如果你也在 怎样代写机器学习Machine Learning 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning是一个致力于理解和建立 “学习 “方法的研究领域,也就是说,利用数据来提高某些任务的性能的方法。机器学习算法基于样本数据(称为训练数据)建立模型,以便在没有明确编程的情况下做出预测或决定。机器学习算法被广泛用于各种应用,如医学、电子邮件过滤、语音识别和计算机视觉,在这些应用中,开发传统算法来执行所需任务是困难的或不可行的。
机器学习Machine Learning程序可以在没有明确编程的情况下执行任务。它涉及到计算机从提供的数据中学习,从而执行某些任务。对于分配给计算机的简单任务,有可能通过编程算法告诉机器如何执行解决手头问题所需的所有步骤;就计算机而言,不需要学习。对于更高级的任务,由人类手动创建所需的算法可能是一个挑战。在实践中,帮助机器开发自己的算法,而不是让人类程序员指定每一个需要的步骤,可能会变得更加有效 。
statistics-lab™ 为您的留学生涯保驾护航 在代写机器学习 machine learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写机器学习 machine learning代写方面经验极为丰富,各种代写机器学习 machine learning相关的作业也就用不着说。
计算机代写|机器学习代写machine learning代考|Development
Having a poor development practice for ML projects can manifest itself in a multitude of ways that can completely kill a project. Though usually not as directly visible as some of the other leading causes, having a fragile and poorly designed code base and poor development practices can make a project harder to work on, easier to break in production, and far harder to improve as time goes on.
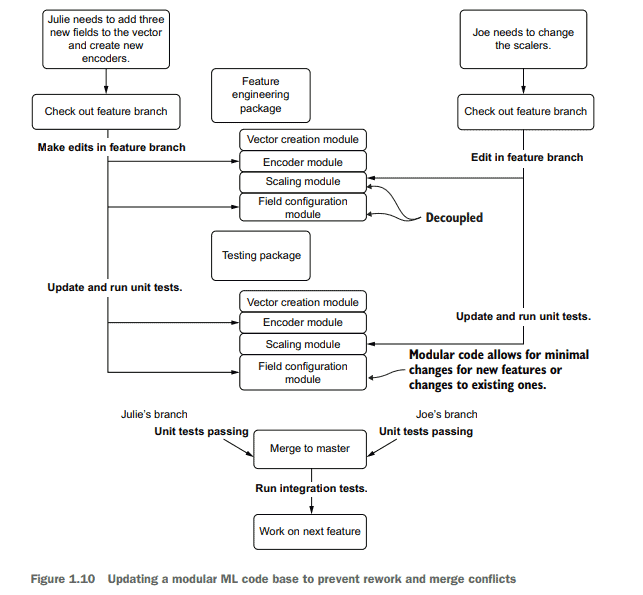
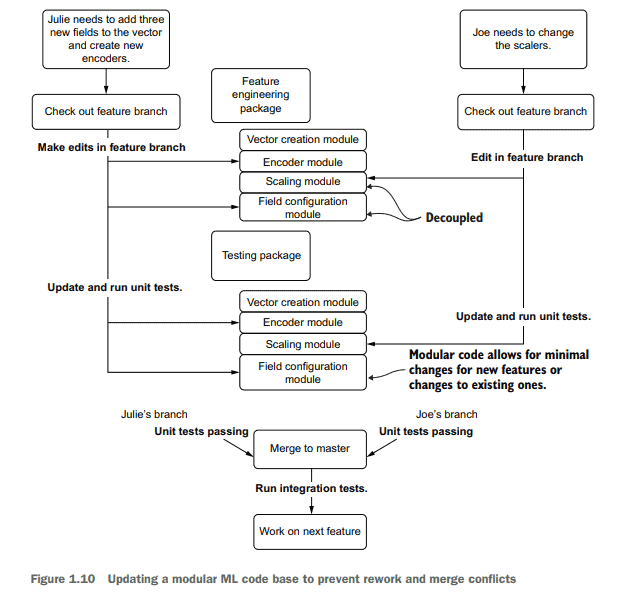
For instance, let’s look at a rather simple and frequent modification situation that comes up during the development of a modeling solution: changes to the feature engineering. In figure 1.9 , we see two data scientists attempting to make a set of changes in a monolithic code base. In this development paradigm, all the logic for the entire job is written in a single notebook through scripted variable declarations and functions.
Julie, in the monolithic code base, will likely have a lot of searching and scrolling to do, finding each individual location where the feature vector is defined and adding her new fields to collections. Her encoding work will need to be correct and carried throughout the script in the correct places as well. It’s a daunting amount of work for any sufficiently complex ML code base (as the number of code lines for feature engineering and modeling combined can reach to the thousands if developed in a scripting paradigm) and is prone to frustrating errors in the form of omissions, typos, and other transcription mistakes.
Joe, meanwhile, has far fewer edits to do. But he is still subject to the act of searching through the long code base and relying on editing the hardcoded values correctly.
The real problem with the monolithic approach comes when they try to incorporate each of their changes into a single copy of the script. As they have mutual dependencies on each other’s work, both will have to update their code and select one of their copies to serve as a master for the project, copying in the changes from the other’s work. This long and arduous process wastes precious development time and likely will require a great deal of debugging to get correct.
Figure 1.10 shows a different approach to maintaining an ML project’s code base. This time, a modularized code architecture separates the tight coupling that is present within the large script from figure 1.9.
计算机代写|机器学习代写machine learning代考|Deployment
Not planning a project around a deployment strategy is like having a dinner party without knowing how many guests are showing up. You’ll either be wasting money or ruining experiences.
Perhaps the most confusing and complex part of ML project work for newer teams is in how to build a cost-effective deployment strategy. If it’s underpowered, the prediction quality doesn’t matter (since the infrastructure can’t properly serve the predictions). If it’s overpowered, you’re effectively burning money on unused infrastructure and complexity.
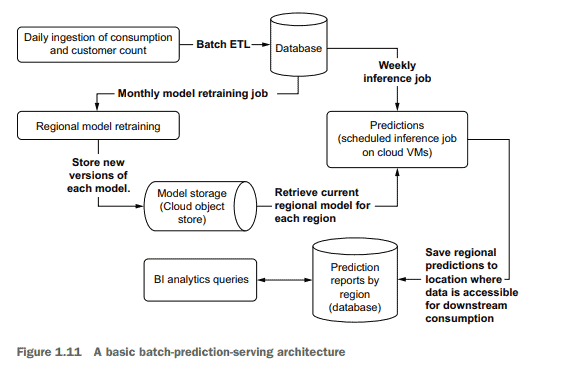
As an example, let’s look at an inventory optimization problem for a fast-food company. The DS team has been fairly successful in serving predictions for inventory management at region-level groupings for years, running large batch predictions for the per-day demands of expected customer counts at a weekly level, and submitting forecasts as bulk extracts each week. Up until this point, the DS team has been accustomed to an ML architecture that effectively looks like that shown in figure 1.11 .
This relatively standard architecture for serving up scheduled batch predictions focuses on exposing results to internal analytics personnel who provide guidance on quantities of materials to order. This prediction-serving architecture isn’t particularly complex and is a paradigm that the DS team members are familiar with. With the scheduled synchronous nature of the design, as well as the large amounts of time between subsequent retraining and inference, the general sophistication of their technology stack doesn’t have to be particularly high (which is a good thing; see the following sidebar).
As the company realizes the benefits of predictive modeling over time with these batch approaches, its faith in the DS team increases. When a new business opportunity arises that requires near-real-time inventory forecasting at a per-store level, company executives ask the DS team to provide a solution for this use case.
机器学习代考
计算机代写|机器学习代写machine learning代考|Development
对于ML项目来说,糟糕的开发实践可能会以多种方式表现出来,从而彻底扼杀一个项目。虽然通常不像其他一些主要原因那样直接可见,但拥有一个脆弱和设计不良的代码库和糟糕的开发实践会使项目更难进行,更容易在生产中中断,并且随着时间的推移更难改进。
例如,让我们看看在建模解决方案的开发过程中出现的一个相当简单和频繁的修改情况:对特征工程的更改。在图1.9中,我们看到两个数据科学家试图在一个单一的代码库中做一组更改。在这种开发范例中,整个作业的所有逻辑都通过脚本变量声明和函数写在一个笔记本中。
在整体代码库中,Julie可能需要进行大量的搜索和滚动,找到每个定义了特征向量的单独位置,并将她的新字段添加到集合中。她的编码工作需要是正确的,并在整个剧本中正确的地方进行。对于任何足够复杂的ML代码库来说,这都是一项令人生畏的工作(因为如果在脚本范例中开发,用于特征工程和建模的代码行数可以达到数千行),并且容易出现令人沮丧的错误,如遗漏、拼写错误和其他转录错误。
与此同时,乔要做的编辑要少得多。但是他仍然受制于搜索长代码库的行为,并依赖于正确编辑硬编码值。
当他们试图将每个更改合并到脚本的单个副本中时,整体方法的真正问题就出现了。由于它们相互依赖于彼此的工作,因此双方都必须更新自己的代码,并选择其中一个副本作为项目的主副本,从对方的工作中复制更改。这个漫长而艰巨的过程浪费了宝贵的开发时间,并且可能需要进行大量的调试才能获得正确的结果。
图1.10显示了维护ML项目代码库的另一种方法。这一次,模块化的代码体系结构分离了图1.9中大脚本中出现的紧密耦合。
计算机代写|机器学习代写machine learning代考|Deployment
不根据部署策略来规划项目就像举办一个不知道有多少客人出席的晚宴。你要么在浪费钱,要么毁了你的经历。
对于新团队来说,ML项目工作中最令人困惑和复杂的部分可能是如何构建具有成本效益的部署策略。如果它的功能不足,预测质量就无关紧要了(因为基础设施不能正确地为预测服务)。如果它过于强大,你就会在未使用的基础设施和复杂性上有效地烧钱。
作为一个例子,让我们看看一家快餐公司的库存优化问题。多年来,DS团队在为区域级分组的库存管理提供预测服务方面相当成功,在每周水平上对预期客户数量的每日需求进行大量预测,并每周以批量摘要的形式提交预测。到目前为止,DS团队已经习惯了如图1.11所示的ML体系结构。
这种提供计划批预测的相对标准的体系结构侧重于向内部分析人员公开结果,这些分析人员提供关于订购材料数量的指导。这种预测服务体系结构不是特别复杂,是DS团队成员熟悉的范例。由于设计的计划同步性质,以及随后的再训练和推理之间的大量时间,他们的技术堆栈的一般复杂性不必特别高(这是一件好事;请参阅下面的侧栏)。
随着时间的推移,公司意识到这些批处理方法的预测建模的好处,它对DS团队的信心也在增加。当出现需要在每个商店级别进行近乎实时的库存预测的新业务机会时,公司高管要求DS团队为该用例提供解决方案。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。