统计代写|商业分析作业代写Statistical Modelling for Business代考|Excel, MegaStat, and Minitab for Statistics
如果你也在 怎样代写商业分析Statistical Modelling for Business这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
商业分析就是利用数据分析和统计的方法,来分析企业之前的商业表现,从而通过分析结果来对未来的商业战略进行预测和指导 。
statistics-lab™ 为您的留学生涯保驾护航 在代写商业分析Statistical Modelling for Business方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写商业分析Statistical Modelling for Business方面经验极为丰富,各种代写商业分析Statistical Modelling for Business相关的作业也就用不着说。
我们提供的商业分析Statistical Modelling for Business及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|商业分析作业代写Statistical Modelling for Business代考|Excel, MegaStat, and Minitab for Statistics
In this book we use three types of software to carry out statistical analysis – Excel 2013, MegaStat, and Minitab $17 .$ Excel is, of course, a general purpose electronic spreadsheet program and analytical tool. The analysis ToolPak in Excel includes many procedures for performing various kinds of basic statistical analyses. MegaStat is an add-in package that is specifically designed for performing statistical analysis in the Excel spreadsheet environment. Minitab is a computer package designed expressly for conducting statistical analysis. It is widely used at many colleges and universities and in a large number of business organizations. The principal advantage of Excel is that, because of its broad acceptance among students and professionals as a multipurpose analytical tool, it is both well-known and widely available. The advantages of a special-purpose statistical software package like Minitab are that it provides a far wider range of statistical procedures and it offers the experienced analyst a range of options to better control the analysis. The advantages of MegaStat include (1) its ability to perform a number of statistical calculations that are not automatically done by the procedures in the Excel ToolPak and (2) features that make it easier to use than Excel for a wide variety of statistical analyses. In addition, the output obtained by using MegaStat is automatically placed in a standard Excel spreadsheet and can be edited by using any of the features in Excel. MegaStat can be copied from the book’s website. Excel, MegaStat, and Minitab, through built-in functions, programming languages, and macros, offer almost limitless power. Here, we will limit our attention to procedures that are easily accessible via menus without resorting to any special programming or advanced features.
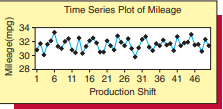
Commonly used features of Excel 2013, MegaStat, and Minitab 17 are presented in this chapter along with an initial application-the construction of a time series plot of the gas mileages in Table 1.7. You will find that thẻ limited instructions included hêré, alông with thê built-in hêlp féatures ớ all thieê sơftware packages, will serve as a starting point from which you can discover a variety of other procedures and options. Much more detailed descriptions of Minitab 17 can be found in other sources, in particular in the manual Getting Started with Minitab $17 .$ This manual is available as a pdf file, viewable using Adobe Acrobat Reader, on the Minitab Inc. website-go to http://www.minitab.com/en-us/support/documentation/ to download the manual. This manual is also available online at http://support.minitab.com/en-us/minitab/17/getting-started/. Similarly, there are a number of alternative reference materials for Microsoft Excel 2013. Of course, an understanding of the related statistical concepts is essential to the effective use of any statistical software package.
统计代写|商业分析作业代写Statistical Modelling for Business代考|Getting Started with Excel
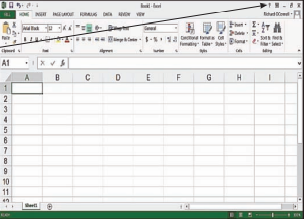
Because Excel 2013 may be new to some readers, and because the Excel 2013 window looks somewhat different from previous versions of Excel, we will begin by describing some characteristics of the Excel 2013 window. Versions of Excel prior to 2007 employed many drop-down menus. This meant that many features were “hidden” from the user, which resulted in a steep learning curve for beginners. Beginning with Excel 2010, Microsoft tried to reduce the number of features that are hidden in drop-down menus. Therefore, Excel 2013 displays all of the applicable commands needed for a particular type of task at the top of the Excel window. These commands are represented by a tab-and-group arrangement called the ribbon-see the right side of the illustration of an Excel 2013 window on the next page. The commands displayed in the ribbon are regulated by a series of tabs located near the top of the ribbon. For example, in the illustration, the Home tab is selected. If we selected a different tab, say, for example, the Page Layout tab, the commands displayed by the ribbon would be different.
We now briefly describe some basic features of the Excel 2013 window:
1 File button: By clicking on this button, the user obtains a menu of often used commands-for example, Open, Save, Print, and so forth. This menu also provides access to a large number of Excel options settings.
$2 \mathrm{~ T a ̉ b s : ~ C l i c k i n g ̄ ~ o ̄ n ~ a ~ t a b b ~ r e ̂ s u l t s ~ i n ~ a ~ r i b b o ́ n ~ đ i s p l a y ~ o ̛ f ~ f e ̉ a t u}$ type of task. For example, when the Home tab is selected (as in the figure), the features, commands, and options displayed by the ribbon are all related to making entries into the Excel worksheet. As another example, if the Formulas tab is selected, all of the features, commands, and options displayed in the ribbon relate to using formulas in the Excel worksheet.
Appendix $1.1$
Getting Started with Excel
3 Quick access toolbar: This toolbar displays buttons that provide shortcuts to often-used commands. Initially, this toolbar displays Save, Undo, and Redo buttons. The user can customize this toolbar by adding shortcut buttons for other commands (such as New, Open, Quick Print, and so forth). This can be done by clicking on the arrow button directly to the right of the Quick Access toolbar and by making selections from the “Customize” drop-down menu that appears.
统计代写|商业分析作业代写Statistical Modelling for Business代考|Select Home : Format : Row Height
This notation indicates that we first select the Home tab on the ribbon, then we select Format from the Cells Group on the ribbon, and finally we select Row Height from the Format drop-down menu.
For many of the statistical and graphical procedures in Excel, it is necessary to provide a range of cells to specify the location of data in the spreadsheet. Generally, the range may be specified either by typing the cell locations directly into a dialog box or by dragging the selected range with the mouse. Although for the experienced user, it is usually easier to use the mouse to select a range, the instructions that follow will, for precision and clarity, specify ranges by typing in cell locations. The selected range may include column or variable labels-labels at the tops columns that serve to identify variables. When the selected range includes such labels, it is important to select the “Labels check box” in the analysis dialog box.
金融中的随机方法代写
统计代写|商业分析作业代写Statistical Modelling for Business代考|Excel, MegaStat, and Minitab for Statistics
在本书中,我们使用三种类型的软件进行统计分析——Excel 2013、MegaStat 和 Minitab17.Excel 当然是一种通用的电子表格程序和分析工具。Excel 中的分析工具包包括许多用于执行各种基本统计分析的程序。MegaStat 是一个插件包,专为在 Excel 电子表格环境中执行统计分析而设计。Minitab 是专为进行统计分析而设计的计算机软件包。它在许多高校和大量的商业组织中被广泛使用。Excel 的主要优势在于,由于它作为一种多功能分析工具在学生和专业人士中被广泛接受,因此它广为人知且应用广泛。像 Minitab 这样的专用统计软件包的优势在于它提供了范围更广的统计程序,并为经验丰富的分析师提供了一系列选项来更好地控制分析。MegaStat 的优点包括 (1) 能够执行 Excel ToolPak 中的程序无法自动完成的大量统计计算,以及 (2) 比 Excel 更易于使用的各种统计分析功能。此外,使用 MegaStat 获得的输出会自动放置在标准 Excel 电子表格中,并且可以使用 Excel 中的任何功能进行编辑。MegaStat 可以从本书的网站上复制。Excel、MegaStat 和 Minitab 通过内置函数、编程语言和宏,提供几乎无限的功能。这里,
本章介绍 Excel 2013、MegaStat 和 Minitab 17 的常用功能以及初始应用程序 – 表 1.7 中的油耗时间序列图的构建。您会发现包括 hêré 在内的有限说明,以及内置帮助功能 ớ 所有 thieê 软件包,将作为您可以发现各种其他程序和选项的起点。可以在其他来源中找到有关 Minitab 17 的更详细的描述,特别是在 Minitab 入门手册中17.本手册以 PDF 文件的形式提供,可使用 Adobe Acrobat Reader 在 Minitab Inc. 网站上查看 – 请访问 http://www.minitab.com/en-us/support/documentation/ 下载手册。本手册也可从 http://support.minitab.com/en-us/minitab/17/getting-started/ 在线获取。同样,Microsoft Excel 2013 也有许多替代参考资料。当然,了解相关统计概念对于有效使用任何统计软件包都是必不可少的。
统计代写|商业分析作业代写Statistical Modelling for Business代考|Getting Started with Excel
由于 Excel 2013 对某些读者来说可能是新的,并且由于 Excel 2013 窗口看起来与以前版本的 Excel 有所不同,我们将首先描述 Excel 2013 窗口的一些特征。2007 年之前的 Excel 版本使用了许多下拉菜单。这意味着许多功能对用户“隐藏”,导致初学者学习曲线陡峭。从 Excel 2010 开始,Microsoft 尝试减少隐藏在下拉菜单中的功能数量。因此,Excel 2013 在 Excel 窗口顶部显示特定类型任务所需的所有适用命令。这些命令由称为功能区的选项卡和组排列表示 – 请参见下一页 Excel 2013 窗口插图的右侧。功能区中显示的命令由功能区顶部附近的一系列选项卡控制。例如,在插图中,选择了 Home 选项卡。如果我们选择了不同的选项卡,例如“页面布局”选项卡,则功能区显示的命令会有所不同。
我们现在简要介绍一下 Excel 2013 窗口的一些基本功能:
1 文件按钮:通过单击此按钮,用户可以获得一个常用命令菜单,例如打开、保存、打印等。此菜单还提供对大量 Excel 选项设置的访问。
̉đ̛̉2 吨一种̉bs: Cl一世Cķ一世nḠ 这̄n 一种 吨一种bb r和̂s在l吨s 一世n 一种 r一世bb这́n D一世spl一种是 这̛F F和̉一种吨在任务类型。例如,当 Home 选项卡被选中时(如图所示),功能区显示的功能、命令和选项都与在 Excel 工作表中输入条目有关。作为另一个示例,如果选择了“公式”选项卡,则功能区中显示的所有功能、命令和选项都与在 Excel 工作表中使用公式有关。
附录1.1
Excel
3 入门快速访问工具栏:此工具栏显示提供常用命令快捷方式的按钮。最初,此工具栏显示保存、撤消和重做按钮。用户可以通过为其他命令(例如新建、打开、快速打印等)添加快捷按钮来自定义此工具栏。这可以通过直接单击快速访问工具栏右侧的箭头按钮并从出现的“自定义”下拉菜单中进行选择来完成。
统计代写|商业分析作业代写Statistical Modelling for Business代考|Select Home : Format : Row Height
该符号表示我们首先选择功能区上的主页选项卡,然后从功能区上的单元格组中选择格式,最后从格式下拉菜单中选择行高。
对于 Excel 中的许多统计和图形程序,需要提供一系列单元格来指定数据在电子表格中的位置。通常,可以通过直接在对话框中键入单元格位置或通过用鼠标拖动所选范围来指定范围。尽管对于有经验的用户来说,使用鼠标选择范围通常更容易,但为了精确和清晰,下面的说明将通过键入单元格位置来指定范围。选定的范围可以包括列或变量标签——位于顶部列的用于识别变量的标签。当所选范围包括此类标签时,请务必在分析对话框中选中“标签复选框”。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。统计代写|python代写代考
随机过程代考
在概率论概念中,随机过程是随机变量的集合。 若一随机系统的样本点是随机函数,则称此函数为样本函数,这一随机系统全部样本函数的集合是一个随机过程。 实际应用中,样本函数的一般定义在时间域或者空间域。 随机过程的实例如股票和汇率的波动、语音信号、视频信号、体温的变化,随机运动如布朗运动、随机徘徊等等。
贝叶斯方法代考
贝叶斯统计概念及数据分析表示使用概率陈述回答有关未知参数的研究问题以及统计范式。后验分布包括关于参数的先验分布,和基于观测数据提供关于参数的信息似然模型。根据选择的先验分布和似然模型,后验分布可以解析或近似,例如,马尔科夫链蒙特卡罗 (MCMC) 方法之一。贝叶斯统计概念及数据分析使用后验分布来形成模型参数的各种摘要,包括点估计,如后验平均值、中位数、百分位数和称为可信区间的区间估计。此外,所有关于模型参数的统计检验都可以表示为基于估计后验分布的概率报表。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
statistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
机器学习代写
随着AI的大潮到来,Machine Learning逐渐成为一个新的学习热点。同时与传统CS相比,Machine Learning在其他领域也有着广泛的应用,因此这门学科成为不仅折磨CS专业同学的“小恶魔”,也是折磨生物、化学、统计等其他学科留学生的“大魔王”。学习Machine learning的一大绊脚石在于使用语言众多,跨学科范围广,所以学习起来尤其困难。但是不管你在学习Machine Learning时遇到任何难题,StudyGate专业导师团队都能为你轻松解决。
多元统计分析代考
基础数据: $N$ 个样本, $P$ 个变量数的单样本,组成的横列的数据表
变量定性: 分类和顺序;变量定量:数值
数学公式的角度分为: 因变量与自变量
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。