如果你也在 怎样代写计算复杂性理论computational complexity theory这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
计算复杂性理论computational complexity theory的重点是根据资源使用情况对计算问题进行分类,并将这些类别相互联系起来。计算问题是一项由计算机解决的任务。一个计算问题是可以通过机械地应用数学步骤来解决的,比如一个算法。
statistics-lab™ 为您的留学生涯保驾护航 在代写计算复杂性理论computational complexity theory方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写计算复杂性理论computational complexity theory代写方面经验极为丰富,各种代写计算复杂性理论相关的作业也就用不着说。
我们提供的计算复杂性理论computational complexity theory及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
数学代考|计算复杂性理论代写computational complexity theory代考|Definition of the Subject
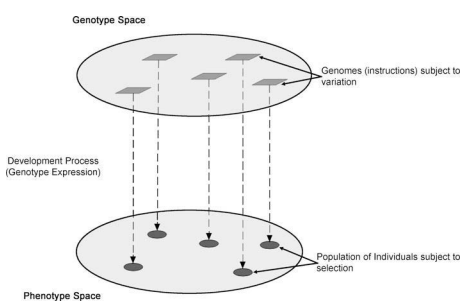
Agent-based modeling began as the computational arm of artificial life some 20 years ago. Artificial life is concerned with the emergence of order in nature. How do systems self-organize themselves and spontaneously achieve a higher-ordered state? Agent-based modeling then, is concerned with exploring and understanding the processes that lead to the emergence of order through computational means. The essential features of artificial life models are translated into computational algorithms through agent-based modeling. With its historical roots in artificial life, agent-based modeling has become a distinctive form of modeling and simulation. Agent-based modeling is a bottom-up approach to modeling complex systems by explicitly representing the behaviors of large numbers of agents and the processes by which they interact. These essential features are all that is needed to produce at least rudimentary forms of emergent behavior at the systems level. To understand the current state of agent-based modeling and where the field aspires to be in the future, it is necessary to understand the origins of agent-based modeling in artificial life.
数学代考|计算复杂性理论代写computational complexity theory代考|Introduction
The field of Artificial Life, or ${ }^{\alpha}$ ALife, $”$ is intimately connected to Agent-Based Modeling, or “ABM.” Although one can easily enumerate some of life’s distinctive properties, such as reproduction, respiration, adaptation, emergence, etc., a precise definition of life remains elusive.
Artificial Life had its inception as a coherent and sustainable field of investigation at a workshop in the late 1980 s [43]. This workshop drew together specialists from diverse fields who had been working on related problems in different guises, using different vocabularies suited to their fields.
At about the same time, the introduction of the personal computer suddenly made computing accessible, convenient, inexpensive and compelling as an experimental tool. The future seemed to have almost unlimited possibilities for the development of ALife computer programs to explore life and its possibilities. Thus several ALife software programs emerged that sought to encapsulate the essential elements of life through incorporation of ALife-related algorithms into easily usable software packages that could be widely distributed. Computational programs for modeling populations of digital organisms, such as Tierra, Avida, and Echo, were developed along with more general purpose agent-based simulators such as Swarm.
Yet, the purpose of ALife was never restricted to understanding or re-creating life as it exists today. According to Langton:
Artificial systems which exhibit lifelike behaviors are worthy of investigation on their own right, whether or not we think that the processes that they mimic have played a role in the development or mechanics of life as we know it to be. Such systems can help us expand our understanding of life as it could be. (p. xvi in [43])
The field of ALife addresses life-like properties of systems at an abstract level by focusing on the information content of such systems independent of the medium in which they exist, whether it be biological, chemical, physical or in silico. This means that computation, modeling, and simulation play a central role in ALife investigations.
The relationship between ALife and ABM is complex. A case can be made that the emergence of ALife as a field was essential to the creation of agent-based modeling. Computational tools were both required and became possible in the 1980 s for developing sophisticated models of digital organisms and general purpose artificial life simulators. Likewise, a case can be made that the possibility for creating agent-based models was essential to making ALife a promising and productive endeavor. ABM made it possible to understand the logical outcomes and implications of ALife models and life-like processes. Traditional analytical means, although valuable in establishing baseline information, were limited in their capabilities to include essential features of ALife. Many threads of ALife are still intertwined with developments in $\mathrm{ABM}$ and vice verse. Agent-based models demonstrate the emergence of lifelike features using ALife frameworks; ALife algorithms are widely used in agent-based models to represent agent behaviors. These threads are explored in this article. In ALife terminology, one could say that ALife and ABM have $C O-$ evolved to their present states. In all likelihood they will continue to do so.
数学代考|计算复杂性理论代写computational complexity theory代考|Self-Replication and Cellular Automata
Self-Replication and Cellular Automata Artificial Life traces its beginnings to the work of John von Neumann in the 1940 s and investigations into the theoretical possibilities for developing a self-replicating machine [64]. Such a self-replicating machine not only carries instructions for its operations, but also for its replication. The issue concerned how to replicate such a machine that contained the instructions for its operation along with the instructions for its replication. Did a machine to replicate such a machine need to contain both the instructions for the machine’s operation and replication, as well as instructions for replicating the instructions on how to replicate the original machine? (see Fig. 1). Von Neumann used the abstract mathematical construct of cellular automata, originally conceived in discussions with Stanislaw Ulam, to prove that such a machine could be designed, at least in theory. Von Neumann was never able to build such a machine due to the lack of sophisticated computers that existed at the time.
Cellular automata (CA) have been central to the development of computing Artificial Life models. Virtually all of the early agent-based models that required agents to be spatially located were in the form of von Neumann’s original cellular automata. A cellular automata is a finitestate machine in which time and space are treated as discrete rather than continuous, as would be the case, for example in differential equation models. A typical CA is a two-dimensional grid or lattice consisting of cells. Each cell assumes one of a finite number of states at any time. A cell’s neighborhood is the set of cells surrounding a cell, typically, a five-cell neighborhood (von Neumann neighborhood) or a nine-cell neighborhood (Moore neighborhood), as in Fig. $2 .$
A set of simple state transition rules determines the value of each cell based on the cell’s state and the states of neighboring cells. Every cell is updated at each time according to the transition rules. Each cell is identical in terms of its update rules. Cells differ only in their initial states. A CA is deterministic in the sense that the same state for a cell and its set of neighbors always results in the same updated state for the cell. Typically, CAs are set up with periodic boundary conditions, meaning that the set of cells on one edge of the grid boundary are the neighbor cells to the cells on the opposite edge of the grid boundary. The space of the CA grid forms a surface on a toroid, or donut-shape, so there is no boundary per se. It is straightforward to extend the notion of cellular automata to two, three, or more dimensions.
计算复杂性理论代写
数学代考|计算复杂性理论代写computational complexity theory代考|Definition of the Subject
大约 20 年前,基于代理的建模开始作为人工生命的计算臂。人工生命关注的是自然界秩序的出现。系统如何自我组织并自发达到更高的有序状态?那么,基于代理的建模关注的是通过计算手段探索和理解导致秩序出现的过程。通过基于代理的建模将人工生命模型的基本特征转化为计算算法。凭借其在人工生命中的历史渊源,基于代理的建模已成为建模和模拟的一种独特形式。基于代理的建模是一种自下而上的复杂系统建模方法,它通过显式表示大量代理的行为以及它们交互的过程。这些基本特征是在系统层面产生至少基本形式的紧急行为所需要的。要了解基于代理的建模的当前状态以及该领域未来的目标,有必要了解基于代理的建模在人工生命中的起源。
数学代考|计算复杂性理论代写computational complexity theory代考|Introduction
人工生命领域,或一种生命,”与基于代理的建模或“ABM”密切相关。尽管人们可以很容易地列举出生命的一些独特属性,例如繁殖、呼吸、适应、出现等,但对生命的精确定义仍然难以捉摸。
人工生命在 1980 年代后期的一次研讨会上作为一个连贯且可持续的研究领域开始兴起 [43]。本次研讨会汇集了来自不同领域的专家,他们以不同的形式使用适合其领域的不同词汇来解决相关问题。
大约在同一时间,个人计算机的引入突然使计算成为一种易于使用、方便、廉价和引人注目的实验工具。未来似乎拥有开发 ALife 计算机程序以探索生命及其可能性的几乎无限可能。因此,出现了几个 ALife 软件程序,它们试图通过将与 ALife 相关的算法合并到可以广泛分发的易于使用的软件包中来封装生活的基本要素。用于模拟数字生物种群的计算程序(例如 Tierra、Avida 和 Echo)与更通用的基于代理的模拟器(例如 Swarm)一起开发。
然而,ALife 的目的从未局限于理解或重新创造当今存在的生活。根据兰顿的说法:
表现出逼真行为的人工系统本身就值得研究,无论我们是否认为它们模仿的过程在我们所知的生命发展或机制中发挥了作用。这样的系统可以帮助我们扩大对生命的理解。(第 xvi 页,[43])
ALife 领域通过关注此类系统的信息内容,在抽象层面解决系统的类生命属性,而这些信息内容独立于它们存在的介质,无论是生物、化学、物理还是计算机。这意味着计算、建模和模拟在 ALife 调查中发挥着核心作用。
ALife 和 ABM 之间的关系很复杂。可以证明,ALife 作为一个领域的出现对于创建基于代理的建模至关重要。在 1980 年代,计算工具既是必需的,也是可能的,用于开发复杂的数字生物模型和通用人工生命模拟器。同样,可以证明创建基于代理的模型的可能性对于使 ALife 成为有前途和富有成效的努力至关重要。ABM 使理解 ALife 模型和栩栩如生的过程的逻辑结果和含义成为可能。传统的分析手段,虽然在建立基线信息方面很有价值,但在包含 ALife 基本特征的能力方面受到限制。ALife 的许多主线仍然与一种乙米反之亦然。基于代理的模型使用 ALife 框架展示了栩栩如生的特征的出现;ALife 算法广泛用于基于代理的模型中来表示代理行为。本文探讨了这些线程。在 ALife 术语中,可以说 ALife 和 ABM 具有C这−进化到现在的状态。他们很可能会继续这样做。
数学代考|计算复杂性理论代写computational complexity theory代考|Self-Replication and Cellular Automata
自我复制和元胞自动机人工生命可以追溯到约翰·冯·诺依曼在 1940 年代的工作以及对开发自我复制机器的理论可能性的研究[64]。这样一台自我复制的机器不仅携带着它的操作指令,而且还携带着它的复制指令。问题涉及如何复制这样的机器,该机器包含其操作指令及其复制指令。复制这样一台机器的机器是否需要同时包含机器操作和复制的指令,以及如何复制原始机器的复制指令?(见图 1)。Von Neumann 使用了元胞自动机的抽象数学结构,最初是在与 Stanislaw Ulam 的讨论中构思的,证明可以设计这样的机器,至少在理论上是这样。由于当时缺乏复杂的计算机,冯·诺依曼永远无法制造出这样的机器。
元胞自动机 (CA) 一直是计算人工生命模型开发的核心。几乎所有需要代理在空间上定位的早期基于代理的模型都是冯诺依曼最初的元胞自动机的形式。元胞自动机是一种有限状态机,其中时间和空间被视为离散的而不是连续的,例如在微分方程模型中就是这种情况。典型的 CA 是由单元组成的二维网格或点阵。每个单元在任何时候都假定为有限数量的状态之一。一个单元的邻域是一个单元周围的一组单元,通常是一个五单元邻域(冯诺依曼邻域)或一个九单元邻域(摩尔邻域),如图 1 所示。2.
一组简单的状态转换规则根据单元的状态和相邻单元的状态确定每个单元的值。每个单元格每次都根据转换规则进行更新。每个单元格的更新规则都是相同的。细胞的不同之处仅在于它们的初始状态。CA 是确定性的,即一个小区及其邻居集的相同状态总是导致该小区相同的更新状态。通常,CA 设置有周期性边界条件,这意味着网格边界一个边缘上的一组单元格是网格边界另一边上的单元格的相邻单元格。CA 网格的空间在环形或甜甜圈形状上形成一个表面,因此本身没有边界。将元胞自动机的概念扩展到两个、三个或更多维度是很简单的。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。