统计代写|随机信号处理作业代写Statistical Signal Processing代考|Random Processes
如果你也在 怎样代写随机信号处理Statistical Signal Processing这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
随机信号处理是一种将信号视为随机过程的方法,利用其统计特性来执行信号处理任务。
statistics-lab™ 为您的留学生涯保驾护航 在代写随机信号处理Statistical Signal Processing方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写随机信号处理Statistical Signal Processing代写方面经验极为丰富,各种代写随机信号处理Statistical Signal Processing相关的作业也就用不着说。
我们提供的随机信号处理Statistical Signal Processingl及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|随机信号处理作业代写Statistical Signal Processing代考|Random Processes
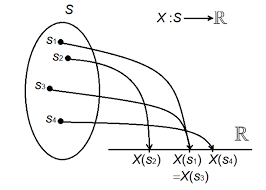
It is straightforward conceptually to go from one random variable to $k$ random variables constituting a $k$-dimensional random vector. It is perhaps a greater leap to extend the idea to a random process. The idea is at least easy to state, but it will take more work to provide examples and the mathematical details will prove more complicated. A random process is a sequence of random variables $\left{X_{n} ; n=0,1, \ldots\right}$ defined on a common experiment. It can be thought of as an infinite dimensional random vector. To be more accurate, this is an example of a discrete-time, one-sided random process. It is called “discrete-time” because the index $n$ which corresponds to time takes on discrete values (here the nonnegative integers) and it is called “one-sided” because only nonnegative times are allowed. A discrete-time random process is also called a time series in the statistics literature and it is often denoted as ${X(n) n=0,1, \ldots}$ and is sometimes denoted by ${X[n]}$ in the digital signal processing literature. Two questions might oocur to the reader: how does one construct an infinite family of random variables on a single experiment? How can one provide a direct development of a random process as accomplished for random variables and vectors? The direct development might appear hopeless since infinite dimensional vectors are involved.
The first problem is reasonably easy to handle by example. Consider the usual uniform pdf experiment. Rename the random variables $Y$ and $W$ as $X_{0}$ and $X_{1}$, respectively. Consider the following definition of an infinite family of random variables $X_{n}:[0,1) \rightarrow{0,1}$ for $n=0,1, \ldots$. Every $r \in[0,1)$ can be expanded as a binary expansion of the form
$$
r=\sum_{n=0}^{\infty} b_{n}(r) 2^{-n-1}
$$
This simply replaces the usual decimal representation by a binary representation. For example, $1 / 4$ is $.25$ in decimal and .01 or .010000… in binary. $1 / 2$ is .5 in decimal and yields the binary sequence .1000…, $1 / 4$ is $.25$ in decimal and yields the binary sequence .0100…, $3 / 4$ is .75 in decimal and $.11000 \ldots .$ and $1 / 3$ is $.3333 . . .$ in decimal and $.010101 \ldots$ in binary.
Define the random process by $X_{n}(r)=b_{n}(r)$, that is, the $n$th term in the binary expansion of $r$. When $n=0,1$ this reduces to the specific $X_{0}$ and $X_{1}$ already considered.
统计代写|随机信号处理作业代写Statistical Signal Processing代考|Random Variables
We now develop the promised precise definition of a random variable. As you might guess, a technical condition for random variables is required because of certain subtle pathological problems that have to do with the ability to determine probabilities for the random variable. To arrive at the precise definition, we start with the informal definition of a random variable that we have already given and then show the inevitable difficulty that results without the technical condition. We have informally defined a
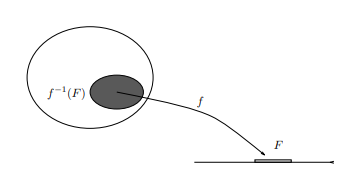
random variable as being a function on a sample space. Suppose we have a probability space $(\Omega, \mathcal{F}, P)$. Let $f: \Omega \rightarrow \Re$ be a function mapping the same space into the real line so that $f$ is a candidate for a random variable. Since the selection of the original sample point $\omega$ is random, that is, governed by a probability measure, so should be the output of our measurement of random variable $f(\omega)$. That is, we should be able to find the probability of an “output event” such as the event “the outcome of the random variable $f$ was between $a$ and $b, “$ that is, the event $F \subset \Re$ given by $F=(a, b)$. Observe that there are two different kinds of events being considered here:
- output events or members of the event space of the range or range space of the random variable, that is, events consisting of subsets of possible output values of the random variable; and
- input events or $\Omega$ events, events in the original sample space of the original probability space.
Can we find the probability of this output event? That is, can we make mathematieal senee out of the quantity “the probability that $f$ areumee a value in an event $F \subset \Re$ ?? On reflection it seems clear that we can. The probability that $f$ assumes a value in some set of values must be the probability of all values in the original sample space that result in a value of $f$ in the given set. We will make this concept more precise shortly. To save writing we will abbreviate such English statements to the form $\operatorname{Pr}(f \in F)$, or $\operatorname{Pr}(F)$, that is, when the notation $\operatorname{Pr}(F)$ is encountered it should be interpreted as shorthand for the English statement for “the probability of an event $F^{” \prime}$ or “the probability that the event $F$ will occur” and not as a precise mathematical quantity.
统计代写|随机信号处理作业代写Statistical Signal Processing代考|Distributions of Random Variables
Suppose we have a probability space $(\Omega, \mathcal{F}, P)$ with a random variable, $X$, defined on the space. The random variable $X$ takes values on its range space which is some subset $A$ of $\Re$ (possibly $A=\Re$ ). The range space $A$ of a random variable is often called the alphabet of the random variable. As we have seen, since $X$ is a random variable, we know that all subsets of $\Omega$ of the form $X^{-1}(F)={\omega: X(\omega) \in F}$, with $F \in B(A)$, must be members of $\mathcal{F}$ by definition. Thus the set function $P_{X}$ defined by
$$
P_{X}(F)=P\left(X^{-1}(F)\right)=P({\omega: X(\omega) \in F}) ; F \in \mathcal{B}(A)
$$
is well defined and assigns probabilities to output events involving the random variable in terms of the original probability of input events in the orig-
inal experiment. The three written forms in equation (3.22) are all read as $\operatorname{Pr}(X \in F)$ or “the probability that the random variable $X$ takes on a value in $F .$ Furthermore, since inverse images preserve all set-theoretic operations (see problem A.12), $P_{X}$ satisfies the axioms of probability as a probability measure on $(A, \mathcal{B}(A))-$ it is nonnegative, $P_{X}(A)=1$, and it is countably additive. Thus $P_{X}$ is a probability measure on the measurable space $(A, \mathcal{B}(A))$. Therefore, given a probability space and a random variable $X$, we have constructed a new probability space $\left(A, \mathcal{B}(A), P_{X}\right)$ where the events describe outcomes of the random variable. The probability measure $P_{X}$ is called the distribution of $X$ (as opposed to a “cumulative distribution function” of $X$ to be introduced later).
If two random variables have the same distribution, then they are said to be equivalent since they have the same probabilistic description, whether or not they are defined on the same underlying space or have the same functional form (see problem 3.22).
A substantial part of the application of probability theory to practical probblems is devoted to determining the distributions of random variables, perfurmaing the “ealeulus of prubabsility.” Ons bugina with a probubility space. A random variable is defined on that space. The distribution of the random variable is then derived, and this results in a new probability space. This topic is called variously “derived distributions” or “transformations of random variables” and is often developed in the literature as a sequence of apparently unrelated subjects. When the points in the original sample space can be interpreted as “signals,” then such problems can be viewed as “signal processing” and derived distribution problems are fundamental to the analysis of statistical signal processing systems. We shall emphasize that all such examples are just applications of the basic inverse image formula (3.22) and form a unified whole. In fact, this formula, with its vector analog, is one of the most important in applications of probability theory. Its specialization to discrete input spaces using sums and to continuous input spaces using integrals will be seen and used often throughout this book.
信号处理代写
统计代写|随机信号处理作业代写Statistical Signal Processing代考|Random Processes
从一个随机变量到ķ随机变量构成ķ维随机向量。将这个想法扩展到随机过程可能是一个更大的飞跃。这个想法至少很容易陈述,但提供示例需要更多的工作,并且数学细节将被证明更加复杂。随机过程是一系列随机变量\左{X_{n} ; n=0,1, \ldots\right}\左{X_{n} ; n=0,1, \ldots\right}定义在一个共同的实验上。它可以被认为是一个无限维的随机向量。更准确地说,这是离散时间、单边随机过程的一个示例。它被称为“离散时间”,因为索引n它对应于时间的离散值(这里是非负整数),它被称为“单面”,因为只允许非负时间。离散时间随机过程在统计学文献中也称为时间序列,通常表示为X(n)n=0,1,…有时表示为X[n]在数字信号处理文献中。读者可能会想到两个问题:如何在一次实验中构建无限的随机变量族?如何提供对随机变量和向量完成的随机过程的直接开发?由于涉及无限维向量,直接发展可能看起来没有希望。
第一个问题很容易通过示例来处理。考虑通常的统一 pdf 实验。重命名随机变量是和在作为X0和X1, 分别。考虑以下无限随机变量族的定义Xn:[0,1)→0,1为了n=0,1,…. 每一个r∈[0,1)可以展开为形式的二进制展开
r=∑n=0∞bn(r)2−n−1
这只是用二进制表示代替了通常的十进制表示。例如,1/4是.25十进制和 .01 或 .010000… 二进制。1/2是十进制的 0.5 并产生二进制序列 .1000…,1/4是.25十进制并产生二进制序列 .0100…,3/4十进制为 0.75 和.11000….和1/3是.3333…十进制和.010101…在二进制。
定义随机过程Xn(r)=bn(r), 那就是n的二进制展开中的第 项r. 什么时候n=0,1这减少到具体X0和X1已经考虑过了。
统计代写|随机信号处理作业代写Statistical Signal Processing代考|Random Variables
我们现在开发了随机变量的承诺精确定义。正如您可能猜到的那样,由于某些微妙的病理问题与确定随机变量概率的能力有关,因此需要随机变量的技术条件。为了得到精确的定义,我们从已经给出的随机变量的非正式定义开始,然后展示在没有技术条件的情况下产生的不可避免的困难。我们非正式地定义了一个
随机变量作为样本空间上的函数。假设我们有一个概率空间(Ω,F,磷). 让F:Ω→ℜ是一个将相同空间映射到实线的函数,使得F是随机变量的候选者。由于原始样本点的选择ω是随机的,即由概率测度控制,因此我们对随机变量的测度的输出也应该是F(ω). 也就是说,我们应该能够找到“输出事件”的概率,例如事件“随机变量的结果”F介于一种和b,“也就是事件F⊂ℜ由F=(一种,b). 请注意,这里考虑了两种不同类型的事件:
- 输出事件或随机变量的范围或范围空间的事件空间的成员,即由随机变量的可能输出值的子集组成的事件;和
- 输入事件或Ω事件,原始概率空间的原始样本空间中的事件。
我们能找到这个输出事件的概率吗?也就是说,我们能否从数量“概率Fareumee 事件中的值F⊂ℜ?? 经过反思,我们似乎很清楚我们可以。的概率F假设一组值中的一个值必须是原始样本空间中所有值的概率F在给定的集合中。我们将很快使这个概念更加精确。为了节省书写,我们会将此类英文陈述缩写为表格公关(F∈F), 或者公关(F),也就是说,当符号公关(F)遇到它应该被解释为英语语句“事件的概率”的简写F”′或“事件发生的概率F会发生”,而不是作为一个精确的数学量。
统计代写|随机信号处理作业代写Statistical Signal Processing代考|Distributions of Random Variables
假设我们有一个概率空间(Ω,F,磷)带有随机变量,X,在空间上定义。随机变量X在其范围空间上取值,该范围空间是某个子集一种的ℜ(可能一种=ℜ)。范围空间一种随机变量的字母表通常称为随机变量的字母表。正如我们所见,自从X是一个随机变量,我们知道所有的子集Ω形式的X−1(F)=ω:X(ω)∈F, 和F∈乙(一种), 必须是F根据定义。因此设置函数磷X被定义为
磷X(F)=磷(X−1(F))=磷(ω:X(ω)∈F);F∈乙(一种)
定义良好,并根据原始输入事件的原始概率为涉及随机变量的输出事件分配概率
最终实验。等式(3.22)中的三个书面形式都读作公关(X∈F)或“随机变量的概率X取值F.此外,由于逆图像保留了所有集合论操作(见问题 A.12),磷X满足概率公理作为概率度量(一种,乙(一种))−它是非负的,磷X(一种)=1, 并且是可数相加的。因此磷X是可测空间上的概率测度(一种,乙(一种)). 因此,给定一个概率空间和一个随机变量X,我们构造了一个新的概率空间(一种,乙(一种),磷X)其中事件描述随机变量的结果。概率测度磷X称为分布X(相对于“累积分布函数”X稍后介绍)。
如果两个随机变量具有相同的分布,则称它们是等价的,因为它们具有相同的概率描述,无论它们是否定义在相同的基础空间或具有相同的函数形式(参见问题 3.22)。
将概率论应用于实际问题的很大一部分致力于确定随机变量的分布,从而实现“概率论”。带有概率空间的 Ons bugina。在该空间上定义了一个随机变量。然后导出随机变量的分布,这会产生一个新的概率空间。这个主题被称为不同的“派生分布”或“随机变量的变换”,并且通常在文献中被发展为一系列明显不相关的主题。当原始样本空间中的点可以解释为“信号”时,则可以将此类问题视为“信号处理”,而派生的分布问题是统计信号处理系统分析的基础。我们要强调的是,所有这些例子都只是基本逆像公式(3.22)的应用,形成了一个统一的整体。事实上,这个公式及其矢量类比是概率论应用中最重要的公式之一。它专门针对使用求和的离散输入空间和使用积分的连续输入空间将在本书中经常看到和使用。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。