如果你也在 怎样代写信息论information theory这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
信息理论是对数字信息的量化、存储和通信的科学研究。该领域从根本上是由哈里-奈奎斯特和拉尔夫-哈特利在20世纪20年代以及克劳德-香农在20世纪40年代的作品所确立的。该领域处于概率论、统计学、计算机科学、统计力学、信息工程和电气工程的交叉点。
statistics-lab™ 为您的留学生涯保驾护航 在代写信息论information theory方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写信息论information theory代写方面经验极为丰富,各种代写信息论information theory相关的作业也就用不着说。
我们提供的信息论information theory及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
数学代写|信息论作业代写information theory代考|Introduction to Information Theory
DVD disk or streamed directly to our smart phones. Email and web addresses are commonly visible on business cards. Most of the people today prefer to send emails and e-cards to their friends rather than the regular snail mail. Stock quotes and cricket scores can be checked using the mobile phone. ‘Selfies’ can be captured and uploaded on social media sites with just a click of a button.
DID YOU 2 Information has become a key to success (it has always been the key to success, but in today’s KNOW $=$ world it is the key). And behind all this exchange of information lie the tiny l’s and 0 ‘s (the omnipresent bits) that hold the information by the mere way they sit next to one another. Yet the present day’s information age owes primarily to a seminal paper published in 1948 that laid the foundation of the wonderful field of Information Theory-a theory that was initiated by one man, the American Electrical Engineer Claude E. Shannon, whose ideas appeared in the article “The Mathematical Theory of Communication” in the Bell System Technical Journal (1948). In its broadest sense, information is interpreted to include the messages occurring in any of the standard communications media, such as telephone, radio, or television, and the signals involved in electronic computers, electromechanical systems, and other data-processing devices. The theory is even applicable to the signals appearing in the nerve networks of humans and other animals.
The chief concern of information theory is to discover mathematical laws governing systems designed to communicate or manipulate information. It sets up quantitative measures of information and of the capacity of various systems to transmit, store, and otherwise process information. Some of the problems treated are related to finding the best methods of using various available communication systems and the best methods for separating the wanted information, or signal, from the extraneous information, or noise. Another problem is the setting of upper bounds on what it is possible to achieve with a given information-carrying medium (often called an information channel). While the results are chiefly of the interest to communication engineers, some of the concepts have been adopted and found useful in fields like psychology and linguistics. The notion of mutual information has also found applications in population based gene mapping, whose aim is to find DNA regions (genotypes) responsible for particular traits (phenotypes).
数学代写|信息论作业代写information theory代考|Uncertainty and Information
Any information source produces an output that is random in nature. If the source output had no randomness, i.e., the output were known exactly, there would be no need to transmit it! There exist both analog and discrete information sources. Actually, we live in an analog world, and most sources Understanding the concep are analog sources, for example, speech, temperature fluctuations, etc. The of information. discrete sources are man made sources, for example, a source (say, a man) that generates a sequence of letters from a finite alphabet (while typing email).
Before we go on to develop a mathematical measure of information, let us develop an intuitive feel for it. Read the following sentences:
(A) Tomorrow, the sun will rise from the East.
(B) The phone will ring in the next one hour.
(C) It will snow in Delhi this winter.
- The three sentences carry different amounts of information. In fact, the first sentence hardly carries any information. It is a sure-shot thing. Everybody knows that the sun rises from the East and the Intuition probability of this happening again is almost unity ( ” Making predictions is risky, especially when it involves the future.” – N. Bohr). Sentence (B) appears to carry more information than sentence (A). The phone may ring, or it may not. There is a finite probability that the phone will ring in the next one hour (unless the maintenance people are at work again). The last sentence probably made you read it over twice. This is because it has never snowed in Delhi, and the probability of a snowfall is very low. It is interesting to note that the amount of information carried by the sentences listed above have something to do with the probability of occurrence of the events stated in the sentences. And we observe an inverse relationship. Sentence (A), which talks about an event which has a probability of occurrence very close to 1 carries almost no information. Sentence $(\mathrm{C})$, which has a very low probability of occurrence, appears to carry a lot of information (made us read it twice to be sure we got the information right!). The other interesting thing to note is that the length of the sentence has nothing to do with the amount of information it conveys. In fact, sentence (A) is the longest of the three sentences but carries the minimum information.
We will now develop a mathematical measure of information.
数学代写|信息论作业代写information theory代考|Average Mutual Information and Entropy
So far we have studied the mutual information associated with a pair of events $x_{i}$ and $y_{j}$ which are the possible outcomes of the two random variables $X$ and $Y$. We now want to find out the average mutual information between the two random variables. This can be obtained simply by weighting $I\left(x_{i} ; y_{j}\right)$ by the probability of occurrence of the joint event and summing over all possible joint events.
Definition 1.4 The Average Mutual Information between two random variables $X$ and $Y$ is given by
$$
\begin{aligned}
I(X ; Y) &=\sum_{i=1}^{n} \sum_{j=1}^{m} P\left(x_{i}, y_{j}\right) I\left(x_{i} ; y_{j}\right)=\sum_{i=1}^{n} \sum_{j=1}^{m} P\left(x_{i}, y_{j}\right) \log \frac{P\left(x_{i}, y_{j}\right)}{P\left(x_{i}\right) P\left(y_{j}\right)} \
&=\sum_{i=1}^{n} \sum_{j=1}^{m} P\left(x_{i}\right) P\left(y_{j} \mid x_{i}\right) \log \frac{P\left(y_{j} \mid x_{i}\right)}{P\left(y_{j}\right)} \
&=\sum_{j=1}^{m} \sum_{i=1}^{n} P\left(y_{j}\right) P\left(x_{i} \mid y_{j}\right) \log \frac{P\left(x_{i} \mid y_{j}\right)}{P\left(x_{i}\right)}
\end{aligned}
$$
For the case when $X$ and $Y$ are statistically independent, $I(X ; Y)=0$, i.e., there is no average mutual information between $X$ and $Y$. An important property of the average mutual information is that $I(X ; Y) \geq 0$, with equality if and only if $X$ and $Y$ are statistically independent.
Definition 1.5 The Average Self Information of a random variable $X$ is defined as
$$
H(X)=\sum_{i=1}^{n} P\left(x_{i}\right) I\left(x_{i}\right)=-\sum_{i=1}^{n} P\left(x_{i}\right) \log P\left(x_{i}\right)
$$
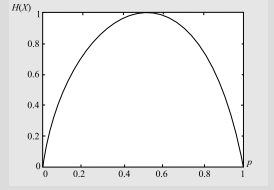
When $X$ represents the alphabet of possible output letters from a source, $H(X)$ represents the average information per source letter. In this case $H(X)$ is called the entropy. The entropy of $X$ can be interpreted as the expected value of $\log \left(\frac{1}{P(X)}\right)$. The term entropy has been borrowed from statistical mechanics, where it is used to denote the level of disorder in a system. It is interesting to see that the Chinese character for entropy looks like !
We observe that since $0 \leq P\left(x_{i}\right) \leq 1, \log \left(\frac{1}{P\left(x_{i}\right)}\right) \geq 0$. Hence, $H(X) \geq 0$.
信息论代写
数学代写|信息论作业代写information theory代考|Introduction to Information Theory
DVD 光盘或直接流式传输到我们的智能手机。电子邮件和网址通常在名片上可见。今天的大多数人更喜欢向他们的朋友发送电子邮件和电子贺卡,而不是普通的蜗牛邮件。可以使用手机查看股票报价和板球比分。只需单击一个按钮,即可在社交媒体网站上捕获并上传“自拍”。
DID YOU 2 信息已成为成功的关键(它一直是成功的关键,但在今天的 KNOW=世界,它是关键)。在所有这些信息交换的背后,隐藏着微小的 l 和 0(无所不在的位),它们仅靠彼此相邻的方式来保存信息。然而,当今的信息时代主要归功于 1948 年发表的一篇开创性论文,该论文奠定了信息论这一奇妙领域的基础——这一理论由美国电气工程师克劳德·E·香农发起,他的想法出现在贝尔系统技术期刊(1948 年)中的文章“通信的数学理论”。在最广泛的意义上,信息被解释为包括在任何标准通信媒体(如电话、收音机或电视)中出现的消息,以及电子计算机、机电系统和其他数据处理设备中涉及的信号。
信息论的主要关注点是发现管理旨在交流或操纵信息的系统的数学规律。它建立了信息和各种系统传输、存储和以其他方式处理信息的能力的定量测量。所处理的一些问题与寻找使用各种可用通信系统的最佳方法以及从无关信息或噪声中分离所需信息或信号的最佳方法有关。另一个问题是设定使用给定的信息承载媒介(通常称为信息通道)可能实现的目标的上限。虽然结果主要引起了通信工程师的兴趣,但其中一些概念已被采用并发现在心理学和语言学等领域很有用。
数学代写|信息论作业代写information theory代考|Uncertainty and Information
任何信息源都会产生本质上随机的输出。如果源输出没有随机性,即输出是完全已知的,就没有必要传输了!存在模拟和离散信息源。实际上,我们生活在一个模拟世界中,而大多数来源理解概念都是模拟来源,例如,语音、温度波动等信息。离散源是人造源,例如,从有限的字母表(在键入电子邮件时)生成一系列字母的源(例如,一个人)。
在我们继续开发信息的数学度量之前,让我们对它进行直观的感觉。阅读以下句子:
(A) 明天,太阳将从东方升起。
(B) 电话将在接下来的一小时内响起。
(C) 今年冬天德里会下雪。
- 这三个句子携带的信息量不同。事实上,第一句话几乎没有任何信息。这是肯定的事情。每个人都知道太阳从东方升起,这种再次发生的直觉概率几乎是统一的(“做出预测是有风险的,尤其是当它涉及到未来时。” – N. Bohr)。句子 (B) 似乎比句子 (A) 包含更多信息。电话可能响,也可能不响。电话在接下来的一小时内响铃的概率是有限的(除非维修人员再次上班)。最后一句话可能让你读了两遍。这是因为德里从来没有下过雪,下雪的概率很低。有趣的是,上面列出的句子所携带的信息量与句子中所述事件的发生概率有关。我们观察到一个反比关系。句子 (A) 谈论发生概率非常接近 1 的事件,几乎没有任何信息。句子(C),它的发生概率非常低,似乎携带了很多信息(让我们阅读了两次以确保我们得到了正确的信息!)。另一个值得注意的有趣的事情是,句子的长度与它传达的信息量无关。事实上,句子 (A) 是三个句子中最长的,但携带的信息最少。
我们现在将开发一种信息的数学度量。
数学代写|信息论作业代写information theory代考|Average Mutual Information and Entropy
到目前为止,我们已经研究了与一对事件相关的互信息X一世和是j这是两个随机变量的可能结果X和是. 我们现在想要找出两个随机变量之间的平均互信息。这可以简单地通过加权来获得一世(X一世;是j)通过联合事件的发生概率和所有可能的联合事件的总和。
定义 1.4 两个随机变量之间的平均互信息X和是是(谁)给的
一世(X;是)=∑一世=1n∑j=1米磷(X一世,是j)一世(X一世;是j)=∑一世=1n∑j=1米磷(X一世,是j)日志磷(X一世,是j)磷(X一世)磷(是j) =∑一世=1n∑j=1米磷(X一世)磷(是j∣X一世)日志磷(是j∣X一世)磷(是j) =∑j=1米∑一世=1n磷(是j)磷(X一世∣是j)日志磷(X一世∣是j)磷(X一世)
对于这种情况X和是是统计独立的,一世(X;是)=0,即之间没有平均互信息X和是. 平均互信息的一个重要性质是一世(X;是)≥0, 相等当且仅当X和是是统计独立的。
定义 1.5 随机变量的平均自信息X定义为
H(X)=∑一世=1n磷(X一世)一世(X一世)=−∑一世=1n磷(X一世)日志磷(X一世)
什么时候X表示来自源的可能输出字母的字母表,H(X)表示每个源字母的平均信息。在这种情况下H(X)称为熵。的熵X可以解释为期望值日志(1磷(X)). 熵这个术语是从统计力学中借来的,用来表示系统中的无序程度。有趣的是,熵的汉字看起来像 !
我们观察到,因为0≤磷(X一世)≤1,日志(1磷(X一世))≥0. 因此,H(X)≥0.

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。