the fumes of the vehicles. This is the thing that vehicular pollution is majorly about. Vehicular pollution is one of the significant reasons for air pollution in light of the fact that these gases leaving the vehicles go up into the air and thus pollute the air. Vehicular pollution is one of the most widely recognized types of pollution across the world since vehicles are fundamentally all over the place. Indeed, vehicular pollution is disregarded in light of the fact that it is from automobile. Each country experiences vehicular pollution. Iran is adjudged to have high urban contamination which includes vehicular pollution, and dust storms which is well known locally as “the 120-day wind.” Schools and different offices are a few times compelled to close down during the period while the specialists disseminate face masks to residents for wellbeing. In Nigeria, there have been deaths recorded due to indoor fossil-fuel generator emission. Gases released (and inhaled) in the rush hour traffic jammed at Bombay-India is reported as smoking 51 cigarettes every day. In other words, research in vehicular pollution does not only require measurement but a well designed numerical analysis.
数学代写|数值方法作业代写numerical methods代考|Gas flaring
Gas flares known as the burning of gas are created through different stages of oil and gas exploration. It is a main source of concern in oil producing countries as it releases significant amount of greenhouse gases. There are research works on how to convert this process for energy generation (ref). However, in a few developing countries, these gases are burned in air, thereby polluting the atmosphere and increasing the temperature of the geographical location.
Gas flaring is also defined as hydrocarbon harvesting and the procedure of combusting gas from wells. In recent times, it is regarded as a major environmental issue, contributing to approximately 150 billion meter cube.
There are three types of flaring: emergency, process, and product flaring. Emergency flaring occurs during compression failure from valve breakage. Process flaring occurs during petrochemical processes, and product flaring occurs during exploration.
There are different causes of gas flaring:
i. Natural gas carried to the surface but cannot be used as it is burned as a means of disposal
ii. Result of oil extraction
iii. Inadequate structure to put gas for industrialization
iv. Excess gas and oils after extraction
v. To avoid explosions caused by simply bottling up huge quantities of gases, flaring is used.
The effects of gas flaring includes acid rain, air pollution, influencing climate change, and reduced agricultural practice. Sulfur dioxide and nitrogen oxide emissions are the main factors of acid rain, which also are combined with atmospheric moisture to produce sulfuric acid and nitric acid, respectively. Acidification of lakes, ponds, and rivers affects both the aquatic and terrestrial organisms. Acid rain also quickens the deterioration of construction materials and paints. Flaring of gas results in the release of impurities, toxic substances that are harmful to humans. $\mathrm{CO}_2$ is produced when gas is not completely burned, and it the most toxic substance to human health. Environmental implications of this gas flaring are severe because it is such an inefficient and poor use of potential fuel that pollutes air. The effects of gas flaring on climate change are significant as it is also a form of fossil fuels burning. The main component of gas flaring is carbon dioxide. By emitting $\mathrm{CO}_2$, the major greenhouse gas, gas flaring contributes to global warming. The second major gas which contributes to greenhouse effect is methane, which is released when gas is vented without being burned. Gas flaring has been seen to affect agriculture as its pollutants are released into the atmosphere like nitrogen, carbon, sulfur oxides, particulate matter, and hydrogen sulfide. These pollutants deplete soil nutrients by acidifying the soil. Given the immense heat generated as well as the $\mathrm{pH}$ acid characteristics of the soil, there would not be any vegetation in the areas of gas flares. Temperature changes have a different effect on crops, including stunted growth, scotched plants, and withered young crops. Gas flaring has also negatively impacted upon human health due to the inhalation of toxic gases which are emitted during unfinished gas flare combustion. These gases have been connected to negative health challenges including cancer, neurological problems, reproductive issues, developmental disorders, children’s abnormalities, lung damage, and skin issues. As seen from the above, there are lots of gray area in numerically modeling to nowcast or forecast gas flares (Fig. 2.6).
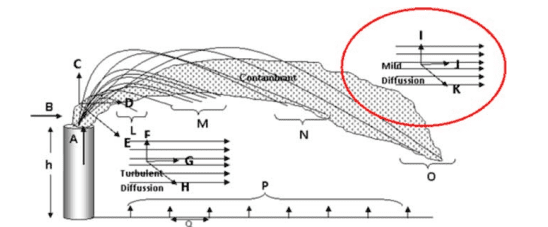
数值方法代写
数学代写|数值方法作业代写numerical methods代考|Vehicular pollution
当臭氧危害物质和其他破坏性污染物从车辆排放到环境中时,车辆污染是显着的。这些不安全的毒素会对生态系统和人体产生负面影响。车辆污染的成分包括一氧化碳、氮氧化物、煤烟颗粒、金属和花粉、二氧化硫等危险污染物。
从图 2.5 中,您会看到一些气体从车辆的烟雾中排出。这就是车辆污染的主要问题。车辆污染是空气污染的重要原因之一,因为离开车辆的这些气体会上升到空气中,从而污染空气。车辆污染是世界上最广泛认可的污染类型之一,因为车辆基本上无处不在。事实上,由于车辆污染来自汽车这一事实,因此忽略了车辆污染。每个国家都会经历车辆污染。伊朗被判定为具有高度城市污染,其中包括车辆污染和在当地被称为“120 天风”的沙尘暴。” 在此期间,学校和不同的办公室几次被迫关闭,而专家则向居民分发口罩以求健康。在尼日利亚,由于室内化石燃料发电机的排放而导致死亡。据报道,在印度孟买交通拥堵的高峰时段释放(和吸入)的气体每天吸 51 支香烟。换句话说,对车辆污染的研究不仅需要测量,还需要精心设计的数值分析。
数学代写|数值方法作业代写numerical methods代考|Gas flaring
被称为气体燃烧的气体火炬是通过石油和天然气勘探的不同阶段产生的。它是石油生产国关注的主要来源,因为它释放了大量的温室气体。有关于如何将这一过程转化为能量产生的研究工作(参考)。然而,在少数发展中国家,这些气体在空气中燃烧,从而污染大气并提高地理位置的温度。
气体燃烧也被定义为碳氢化合物的收集和从井中燃烧气体的过程。近来,它被视为一个重大的环境问题,贡献了大约 1500 亿立方米。
燃烧分为三种类型:紧急燃烧、过程燃烧和产品燃烧。在阀门破裂导致压缩失效期间发生紧急燃烧。过程燃烧发生在石化过程中,产品燃烧发生在勘探过程中。
气体燃烧有不同的原因:
i. 天然气被带到地表,但不能使用,因为它作为一种处置手段燃烧
ii. 采油结果
iii.
iv.工业化气体结构不足 提取后过量的气体和油
v. 为了避免因简单地装瓶大量气体而引起的爆炸,使用了燃烧。
天然气燃烧的影响包括酸雨、空气污染、影响气候变化和减少农业活动。二氧化硫和氮氧化物排放是酸雨的主要因素,它们也与大气水分结合,分别产生硫酸和硝酸。湖泊、池塘和河流的酸化影响水生和陆生生物。酸雨还会加速建筑材料和油漆的劣化。气体燃烧会释放出对人体有害的杂质和有毒物质。C○2气体未完全燃烧时产生,是对人体健康毒性最大的物质。这种气体燃烧对环境的影响是严重的,因为它是一种污染空气的潜在燃料的低效和低效使用。天然气燃烧对气候变化的影响是显着的,因为它也是化石燃料燃烧的一种形式。气体燃烧的主要成分是二氧化碳。通过发射C○2,主要的温室气体,气体燃烧导致全球变暖。造成温室效应的第二种主要气体是甲烷,当气体在没有燃烧的情况下排放时会释放出来。气体燃烧已被认为会影响农业,因为其污染物会释放到大气中,如氮、碳、硫氧化物、颗粒物和硫化氢。这些污染物通过酸化土壤消耗土壤养分。鉴于产生的巨大热量以及pH土壤的酸性特征,在气体火炬区域不会有任何植被。温度变化对作物有不同的影响,包括生长迟缓、枯萎的植物和枯萎的幼苗。由于吸入在未完成的气体火炬燃烧期间排放的有毒气体,气体火炬还对人类健康产生负面影响。这些气体与负面健康挑战有关,包括癌症、神经问题、生殖问题、发育障碍、儿童异常、肺损伤和皮肤问题。从上面可以看出,在临近预报或预测气体耀斑的数值模拟中存在很多灰色区域(图 2.6)。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。