数学代写|信息论代写information theory代考|The Relationship Between Logical Entropy and Shannon Entropy
如果你也在 怎样代写信息论information theory这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
信息论是对数字信息的量化、存储和通信的科学研究。该领域从根本上是由哈里-奈奎斯特和拉尔夫-哈特利在20世纪20年代以及克劳德-香农在20世纪40年代的作品所确立的。
statistics-lab™ 为您的留学生涯保驾护航 在代写信息论information theory方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写信息论information theory代写方面经验极为丰富,各种代写信息论information theory相关的作业也就用不着说。
我们提供的信息论information theory及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
数学代写|信息论代写information theory代考|Brief History of the Logical Entropy Formula
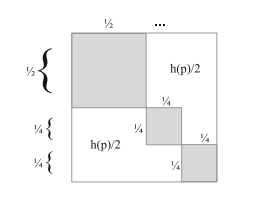
The logical entropy formula $h(p)=\sum_{i} p_{i}\left(1-p_{i}\right)=1-\sum_{i} p_{i}^{2}$ is the probability of getting distinct values $u_{i} \neq u_{j}$ in two independent samplings of the random variable $u$. The complementary measure $1-h(p)=\sum_{i} p_{i}^{2}$ is the probability that the two drawings yield the same value from $U$. Thus $1-\sum_{i} p_{i}^{2}$ is a measure of heterogeneity or diversity in keeping with our theme of information as distinctions, while the complementary measure $\sum_{i} p_{i}^{2}$ is a measure of homogeneity or concentration. Historically, the formula can be found in either form depending on the particular context. The $p_{i}$ ‘s might be relative shares such as the relative share of organisms of the $i$ th species in some population of organisms, and then
the interpretation of $p_{i}$ as a probability arises by considering the random choice of an organism from the population.
According to I. J. Good, the formula has a certain naturalness: “If $p_{1}, \ldots, p_{t}$ are the probabilities of $t$ mutually exclusive and exhaustive events, any statistician of this century who wanted a measure of homogeneity would have take about two seconds to suggest $\sum p_{i}^{2}$ which I shall call $\rho . “[13$, p. 561] As noted by Bhargava and Uppuluri [4], the formula $1-\sum p_{i}^{2}$ was used by Gini in 1912 [10] as a measure of “mutability” or diversity. But another development of the formula (in the complementary form) in the early twentieth century was in cryptography. The American cryptologist, William F. Friedman, devoted a 1922 book [9] to the “index of coincidence” (i.e., $\sum p_{i}^{2}$ ). Solomon Kullback (see the Kullback-Leibler divergence treated later) worked as an assistant to Friedman and wrote a book on cryptology which used the index [16].
During World War II, Alan M. Turing worked for a time in the Government Code and Cypher School at the Bletchley Park facility in England. Probably unaware of the earlier work, Turing used $\rho=\sum p_{i}^{2}$ in his cryptoanalysis work and called it the repeat rate since it is the probability of a repeat in a pair of independent draws from a population with those probabilities (i.e., the identification probability $1-h(p)$ ). Polish cryptoanalysts had independently used the repeat rate in their work on the Enigma [21].
数学代写|信息论代写information theory代考|Shannon Entropy
For a partition $\pi=\left{B_{1}, \ldots, B_{m}\right}$ with block probabilities $p\left(B_{i}\right)$ (obtained using equiprobable points or with point probabilities), the Shannon entropy of the partition (using logs to base 2) is:
$$
H(\pi)=-\sum_{i=1}^{m} p\left(B_{i}\right) \log \left(p\left(B_{i}\right)\right)
$$
Or if given a finite probability distribution $p=\left{p_{1}, \ldots, p_{m}\right}$, the Shannon entropy of the probability distribution is:
$$
H(p)=-\sum_{i=1}^{m} p_{i} \log \left(p_{i}\right)
$$
The Shannon entropy is often presented as being the same as the Boltzmann entropy $S=\frac{1}{n} \ln \left(\frac{n !}{n_{1} ! \ldots n_{m} !}\right)$; it is even called the “Shannon-Boltzmann entropy” by
many authors. The story is that when presented with Shannon’s formula, John von Neumann suggested calling it “entropy” since it occurs in statistical mechanicsand since Shannon could always win arguments since no one really knows what entropy is. But it only occurs in statistical mechanics as a numerical approximation based on taking the first two terms in the Stirling approximation formula for $\ln (n !)$. The first two terms in the Stirling approximation for $\ln (N !)$ are: $\ln (N !) \approx$ $N \ln (N)-N$
If we consider a partition on a finite $U$ with $|U|=N$, with $n$ blocks of size $N_{1}, \ldots, N_{n}$, then the number of ways of distributing the individuals in these $n$ boxes with those numbers $N_{i}$ in the $i$ th box is: $W=\frac{N !}{N_{1} ! \times \ldots \times N_{n} !}$. The normalized natural $\log$ of $W, S=\frac{1}{N} \ln (W)$ is one form of entropy in statistical mechanics. Indeed, the formula $S=k \log (W)$ is engraved on Boltzmann’s tombstone.
The entropy formula can then be developed using the first two terms in the Stirling approximation.
$$
\begin{gathered}
S=\frac{1}{N} \ln (W)=\frac{1}{N} \ln \left(\frac{N !}{N_{1} ! \times \ldots \times N_{n} !}\right)=\frac{1}{N}\left[\ln (N !)-\sum_{i} \ln \left(N_{i} !\right)\right] \
\approx \frac{1}{N}\left[N[\ln (N)-1]-\sum_{i} N_{i}\left[\ln \left(N_{i}\right)-1\right]\right] \
=\frac{1}{N}\left[N \ln (N)-\sum N_{i} \ln \left(N_{i}\right)\right]=\frac{1}{N}\left[\sum N_{i} \ln (N)-\sum N_{i} \ln \left(N_{i}\right)\right] \
=\sum \frac{N_{i}}{N} \ln \left(\frac{1}{N_{i} / N}\right)=\sum p_{i} \ln \left(\frac{1}{p_{i}}\right)=H_{e}(p)
\end{gathered}
$$
数学代写|信息论代写information theory代考|Logical Entropy, Not Shannon Entropy
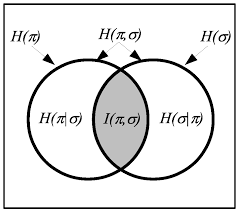
Shannon entropy and the many other suggested ‘entropies’ (Rényi, Tsallis, etc.) are routinely called “measures” of information in the general sense of a real-valued quantification -but not in the sense of measure theory. The formulas for mutual information, joint entropy, and conditional entropy are defined so these Shannon entropies satisfy Venn diagram formulas. As Lorne Campbell put it:
Certain analogies between entropy and measure have been noted by various authors. These analogies provide a convenient mnemonic for the various relations between entropy, conditional entropy, joint entropy, and mutual information. It is interesting to speculate whether these analogies have a deeper foundation. It would seem to be quite significant if entropy did admit an interpretation as the measure of some set. [1, p. 112]
For any finite set $U$, a measure $\mu$ is a function $\mu: \wp(U) \rightarrow \mathbb{R}$ such that:
- $\mu(\emptyset)=0$,
- for any $E \subseteq U, \mu(E) \geq 0$, and
- for any disjoint subsets $E_{1}$ and $E_{2}, \mu\left(E_{1} \cup E_{2}\right)=\mu\left(E_{1}\right)+\mu\left(E_{2}\right)$.
The standard usage in measure theory $[4,3]$ seems to be that a “measure” is defined to be non-negative, and the extension to allow negative values is a “signed measure.” That definition is used here although a few authors [10] define a measure to allow negative values and then call the restriction to non-negative values a “positive measure.” The point to notice is that both measures and signed measures can be represented as Venn diagrams (allowing negative areas). As we will see, for three or more random variables, the Shannon mutual information can have negative values-which has no known interpretation. But there is an interesting difference. The logical entropies are defined in terms of a probability measure on a set. The compound Shannon entropies are defined ‘directly’ so as to satisfy the Venn diagram relationships without any mention of a set on which the Venn diagram is defined. As one author put it: “Shannon carefully contrived for this ‘accident’ to occur” [11, p. 153]. But it is possible ex post to then define a set so that the alreadydefined Shannon entropies are the appropriate values on subsets of that set. The ex post construction for the Shannon entropies was first carried out by Kuo Ting Hu [6] but was also noted by Imre Csiszar and Janos Körner [2], and redeveloped by Raymond Yeung [14]. Outside the context of Shannon entropies, the underlying mathematical facts about additive set functions and the inclusion-exclusion principle were known at least from the 1925 first edition of the Polya-Szego classic [9] and Ryser’s treatment of combinatorics [12]-all well-developed in [13].
信息论代考
数学代写|信息论代写information theory代考|Brief History of the Logical Entropy Formula
逻辑熵公式H(p)=∑一世p一世(1−p一世)=1−∑一世p一世2是获得不同值的概率在一世≠在j在随机变量的两个独立抽样中在. 补充措施1−H(p)=∑一世p一世2是两张图产生相同值的概率在. 因此1−∑一世p一世2是异质性或多样性的衡量标准,与我们将信息作为区分的主题保持一致,而补充衡量标准∑一世p一世2是均匀性或浓度的量度。从历史上看,这个公式可以根据特定的上下文以任何一种形式出现。这p一世的可能是相对份额,例如生物体的相对份额一世某些生物种群中的第 th 种,然后
的解释p一世因为概率是通过考虑从种群中随机选择一个有机体而产生的。
根据 IJ Good 的说法,该公式具有一定的自然性:“如果p1,…,p吨是概率吨相互排斥和详尽的事件,本世纪任何想要衡量同质性的统计学家都需要大约两秒钟的时间来提出建议∑p一世2我称之为ρ.“[13,页。561] 正如 Bhargava 和 Uppuluri [4] 所指出的,公式1−∑p一世2Gini 在 1912 年 [10] 使用它来衡量“可变性”或多样性。但在 20 世纪初,该公式(以互补形式)的另一个发展是在密码学中。美国密码学家威廉·弗里德曼 (William F. Friedman) 在 1922 年的一本书 [9] 中专门讨论了“巧合指数”(即,∑p一世2)。Solomon Kullback(参见稍后处理的 Kullback-Leibler 散度)担任弗里德曼的助手,并写了一本使用索引的密码学书籍 [16]。
二战期间,艾伦 M. 图灵曾在英国布莱切利公园设施的政府密码和密码学校工作过一段时间。可能不知道早期的工作,图灵使用ρ=∑p一世2在他的密码分析工作中,将其称为重复率,因为它是具有这些概率的群体中一对独立抽取中重复的概率(即识别概率1−H(p))。波兰密码分析家在他们的 Enigma [21] 工作中独立使用了重复率。
数学代写|信息论代写information theory代考|Shannon Entropy
对于一个分区\pi=\left{B_{1}, \ldots, B_{m}\right}\pi=\left{B_{1}, \ldots, B_{m}\right}有块概率p(乙一世)(使用等概率点或点概率获得),分区的香农熵(使用以 2 为底的对数)为:
H(圆周率)=−∑一世=1米p(乙一世)日志(p(乙一世))
或者如果给定一个有限的概率分布p=\left{p_{1}, \ldots, p_{m}\right}p=\left{p_{1}, \ldots, p_{m}\right},概率分布的香农熵为:
H(p)=−∑一世=1米p一世日志(p一世)
香农熵通常与玻尔兹曼熵相同小号=1nln(n!n1!…n米!); 它甚至被称为“香农-玻尔兹曼熵”
许多作者。故事是,当提出香农公式时,约翰·冯·诺依曼建议称其为“熵”,因为它出现在统计力学中,而且香农总是能赢得争论,因为没有人真正知道熵是什么。但它只出现在统计力学中,作为基于斯特林近似公式中前两项的数值近似ln(n!). 斯特林近似中的前两项ln(ñ!)是:ln(ñ!)≈ ñln(ñ)−ñ
如果我们考虑一个有限的分区在和|在|=ñ, 和n大小块ñ1,…,ñn,那么这些个体的分布方式的数量n带有这些数字的盒子ñ一世在里面一世第一个盒子是:在=ñ!ñ1!×…×ñn!. 归一化的自然日志的在,小号=1ñln(在)是统计力学中熵的一种形式。确实,公式小号=ķ日志(在)刻在玻尔兹曼的墓碑上。
然后可以使用斯特林近似中的前两项来开发熵公式。
小号=1ñln(在)=1ñln(ñ!ñ1!×…×ñn!)=1ñ[ln(ñ!)−∑一世ln(ñ一世!)] ≈1ñ[ñ[ln(ñ)−1]−∑一世ñ一世[ln(ñ一世)−1]] =1ñ[ñln(ñ)−∑ñ一世ln(ñ一世)]=1ñ[∑ñ一世ln(ñ)−∑ñ一世ln(ñ一世)] =∑ñ一世ñln(1ñ一世/ñ)=∑p一世ln(1p一世)=H和(p)
数学代写|信息论代写information theory代考|Logical Entropy, Not Shannon Entropy
香农熵和许多其他建议的“熵”(Rényi、Tsallis 等)通常在实值量化的一般意义上被称为信息的“测量”——但不是在测量理论的意义上。定义了互信息、联合熵和条件熵的公式,因此这些香农熵满足维恩图公式。正如 Lorne Campbell 所说:
熵和度量之间的某些类比已被许多作者注意到。这些类比为熵、条件熵、联合熵和互信息之间的各种关系提供了方便的助记符。推测这些类比是否有更深的基础是很有趣的。如果熵确实允许将解释解释为某些集合的度量,那似乎是非常重要的。[1,第 112]
对于任何有限集在, 一种方法μ是一个函数μ:℘(在)→R这样:
- μ(∅)=0,
- 对于任何和⊆在,μ(和)≥0, 和
- 对于任何不相交的子集和1和和2,μ(和1∪和2)=μ(和1)+μ(和2).
测度论中的标准用法[4,3]似乎“度量”被定义为非负数,而允许负值的扩展是“有符号度量”。尽管一些作者 [10] 定义了一个允许负值的度量,然后将对非负值的限制称为“正度量”,但这里使用了该定义。需要注意的一点是,度量和签名度量都可以表示为维恩图(允许负区域)。正如我们将看到的,对于三个或更多随机变量,香农互信息可以具有负值——这没有已知的解释。但是有一个有趣的区别。逻辑熵是根据集合上的概率度量来定义的。复合香农熵被“直接”定义以满足维恩图关系,而无需提及定义维恩图的集合。正如一位作者所说:“香农精心设计了这个‘意外’的发生”[11, p. 153]。但是可以事后定义一个集合,以便已经定义的香农熵是该集合子集上的适当值。香农熵的事后构造首先由 Kuo Ting Hu [6] 进行,但 Imre Csiszar 和 Janos Körner [2] 也注意到了这一点,并由 Raymond Yeung [14] 重新开发。在香农熵的范围之外,关于加法集函数和包含-排除原理的基本数学事实至少从 1925 年第一版的 Polya-Szego 经典 [9] 和 Ryser 对组合学的处理 [12] 中得知——一切都很好-在[13]中开发。但是可以事后定义一个集合,以便已经定义的香农熵是该集合子集上的适当值。香农熵的事后构造首先由 Kuo Ting Hu [6] 进行,但 Imre Csiszar 和 Janos Körner [2] 也注意到了这一点,并由 Raymond Yeung [14] 重新开发。在香农熵的范围之外,关于加法集函数和包含-排除原理的基本数学事实至少从 1925 年第一版的 Polya-Szego 经典 [9] 和 Ryser 对组合学的处理 [12] 中得知——一切都很好-在[13]中开发。但是可以事后定义一个集合,以便已经定义的香农熵是该集合子集上的适当值。香农熵的事后构造首先由 Kuo Ting Hu [6] 进行,但 Imre Csiszar 和 Janos Körner [2] 也注意到了这一点,并由 Raymond Yeung [14] 重新开发。在香农熵的范围之外,关于加法集函数和包含-排除原理的基本数学事实至少从 1925 年第一版的 Polya-Szego 经典 [9] 和 Ryser 对组合学的处理 [12] 中得知——一切都很好-在[13]中开发。香农熵的事后构造首先由 Kuo Ting Hu [6] 进行,但 Imre Csiszar 和 Janos Körner [2] 也注意到了这一点,并由 Raymond Yeung [14] 重新开发。在香农熵的范围之外,关于加法集函数和包含-排除原理的基本数学事实至少从 1925 年第一版的 Polya-Szego 经典 [9] 和 Ryser 对组合学的处理 [12] 中得知——一切都很好-在[13]中开发。香农熵的事后构造首先由 Kuo Ting Hu [6] 进行,但 Imre Csiszar 和 Janos Körner [2] 也注意到了这一点,并由 Raymond Yeung [14] 重新开发。在香农熵的范围之外,关于加法集函数和包含-排除原理的基本数学事实至少从 1925 年第一版的 Polya-Szego 经典 [9] 和 Ryser 对组合学的处理 [12] 中得知——一切都很好-在[13]中开发。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。