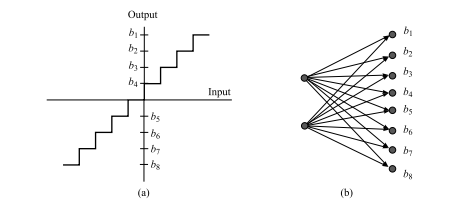
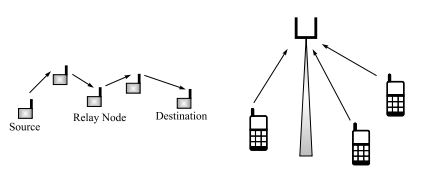
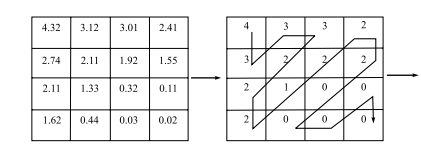
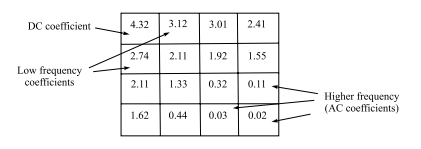
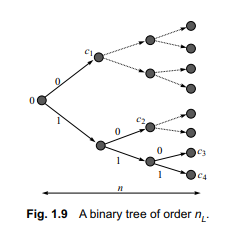
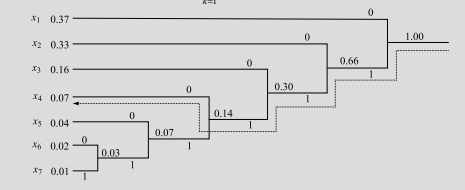
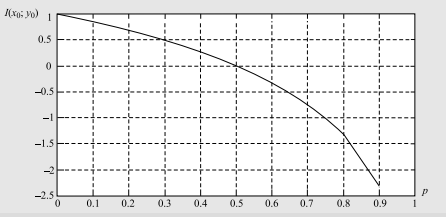
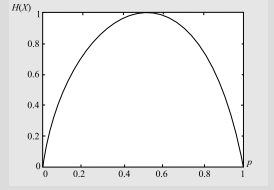
数学代写|信息论作业代写information theory代考|INFSCI2120
如果你也在 怎样代写信息论information theory这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
信息理论是对数字信息的量化、存储和通信的科学研究。该领域从根本上是由哈里-奈奎斯特和拉尔夫-哈特利在20世纪20年代以及克劳德-香农在20世纪40年代的作品所确立的。该领域处于概率论、统计学、计算机科学、统计力学、信息工程和电气工程的交叉点。
statistics-lab™ 为您的留学生涯保驾护航 在代写信息论information theory方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写信息论information theory代写方面经验极为丰富,各种代写信息论information theory相关的作业也就用不着说。
我们提供的信息论information theory及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
数学代写|信息论作业代写information theory代考|Work in London and Down
The Beagle was now on its way home, and Darwin impatiently counted the days and miles which separated him from his family and friends. To his sisters he wrote: “I feel inclined to write about nothing else but to tell you, over and over again, how I long to be quietly seated among you”; and in a letter to Henslow he exclaimed: “Oh the degree to which I long to be living quietly, without one single novel object near me! No one can imagine it until he has been whirled around the world, during five long years, in a Ten Gun Brig.”
Professor Sedgwick had told Darwin’s father that he believed that Charles would take his place among the leading scientific men of England. This encouraging news from home reached Darwin on Ascension Island. “After reading this letter”, Darwin wrote, “I clambered over the mountains with a bounding step and made the rocks resound under my geological hammer.”
On October 2, 1836, the Beagle docked at Falmouth, and Darwin, “giddy with joy and confusion”, took the first available coach to The Mount, his family’s home in Shrewsbury. After a joyful reunion with his family, he visited the Wedgwood estate at Maer, where his Uncle Jos and his pretty cousins were equally impatient to see him. To Henslow he wrote: “I am in the clouds, and neither know what to do or where to go… My chief puzzle is about the geological specimens – who will have the charity to help me in describing their mineralogical nature?”
Soon Darwin found a collaborator and close friend in none other than Sir Charles Lyell, the great geologist whose book had so inspired him. One of Lyell’s best characteristics was his warmth in encouraging promising young scientists. Darwin’s theory of the formation of coral barrier reefs and atolls had supplanted Lyell’s own theory, but far from being offended, Lyell welcomed Darwin’s ideas with enthusiasm. According to Lyell’s earlier theory, coral atolls are circular in shape because they are based on the circular rims of submerged volcanos. However, Darwin showed that any island gradually sinking beneath the surface of a tropical ocean can develop into an atoll. He showed that the reef-building organisms of the coral are poisoned by the stagnant water of the central lagoon, but they flourish on the perimeter, where new water is constantly brought in by the waves. Darwin was able to use the presence of coral atolls to map whole regions of the Pacific which are gradually sinking. He pointed out that in the subsiding regions there are no active volcanos, while in regions where the land is rising, there is much volcanic activity.
数学代写|信息论作业代写information theory代考|The Origin of Species
In 1837 Darwin had begun a notebook on Transmutation of Species. During the voyage of the Beagle he had been deeply impressed by the great fossil animals which he had discovered, so like existing South American species except for their gigantic size. Also, as the Beagle had sailed southward, he had noticed the way in which animals were replaced by closely allied species. On the Galapagos Islands, he had been struck by the South American character of the unique species found there, and by the way in which they differed slightly on each island.
It seemed to Darwin that these facts, as well as many other observations which he had made on the voyage, could only be explained by assuming that species gradually became modified. The subject haunted him, but he was unable to find the exact mechanism by which species changed. Therefore he resolved to follow the Baconian method, which his friend Sir Charles Lyell had used so successfully in geology. He hoped that by the wholesale collection of all facts related in any way to the variation of animals and plants under domestication and in nature, he might be able to throw some light on the subject. He soon saw that in agriculture, the key to success in breeding new varieties was selection; but how could selection be applied to organisms living in a state of nature?
信息论代写
数学代写|信息论作业代写information theory代考|Work in London and Down
小猎犬号现在正在回家的路上,达尔文不耐烦地计算着他与家人和朋友分开的日子和里程。他对姐妹们写道:“我倾向于不写别的,只是一遍又一遍地告诉你们,我多么渴望安静地坐在你们中间”;在给亨斯洛的一封信中,他感叹道:“哦,我多么渴望安静地生活,身边没有一件新奇的东西!直到他在长达五年的十炮双桅船中环游世界之前,没有人能想象到这一点。”
塞奇威克教授曾告诉达尔文的父亲,他相信查尔斯会在英国领先的科学家中占据一席之地。这个来自家乡的令人鼓舞的消息传到了阿森松岛的达尔文。“读完这封信后,”达尔文写道,“我大踏步翻越山峦,让岩石在我的地质锤下响起。”
1836 年 10 月 2 日,小猎犬号停靠在法尔茅斯,达尔文“喜出望外”,带着第一辆可用的教练前往他家在什鲁斯伯里的家——山。在与家人欢聚一堂后,他参观了位于 Maer 的 Wedgwood 庄园,他的乔斯叔叔和他漂亮的堂兄弟们同样迫不及待地想见他。他对亨斯洛写道:“我在云端,不知道该做什么,也不知道该去哪里……我的主要难题是关于地质标本——谁将有慈善事业帮助我描述它们的矿物学性质?”
很快,达尔文在查尔斯·莱尔爵士(Sir Charles Lyell)身上找到了一位合作者和密友,这位伟大的地质学家的书给了他很大启发。莱尔最大的特点之一是他热情地鼓励有前途的年轻科学家。达尔文关于珊瑚堡礁和环礁形成的理论已经取代了莱尔自己的理论,但莱尔并没有被冒犯,而是热情地欢迎达尔文的想法。根据莱尔早期的理论,珊瑚环礁是圆形的,因为它们是基于水下火山的圆形边缘。然而,达尔文表明,任何逐渐沉入热带海洋表面的岛屿都可以发展成环礁。他表明,珊瑚的造礁生物被中央泻湖的死水毒害,但它们在周边繁盛,海浪不断引入新水。达尔文能够利用珊瑚环礁的存在来绘制整个太平洋地区正在逐渐下沉的地图。他指出,在下沉的地区没有活火山,而在地势上升的地区,火山活动较多。
数学代写|信息论作业代写information theory代考|The Origin of Species
1837 年,达尔文开始写一本关于物种嬗变的笔记本。在小猎犬号的航行中,他发现的巨大化石动物给他留下了深刻的印象,除了体型巨大外,与现存的南美物种一样。此外,随着小猎犬向南航行,他注意到动物被密切相关的物种所取代的方式。在加拉帕戈斯群岛,他被那里发现的独特物种的南美特征以及每个岛上它们的细微差别所震惊。
在达尔文看来,这些事实,以及他在航行中所做的许多其他观察,只能通过假设物种逐渐被改变来解释。这个主题一直困扰着他,但他无法找到物种变化的确切机制。因此,他决定采用他的朋友查尔斯·莱尔爵士在地质学中如此成功地使用的培根方法。他希望通过大量收集与驯化和自然界中动植物变异有关的所有事实,或许能够对这个主题有所了解。他很快就发现,在农业中,培育新品种成功的关键是选择;但是选择如何应用于生活在自然状态中的生物呢?

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。