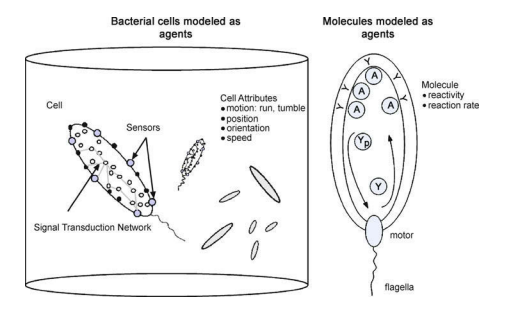
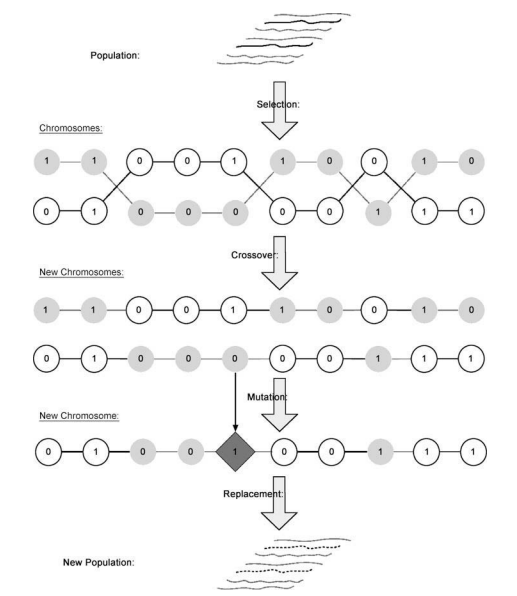
数学代考|计算复杂性理论代写computational complexity theory代考|Agent Based Modeling and Computer Languages
如果你也在 怎样代写计算复杂性理论computational complexity theory这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
计算复杂性理论computational complexity theory的重点是根据资源使用情况对计算问题进行分类,并将这些类别相互联系起来。计算问题是一项由计算机解决的任务。一个计算问题是可以通过机械地应用数学步骤来解决的,比如一个算法。
statistics-lab™ 为您的留学生涯保驾护航 在代写计算复杂性理论computational complexity theory方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写计算复杂性理论computational complexity theory代写方面经验极为丰富,各种代写计算复杂性理论相关的作业也就用不着说。
我们提供的计算复杂性理论computational complexity theory及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
数学代考|计算复杂性理论代写computational complexity theory代考|Types of Computer Languages
A ‘computer language’ is a method of noting directives for computers. ‘Computer programming languages,’ or ‘programming languages,’ are an important category of computer languages. A programming language is a computer language that allows any computable activity to be expressed. This article focuses on computer programming languages rather than the more general computer languages since virtually all agent-based modeling systems require the power of programming languages. This article sometimes uses the simpler term ‘computer languages’ when referring to computer programming languages. According to Watson [47]:
Programming languages are used to describe algorithms, that is, sequences of steps that lead to the
solution of problems … A programming language can be considered to be a ‘notation’ that can be used to specify algorithms with precision.
Watson [47] goes on to say that “programming languages can be roughly divided into four groups: imperative languages, functional languages, logic programming languages, and others”. Watson [47] states that in imperative languages “there is a fundamental underlying dependence on the assignment operation and on variables implemented as computer memory locations, whose contents can be read and altered”. However, “in functional languages (sometimes called applicative languages) the fundamental operation is function application” [47]. Watson cites LISP as an example. Watson [47] continues by noting that “in a logic programming language, the programmer needs only to supply the problem specification in some formal form, as it is the responsibility of the language system to infer a method of solution”.
A useful feature of most functional languages, many logic programming languages, and some imperative languages is higher-order programming. According to Reynolds [35]:
In analogy with mathematical logic, we will say that a programming language is higher-order if procedures or labels can occur as data, i. e., if these entities can be used as arguments to procedures, as results of functions, or as values of assignable variables. A language that is not higher-order will be called first-order.
Watson [47] offers that “another way of grouping programming languages is to classify them as procedural or declarative languages”. Elaborating, Watson [47] states that:
Procedural languages … are those in which the action of the program is defined by a series of operations defined by the programmer. To solve a problem, the programmer has to specify a series of steps (or statements) which are executed in sequence.
数学代考|计算复杂性理论代写computational complexity theory代考|Requirements of Computer Languages for Agent-Based Modeling
The requirements of computer languages for agent-based modeling and simulation include the following:
- There is a need to create well defined modules that correspond to agents. These modules should bind together agent state data and agent behaviors into integrated independently addressable constructs. Ideally these mod-
ules will be flexible enough to change structure over time and to optionally allow fuzzy boundaries to implement models that go beyond methodological individualism [20].
- There is a need to create well defined containers that correspond to agent environments. Ideally these containers will be recursively nestable or will otherwise support sophisticated definitions of containment.
- There is a need to create well defined spatial relationships within agent environments. These relationships should include notions of abstract space (e.g., lattices), physical space (e.g., maps), and connectedness (e.g. networks).
- There is a need to easily setup model configurations such as the number of agents; the relationships between agents; the environmental details; and the results to be collected.
- There is a need to conveniently collect and analyze model results.
Each of the kinds of programming languages namely, unstructured languages, structured languages, object-oriented languages, logic-based languages, and functional languages can address these requirements.
Unstructured languages generally support procedure definitions which can be used to implement agent behaviors. They also sometimes support the collection of diverse data into independently addressable constructs in the form of data structures often called ‘records’. However, they generally lack support for binding procedures to individual data items or records of data items. This lack of support for creating integrated constructs also typically limits the language-level support for agent containers. Native support for implementing spatial environments is similarly limited by the inability to directly bind procedures to data.
As discussed in the previous section, unstructured languages offer statements to implement execution jumps. The use of jumps within and between procedures tends to reduce module cohesion and increase module coupling compared to structured code. The result is reduced code maintainability and extensibility compared to structured solutions. This is a substantial disadvantage of unstructured languages.
数学代考|计算复杂性理论代写computational complexity theory代考|Domain-Specific Languages
Domain-specific languages (DSL’s) are computer languages that are highly customized to support a well defined application area or ‘domain’. DSL’s commonly include a substantial number of keywords that are nouns and verbs in the area of application as well as overall structures and execution patterns that correspond closely with the application area. DSL’s are intended to allow users to write in a language that is closely aligned with their area of expertise.
DSL’s often gain their focus by losing generality. For many DSL’s there are activities that can be programmed in most computer languages that cannot be programmed in the given DSL. This is consciously done to simplify the DSL’s design and make it easier to learn and use. If a DSL is properly designed then the loss of generality is often inconsequential for most uses since the excluded activities are chosen to be outside the normal range of application. However, even the best designed DSL’s can occasionally be restrictive when the bounds of the language are encountered. Some DSL’s provide special extension points that allow their users to program in a more general language such as C or Java when the limits of the DSL are reached. This feature is extremely useful, but requires more sophistication on the part of the user in that they need to know and simultaneously use both the DSL and the general language.
DSL’s have the potential to implement specific features to support ‘design patterns’ within a given domain. Design patterns form a “common vocabulary” describing tried and true solutions for commonly faced software design problems (Coplien [6]). Software design patterns were popularized by Gamma et al. [13]. North and Macal [29] describe three design patterns for agent-based modeling itself.
计算复杂性理论代写
数学代考|计算复杂性理论代写computational complexity theory代考|Types of Computer Languages
“计算机语言”是一种记录计算机指令的方法。“计算机编程语言”或“编程语言”是计算机语言的一个重要类别。编程语言是一种允许表达任何可计算活动的计算机语言。本文重点关注计算机编程语言,而不是更通用的计算机语言,因为几乎所有基于代理的建模系统都需要编程语言的强大功能。在提及计算机编程语言时,本文有时会使用更简单的术语“计算机语言”。根据 Watson [47]:
编程语言用于描述算法,即导致
问题的解决方案……编程语言可以被认为是一种“符号”,可以用来精确地指定算法。
Watson [47] 继续说“编程语言可以大致分为四组:命令式语言、函数式语言、逻辑编程语言等”。Watson [47] 指出,在命令式语言中“存在对赋值操作和实现为计算机内存位置的变量的基本潜在依赖,其内容可以被读取和更改”。然而,“在函数式语言(有时称为应用程序语言)中,基本操作是函数应用程序”[47]。Watson 以 LISP 为例。Watson [47] 继续指出“在逻辑编程语言中,程序员只需要以某种形式提供问题规范,因为推断解决方法是语言系统的责任”。
大多数函数式语言、许多逻辑编程语言和一些命令式语言的一个有用特性是高阶编程。根据 Reynolds [35]:
类似于数学逻辑,如果过程或标签可以作为数据出现,即如果这些实体可以用作过程的参数,作为函数的结果,我们将说编程语言是高阶的,或作为可分配变量的值。不是高阶语言将被称为一阶语言。
Watson [47] 提出“对编程语言进行分组的另一种方法是将它们分类为过程性或声明性语言”。详细说明,Watson [47] 指出:
过程语言……是那些程序的动作由程序员定义的一系列操作定义的语言。为了解决一个问题,程序员必须指定一系列按顺序执行的步骤(或语句)。
数学代考|计算复杂性理论代写computational complexity theory代考|Requirements of Computer Languages for Agent-Based Modeling
基于代理的建模和仿真对计算机语言的要求包括:
- 需要创建与代理相对应的定义良好的模块。这些模块应该将代理状态数据和代理行为绑定到集成的独立可寻址结构中。理想情况下,这些 mod-
规则将足够灵活,可以随着时间的推移改变结构,并可选择允许模糊边界来实现超越方法论个人主义的模型[20]。
- 需要创建与代理环境相对应的定义良好的容器。理想情况下,这些容器将是递归可嵌套的,或者将支持复杂的包含定义。
- 需要在代理环境中创建明确定义的空间关系。这些关系应该包括抽象空间(例如格子)、物理空间(例如地图)和连通性(例如网络)的概念。
- 需要轻松设置模型配置,例如代理数量;代理人之间的关系;环境细节;以及要收集的结果。
- 需要方便地收集和分析模型结果。
每种编程语言,即非结构化语言、结构化语言、面向对象语言、基于逻辑的语言和函数式语言都可以满足这些要求。
非结构化语言通常支持可用于实现代理行为的过程定义。它们有时还支持以通常称为“记录”的数据结构形式将各种数据收集到可独立寻址的结构中。但是,它们通常缺乏对将过程绑定到单个数据项或数据项记录的支持。缺乏对创建集成构造的支持通常也限制了对代理容器的语言级支持。对实现空间环境的本机支持同样受到无法将过程直接绑定到数据的限制。
如上一节所述,非结构化语言提供语句来实现执行跳转。与结构化代码相比,在过程内部和过程之间使用跳转往往会降低模块内聚并增加模块耦合。与结构化解决方案相比,结果是降低了代码的可维护性和可扩展性。这是非结构化语言的一大缺点。
数学代考|计算复杂性理论代写computational complexity theory代考|Domain-Specific Languages
领域特定语言 (DSL) 是高度定制以支持明确定义的应用领域或“领域”的计算机语言。DSL 通常包括应用领域中大量的名词和动词关键字,以及与应用领域密切对应的整体结构和执行模式。DSL 旨在允许用户使用与其专业领域密切相关的语言进行编写。
DSL 经常通过失去通用性来获得他们的关注。对于许多 DSL,有一些活动可以用大多数计算机语言进行编程,而这些活动不能用给定的 DSL 进行编程。有意识地这样做是为了简化 DSL 的设计并使其更易于学习和使用。如果 DSL 设计得当,那么对于大多数用途来说,一般性的损失通常是无关紧要的,因为被排除的活动被选择在正常的应用范围之外。然而,即使是设计最好的 DSL 有时也会在遇到语言边界时受到限制。一些 DSL 提供了特殊的扩展点,允许用户在达到 DSL 的限制时使用更通用的语言(例如 C 或 Java)进行编程。这个功能非常有用,
DSL 有可能实现特定功能以支持给定域内的“设计模式”。设计模式形成了一个“通用词汇”,描述了针对常见软件设计问题的经过验证的真实解决方案(Coplien [6])。Gamma 等人推广了软件设计模式。[13]。North 和 Macal [29] 描述了基于代理的建模本身的三种设计模式。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。