统计代写|金融中的随机方法作业代写Stochastic Methods in Finance代考| Pricing Coupon-Bearing Bonds
如果你也在 怎样代写金融中的随机方法Stochastic Methods in Finance这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
随机建模是金融模型的一种形式,用于帮助做出投资决策。这种类型的模型使用随机变量预测不同条件下各种结果的概率。随着现代经济学、金融学实证研究的发展,金融中的随机方法Stochastic Methods in Finance作为一种数学工具具有越来越重要的应用价值。
statistics-lab™ 为您的留学生涯保驾护航 在代写金融中的随机方法Stochastic Methods in Finance方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写金融中的随机方法Stochastic Methods in Finance方面经验极为丰富,各种代写金融中的随机方法Stochastic Methods in Finance相关的作业也就用不着说。
我们提供的金融中的随机方法Stochastic Methods in Finance及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|金融中的随机方法作业代写Stochastic Methods in Finance代考|Pricing Coupon-Bearing Bonds
As sufficient historical data on Euro coupon-bearing Treasury bonds is difficult to obtain we use the zero-coupon yield curve to construct the relevant bonds. Coupons on newly-issued bonds are generally closely related to the corresponding spot rate at the time, so the current zero-coupon yield with maturity $T$ is used as a proxy for the coupon rate of a coupon-bearing Treasury bond with maturity $T$. For example, on scenario $\omega$ the coupon rate $\delta_{2}^{B^{10}}(\omega)$ on a newly issued 10-year Treasury bond at time $t=2$ will be set equal to the projected 10 -year spot rate $y_{2,10}(\omega)$ at time $t=2$.
Generally
$$
\begin{array}{llr}
\delta_{t}^{B^{(T)}}(\omega)=y_{t, T}(\omega) & \forall t \in T^{d} & \forall \omega \in \Omega \
\delta_{t}^{B^{(T)}}(\omega)=\delta_{\lfloor t\rfloor}^{(T)}(\omega) & \forall t \in T^{i} & \forall \omega \in \Omega,
\end{array}
$$
where L.」 denotes integral part. This ensures that as the yield curve falls, coupons on newly-issued bonds will go down correspondingly and each coupon cash flow will be discounted at the appropriate zero-coupon yield.
The bonds are assumed to pay coupons semi-annually. Since we roll the bonds on an annual basis, a coupon will be received after six months and again after a year just before the bond is sold. This forces us to distinguish between the price at which the bond is sold at rebalancing times and the price at which the new bond is purchased.
Let $P_{t, B^{(T)}}^{(\text {sell }}$ denote the selling price of the bond $B^{(T)}$ at time $t$, assuming two coupons have now been paid out and the time to maturity is equal to $T-1$, and let $P_{t, B^{(t)}}^{(\text {tuy })}$ denote the price of a newly issued coupon-bearing Treasury bond with a maturity equal to $T$.
The “buy’ bond price at time $t$ is given by
$$
\begin{aligned}
B_{t}^{T}(\omega)=& F^{B^{T}} e^{-(T+\lfloor t]-t) y_{t, T+\lfloor t \mid-t}(\omega)} \
&+\sum_{s=\frac{|2|}{2}+\frac{1}{2}, \frac{\lfloor 2\rfloor \mid}{2}+1, \ldots,[t]+T} \frac{\delta^{A^{T}}(\omega)}{2} F^{B^{T}} e^{-(s-t) y_{t, t x-t)}(\omega)}
\end{aligned}
$$
where the principal of the bond is discounted in the first term and the stream of coupon payments in the second.
At rebalancing times $t$ the sell price of the bond is given by
$$
B_{t}^{T}(\omega)=F^{B^{T}} e^{-(T-1) y_{i, T-1}(\omega)}+\sum_{s=\frac{1}{2}, 1, \ldots, T-1} \frac{\delta_{i-1}^{B^{T}}(\omega)}{2} F^{B^{T}} e^{-(s-t) y,(\omega-t)(\omega)}
$$
$\omega \in \Omega \quad t \in\left{T^{d} \backslash{0}\right} \cup{T}$with coupon rate $\delta_{t-1}^{B^{T}}(\omega)$. The coupon rate is then reset for the newly-issued Treasury bond of the same maturity. We assume that the coupons paid at six months are re-invested in the off-the-run bonds. This gives the following adjustment to the amount held in bond $B^{T}$ at time $t$
统计代写|金融中的随机方法作业代写Stochastic Methods in Finance代考|Historical Backtests
We will look at an historical backtest in which statistical models are fitted to data up to a trading time $t$ and scenario trees are generated to some chosen horizon $t+T$. The optimal root node decisions are then implemented at time $t$ and compared to the historical returns at time $t+1$. Afterwards the whole procedure is rolled forward for T trading times.
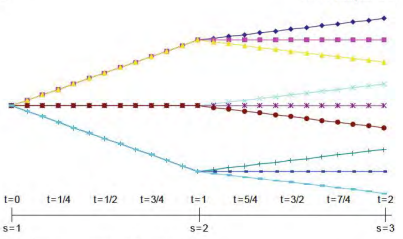
Our backtest will involve a telescoping horizon as depicted in Figure $4 .$
At each decision time $t$ the parameters of the stochastic processes driving the stock return and the three factors of the term structure model are re-calibrated using historical data up to and including time $t$ and the initial values of the simulated scenarios are given by the actual historical values of the variables at these times. Re-calibrating the simulator parameters at each successive initial decision time $t$ captures information in the history of the variables up to that point.
Although the optimal second and later-stage decisions of a given problem may be of “what-if” interest, manager and decision maker focus is on the implementable first-stage decisions which are hedged against the simnlated future uncertainties The reasons for implementing stochastic optimization programmes in this way are twofold. Firstly, after one year has passed the actual values of the variables realized may not coincide with any of the values of the variables in the simulated scenarios. In this case the optimal investment policy would be undefined, as the model only has
optimal decisions defined for the nodes on the simulated scenarios. Secondly, as one more year has passed new information has become available to re-calibrate the simulator’s parameters. Relying on the original optimal investment strategies will ignore this information. For more on backtesting procedures for stochastic optimization models see Dempster et al. (2003).
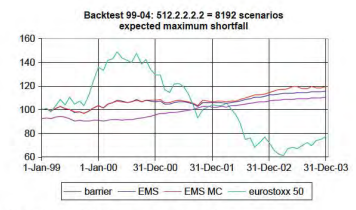
For our backtests we will use three different tree structures with approximately the same number of scenarios, but with an increasing initial branching factor. We first solve the five-year problem using a $6.6 .6 .6 .6$ tree, which gives 7776 scenarios. Then we use $32.4 .4 .4 .4=8192$ scenarios and finally the extreme case of $512.2 .2 .2 .2=8192$ scenarios.
统计代写|金融中的随机方法作业代写Stochastic Methods in Finance代考|Robustness of Backtest Results
Empirical equity returns are now well known not to be normally distributed but rather to exhibit complex behaviour including fat tails. To investigate how the EMS MC model performs with more realistic asset return distributions we report in this section experiments using a geometric Brownian motion with Poisson jumps to model equity returns. The stock price process $\mathbf{S}$ is now assumed to follow
$$
\frac{d \mathbf{S}{t}}{\mathbf{S}{t}}=\bar{\mu}{S} d t+\tilde{\sigma}{S} d \overline{\mathbf{W}}{t}^{S}+\mathbf{J}{t} d \mathbf{N}_{t}
$$
where $\mathbf{N}$ is an independent Poisson process with intensity $\lambda$ and the jump saltus $\mathbf{J}$ at Poisson epochs is a normal random variable.
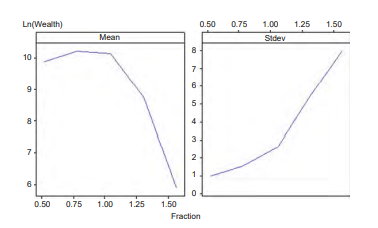
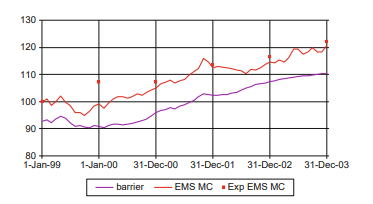
As the EMS MC model and the $512.2 .2 .2 .2$ tree provided the best results with Gaussian returns the backtest is repeated for this model and treesize. Figure 12 gives the historical backtest results and Tables 5 and 6 represent the allocations for the $512.2 .2 .2 .2$ tests with the EMS MC model for the original GBM process and the GBM with Poisson jumps process respectively. The main difference in the two tables is that the investment in equity is substantially lower initially when the equity index volatility is high (going down to $0.1 \%$ when the volatility is $28 \%$ in 2001 ), but then increases as the volatility comes down to $23 \%$ in 2003 . This is born out by Figure 12 which shows much more realistic in-sample one-year-ahead portfolio wealth predictions (cf. Figure 10$)$ and a 140 basis point increase in terminal historical fund return over the Gaussian model. These phenomena are the result of the calibration of the normal jump saltus distributions to have negative means and hence more downward than upwards jumps resulting in downwardly skewed equity index return distributions, but with the same compensated drift as in the GBM case.
金融中的随机方法代写
统计代写|金融中的随机方法作业代写Stochastic Methods in Finance代考|Pricing Coupon-Bearing Bonds
由于难以获得足够的欧元附息国债的历史数据,我们使用零息票收益率曲线来构建相关债券。新发行债券的票面利率一般与当时对应的即期利率密切相关,因此当前的零票面收益率与到期吨用于代表有息票到期的国债的票面利率吨. 例如,在场景ω票面利率d2乙10(ω)当时新发行的 10 年期国债吨=2将设定为等于预计的 10 年期即期汇率是2,10(ω)有时吨=2.
一般来说
d吨乙(吨)(ω)=是吨,吨(ω)∀吨∈吨d∀ω∈Ω d吨乙(吨)(ω)=d⌊吨⌋(吨)(ω)∀吨∈吨一世∀ω∈Ω,
其中L.”表示整数部分。这确保了随着收益率曲线的下降,新发行债券的票面利率将相应下降,每笔票面现金流量将以适当的零票面收益率贴现。
假设债券每半年支付一次息票。由于我们每年滚动债券,因此将在六个月后收到息票,并在债券出售前一年再次收到票息。这迫使我们区分在再平衡时出售债券的价格和购买新债券的价格。
让磷吨,乙(吨)(卖 表示债券的售价乙(吨)有时吨,假设现在已经支付了两张息票并且到期时间等于吨−1, 然后让磷吨,乙(吨)(虽然 )表示新发行的附息国债的价格,期限等于吨.
当时的“买入”债券价格吨是(谁)给的
乙吨吨(ω)=F乙吨和−(吨+⌊吨]−吨)是吨,吨+⌊吨∣−吨(ω) +∑s=|2|2+12,⌊2⌋∣2+1,…,[吨]+吨d一种吨(ω)2F乙吨和−(s−吨)是吨,吨X−吨)(ω)
其中债券的本金在第一期贴现,在第二期贴现付息流。
在再平衡时吨债券的售价由下式给出
乙吨吨(ω)=F乙吨和−(吨−1)是一世,吨−1(ω)+∑s=12,1,…,吨−1d一世−1乙吨(ω)2F乙吨和−(s−吨)是,(ω−吨)(ω)
\omega \in \Omega \quad t \in\left{T^{d} \反斜杠{0}\right} \cup{T}\omega \in \Omega \quad t \in\left{T^{d} \反斜杠{0}\right} \cup{T}以票面利率d吨−1乙吨(ω). 然后为新发行的相同期限的国债重置票面利率。我们假设在六个月内支付的息票被重新投资于期外债券。这对持有的债券金额进行了以下调整乙吨有时吨
统计代写|金融中的随机方法作业代写Stochastic Methods in Finance代考|Historical Backtests
我们将看一个历史回测,其中统计模型适合交易时间的数据吨和场景树生成到一些选定的地平线吨+吨. 然后及时实施最佳根节点决策吨并与当时的历史回报率相比吨+1. 之后,整个过程向前滚动 T 个交易时间。
我们的回测将涉及如图所示的伸缩视野4.
在每个决策时间吨驱动股票收益的随机过程参数和期限结构模型的三个因素使用历史数据重新校准,包括时间吨模拟场景的初始值由这些时间变量的实际历史值给出。在每个连续的初始决策时间重新校准模拟器参数吨捕获该点之前的变量历史信息。
尽管给定问题的最佳第二阶段和后期决策可能具有“假设”的兴趣,但经理和决策者的重点是可实施的第一阶段决策,这些决策可以对冲模拟的未来不确定性 实施随机优化的原因这种方式的程序是双重的。首先,在一年过去之后,实际变量的实际值可能与模拟场景中的任何变量值不一致。在这种情况下,最优投资政策将是不确定的,因为模型只有
为模拟场景中的节点定义的最佳决策。其次,随着一年又过去了,新信息可用于重新校准模拟器的参数。依靠原来的最优投资策略会忽略这些信息。有关随机优化模型的回测程序的更多信息,请参阅 Dempster 等人。(2003 年)。
对于我们的回测,我们将使用三种不同的树结构,它们的场景数量大致相同,但初始分支因子会增加。我们首先使用一个解决五年问题6.6.6.6.6树,它给出了 7776 个场景。然后我们使用32.4.4.4.4=8192场景,最后是极端情况512.2.2.2.2=8192情景。
统计代写|金融中的随机方法作业代写Stochastic Methods in Finance代考|Robustness of Backtest Results
现在众所周知,经验股票收益不是正态分布的,而是表现出复杂的行为,包括肥尾。为了研究 EMS MC 模型如何在更现实的资产回报分布中执行,我们在本节中报告了使用具有泊松跳跃的几何布朗运动来模拟股票回报的实验。股价过程小号现在假设遵循
d小号吨小号吨=μ¯小号d吨+σ~小号d在¯吨小号+Ĵ吨dñ吨
在哪里ñ是具有强度的独立泊松过程λ和跳跃的盐Ĵ在 Poisson epochs 是一个正态随机变量。
作为 EMS MC 模型和512.2.2.2.2树提供了高斯返回的最佳结果,为此模型和树大小重复回测。图 12 给出了历史回测结果,表 5 和表 6 代表了512.2.2.2.2分别使用 EMS MC 模型对原始 GBM 过程和具有泊松跳跃过程的 GBM 进行测试。两个表的主要区别在于,当股票指数波动性较高时(下降至0.1%当波动率为28%2001 年),但随着波动性下降至23%2003 年。图 12 证明了这一点,该图显示了样本内未来一年投资组合财富预测更为现实(参见图 10)与高斯模型相比,最终历史基金回报增加了 140 个基点。这些现象是正态跳跃盐度分布校准为负均值的结果,因此向下跳跃多于向上跳跃,导致股指收益分布向下倾斜,但补偿漂移与 GBM 情况相同。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。统计代写|python代写代考
随机过程代考
在概率论概念中,随机过程是随机变量的集合。 若一随机系统的样本点是随机函数,则称此函数为样本函数,这一随机系统全部样本函数的集合是一个随机过程。 实际应用中,样本函数的一般定义在时间域或者空间域。 随机过程的实例如股票和汇率的波动、语音信号、视频信号、体温的变化,随机运动如布朗运动、随机徘徊等等。
贝叶斯方法代考
贝叶斯统计概念及数据分析表示使用概率陈述回答有关未知参数的研究问题以及统计范式。后验分布包括关于参数的先验分布,和基于观测数据提供关于参数的信息似然模型。根据选择的先验分布和似然模型,后验分布可以解析或近似,例如,马尔科夫链蒙特卡罗 (MCMC) 方法之一。贝叶斯统计概念及数据分析使用后验分布来形成模型参数的各种摘要,包括点估计,如后验平均值、中位数、百分位数和称为可信区间的区间估计。此外,所有关于模型参数的统计检验都可以表示为基于估计后验分布的概率报表。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
statistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
机器学习代写
随着AI的大潮到来,Machine Learning逐渐成为一个新的学习热点。同时与传统CS相比,Machine Learning在其他领域也有着广泛的应用,因此这门学科成为不仅折磨CS专业同学的“小恶魔”,也是折磨生物、化学、统计等其他学科留学生的“大魔王”。学习Machine learning的一大绊脚石在于使用语言众多,跨学科范围广,所以学习起来尤其困难。但是不管你在学习Machine Learning时遇到任何难题,StudyGate专业导师团队都能为你轻松解决。
多元统计分析代考
基础数据: $N$ 个样本, $P$ 个变量数的单样本,组成的横列的数据表
变量定性: 分类和顺序;变量定量:数值
数学公式的角度分为: 因变量与自变量
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。