如果你也在 怎样代写多元统计分析Multivariate Statistical Analysis这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
多变量统计分析被认为是评估地球化学异常与任何单独变量和变量之间相互影响的意义的有用工具。
statistics-lab™ 为您的留学生涯保驾护航 在代写多元统计分析Multivariate Statistical Analysis方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写多元统计分析Multivariate Statistical Analysis代写方面经验极为丰富,各种代写多元统计分析Multivariate Statistical Analysis相关的作业也就用不着说。
我们提供的多元统计分析Multivariate Statistical Analysis及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|多元统计分析代写Multivariate Statistical Analysis代考|Scatterplots
Scatterplots are bivariate or trivariate plots of variables against each other. They help us understand relationships among the variables of a data set. A downward-sloping scatter indicates that as we increase the variable on the horizontal axis, the variable on the vertical axis decreases. An analogous statement can be made for upward-sloping scatters.
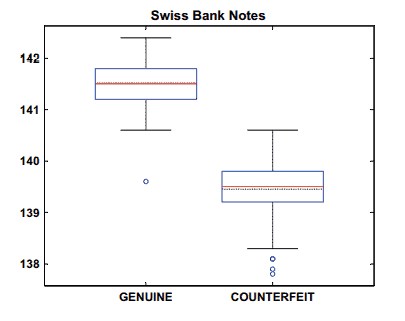
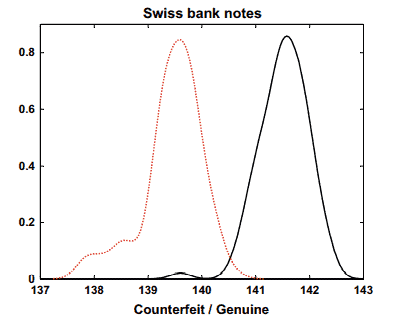
Figure $1.12$ plots the fifth column (upper inner frame) of the bank data against the sixth column (diagonal). The scatter is downward-sloping. As we already know from the previous section on marginal comparison (e.g., Fig. 1.9) a good separation between genuine and counterfeit banknotes is visible for the diagonal variable. The sub-cloud in the upper half (circles) of Fig. $1.12$ corresponds to the true banknotes. As noted before, this separation is not distinct, since the two groups overlap somewhat.
This can be verified in an interactive computing environment by showing the index and coordinates of certain points in this scatterplot. In Fig. 1.12, the 70th observation in the merged data set is given as a thick circle, and it is from a genuine bank note. This observation lies well embedded in the cloud of counterfeit banknotes. One straightforward approach that could be used to tell the counterfeit from the genuine banknotes is to draw a straight line and define notes above this value as genuine. We would, of course, misclassify the 70th observation, but can we do better?
If we extend the two-dimensional scatterplot by adding a third variable, e.g., $X_4$ (lower distance to inner frame), we obtain the scatterplot in three dimensions as shown in Fig. 1.13. It becomes apparent from the location of the point clouds that a better separation is obtained. We have rotated the three-dimensional data until this satisfactory 3D view was obtained. Later, we will see that the rotation is the same as bunding a high-dimensional observation into one or more linear combinations of the elements of the observation vector. In other words, the “separation line” parallel to the horizontal coordinate axis in Fig. $1.12$ is, in Fig. 1.13, a plane and no longer parallel to one of the axes. The formula for such a separation plane is a linear combination of the elements of the observation vector:
$$
a_1 x_1+a_2 x_2+\cdots+a_6 x_6=\text { const. }
$$
The algorithm that automatically finds the weights $\left(a_1, \ldots, a_6\right)$ will be investigated later on in Chap. 14.
Let us study yet another technique: the scatterplot matrix. If we want to draw all possible two-dimensional scatterplots for the variables, we can create a so-called draftsman’s plot (named after a draftsman who prepares drafts for parliamentary discussions). Similar to a draftsman’s plot the scatterplot matrix helps in creating new ideas and in building knowledge about dependencies and structure.
统计代写|多元统计分析代写Multivariate Statistical Analysis代考|Chernoff-Flury Faces
If we are given a data in a numerical form, we tend to also display it numerically. This was done in the preceding sections: an observation $x_1=(1,2)$ was plotted as the point $(1,2)$ in a two-dimensional coordinate system. In multivariate analysis, we want to understand data in low dimensions (e.g., on a $2 \mathrm{D}$ computer screen) although the structures are hidden in high dimensions. The numerical display of data structures using coordinates, therefore, ends at dimensions greater than three.
If we are interested in condensing a structure into 2 D elements, we have to consider alternative graphical techniques. The Chernoff-Flury faces, for example, provide such a condensation of high-dimensional information into a simple “face”. In fact, faces are a simple way of graphically displaying high-dimensional data. The size of the face elements like pupils, eyes, upper and lower hair line, etc., are assigned to certain variables. The idea of using faces goes back to Chernoff (1973) and has been further developed by Bernhard Flury. We follow the design described in Flury and Riedwyl (1988) which uses the following characteristics:
First, every variable that is to be coded into a characteristic face element is transformed into a $(0,1)$ scale, i.e., the minimum of the variable corresponds to 0 and the maximum to 1 . The extreme positions of the face elements, therefore, correspond to a certain “grin” or “happy” face element. Dark hair might be coded as 1, and blond hair as 0 and so on.
As an example, consider the observations 91 to 110 of the bank data. Recall that the bank data set consists of 200 observations of dimension 6 where, for example, $X_6$ is the diagonal of the note. If we assign the six variables to the following face elements:
$$
\begin{aligned}
& X_1=1,19 \text { (eye sizes) } \
& X_2=2,20 \text { (pupil sizes) } \
& X_3=4,22 \text { (eye slants) } \
& X_4=11,29 \text { (upper hair lines) } \
& X_5=12,30 \text { (lower hair lines) } \
& X_6=13,14,31,32 \text { (face lines and darkness of hair), }
\end{aligned}
$$
we obtain Fig. 1.15.
Also recall that observations 1-100 correspond to the genuine notes, and that observations 101-200 correspond to the counterfeit notes. The counterfeit banknotes then correspond to the upper half of Fig. 1.15. In fact, the faces for these observations look more grim and less happy. The variable $X_6$ (diagonal) already worked well in the boxplot on Fig. 1.4 in distinguishing between the counterfeit and genuine notes. Here, this variable is assigned to the face line and the darkness of the hair. That is why we clearly see a good separation within these 20 observations.
What happens if we include all 100 genuine and all 100 counterfeit banknotes in the Chernoff-Flury face technique? Figure $1.16$ shows the faces of the genuine banknotes with the same assignments as used before and Fig. 1.17 shows the faces of the counterfeit banknotes. Comparing Figs. $1.16$ and $1.17$ one clearly sees that the diagonal (face line) is longer for genuine banknotes. Equivalently coded is the hair darkness (diagonal) which is lighter (shorter) for the counterfeit banknotes. One sees that the faces of the genuine banknotes have a much darker appearance and have broader face lines. The faces in Fig. $1.16$ are obviously different from the ones in Fig. 1.17.
多元统计分析代考
统计代写|多元统计分析代写Multivariate Statistical Analysis代考|Scatterplots
散点图是变量相互之间的双变量或三变量图。它们帮助我们理解数据集变量之间的关系。向下倾斜的散点表示随着我们增加水平轴上的变量,垂直轴上的变量减少。对于向上倾斜的散点可以做出类似的陈述。
数字1.12根据第六列(对角线)绘制银行数据的第五列(上部内框)。散点是向下倾斜的。正如我们从前面关于边际比较的部分(例如图 1.9)中已经知道的那样,对角线变量可以很好地区分真钞和假钞。图上半部分(圆圈)的子云。1.12对应真钞。如前所述,这种分离并不明显,因为这两个组有些重叠。
这可以在交互式计算环境中通过显示此散点图中某些点的索引和坐标来验证。在图 1.12 中,合并数据集中的第 70 个观察值以粗圆圈给出,它来自真钞。这一观察结果很好地嵌入了假钞云中。一种可用于区分伪钞和真钞的直接方法是画一条直线并将高于此值的钞票定义为真钞。当然,我们会对第 70 个观察结果进行错误分类,但我们能做得更好吗?
如果我们通过添加第三个变量来扩展二维散点图,例如,X4(到内框的距离更近),我们得到了三个维度的散点图,如图 1.13 所示。从点云的位置可以明显看出获得了更好的分离。我们旋转了三维数据,直到获得令人满意的 3D 视图。稍后,我们将看到旋转与将高维观测值捆绑为观测向量元素的一个或多个线性组合相同。换句话说,平行于图1中横坐标轴的“分离线”。1.12在图 1.13 中是一个平面,不再平行于其中一个轴。这种分离平面的公式是观察向量元素的线性组合:
一个1X1+一个2X2+⋯+一个6X6= 常量。
自动找到权重的算法(一个1,…,一个6)将在稍后的章节中进行调查。14.
让我们研究另一种技术:散点图矩阵。如果我们想为变量绘制所有可能的二维散点图,我们可以创建一个所谓的绘图员图(以为议会讨论准备草案的绘图员命名)。类似于制图员的绘图,散点图矩阵有助于创造新想法以及建立有关依赖性和结构的知识。
统计代写|多元统计分析代写Multivariate Statistical Analysis代考|Chernoff-Flury Faces
如果给我们一个数字形式的数据,我们也倾向于以数字形式显示它。这是在前面的部分中完成的:观察X1=(1,2)被绘制为点(1,2)在二维坐标系中。在多变量分析中,我们希望了解低维数据(例如,在2丁电脑屏幕)虽然结构隐藏在高维度中。因此,使用坐标的数据结构的数字显示以大于三的维度结束。
如果我们有兴趣将结构压缩成二维元素,我们必须考虑替代图形技术。例如,Chernoff-Flury 面孔将高维信息浓缩到一张简单的“面孔”中。事实上,人脸是一种以图形方式显示高维数据的简单方式。瞳孔、眼睛、上下发际线等面部元素的大小被分配给某些变量。使用面孔的想法可以追溯到 Chernoff (1973),并由 Bernhard Flury 进一步发展。我们遵循 Flury 和 Riedwyl (1988) 中描述的设计,该设计使用以下特征:
首先,将要编码为特征人脸元素的每个变量转换为(0,1)scale,即变量的最小值对应于 0 ,最大值对应于 1 。因此,面部元素的极端位置对应于某个“咧嘴笑”或“快乐”的面部元素。深色头发可能编码为 1,金色头发编码为 0,依此类推。
例如,考虑银行数据的观察值 91 到 110。回想一下,银行数据集由 200 个维度 6 的观察值组成,例如,X6是音符的对角线。如果我们将六个变量分配给以下面元素:
X1=1,19 (眼睛大小) X2=2,20 (瞳孔大小) X3=4,22 (眼睛倾斜) X4=11,29 (上发际线) X5=12,30 (下发际线) X6=13,14,31,32 (面部线条和头发的深色),
我们得到图 1.15。
还记得观察值 1-100 对应于真钞,观察值 101-200 对应于假币。伪钞对应于图 1.15 的上半部分。事实上,这些观察结果的面孔看起来更冷酷,更不快乐。变量X6(对角线)在图 1.4 的箱线图中已经很好地区分了假钞和真钞。在这里,这个变量被分配给面部线条和头发的黑度。这就是为什么我们在这 20 个观察结果中清楚地看到了很好的分离。
如果我们将所有 100 张真钞和所有 100 张假钞都包含在 Chernoff-Flury 面部技术中,会发生什么情况?数字1.16图 1.17 显示了具有与之前使用的相同分配的真钞的面,图 1.17 显示了伪钞的面。比较无花果。1.16和1.17可以清楚地看到,真钞的对角线(面线)更长。等效编码是假钞的发色(对角线)较浅(较短)。可以看到,真钞的正面颜色更深,线条更宽。图中的人脸。1.16与图 1.17 中的明显不同。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。