金融代写|风险理论投资组合代写Market Risk, Measures and Portfolio 代考|CONSTRAINED OPTIMIZATION
如果你也在 怎样代写风险理论投资组合这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
为了衡量市场风险,投资者和分析师使用风险值(VaR)方法。风险值建模是一种统计风险管理方法,它可以量化股票或投资组合的潜在损失,以及该潜在损失发生的概率。
statistics-lab™ 为您的留学生涯保驾护航 在代写风险理论投资组合方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写风险理论投资组合代写方面经验极为丰富,各种代写风险理论投资组合相关的作业也就用不着说。
我们提供的风险理论投资组合及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
金融代写|风险理论投资组合代写Market Risk, Measures and Portfolio 代考|CONSTRAINED OPTIMIZATION
In constructing optimization problems solving practical issues, it is very often the case that certain constraints need to be imposed in order for the optimal solution to make practical sense. For example, long-only portfolio optimization problems require that the portfolio weights, which represent the variables in optimization, should be nonnegative and should sum up to one. According to the notation in this chapter, this corresponds to a problem of the type,
$$
\begin{array}{rl}
\min {x} & f(x) \ \text { subject to } & x^{\prime} e=1 \ & x \geq 0, \end{array} $$ where: $f(x)$ is the objective function. $e \in \mathbb{R}^{n}$ is a vector of ones, $e=(1, \ldots, 1)$. $x^{\prime} e$ equals the sum of all components of $x, x^{\prime} e=\sum{i}^{n} x_{i}$.
$x \geq 0$ means that all components of the vector $x \in \mathbb{R}^{n}$ are nonnegative.
In problem (2.10), we are searching for the minimum of the objective function by varying $x$ only in the set
$$
\mathbf{X}=\left{x \in \mathbb{R}^{n}: \begin{array}{l}
x^{\prime} e=1 \
x \geq 0
\end{array}\right}
$$
which is also called the set of feasible points or the constraint set. A more compact notation, similar to the notation in the unconstrained problems, is sometimes used,
$$
\min _{x \in \mathrm{X}} f(x)
$$
where $\mathbf{X}$ is defined in equation (2.11).
We distinguish between different types of optimization problems depending on the assumed properties for the objective function and the constraint set. If the constraint set contains only equalities, the problem is easier to handle analytically. In this case, the method of Lagrange multipliers is applied. For more general constraint sets, when they are formed
by both equalities and inequalities, the method of Lagrange multipliers is generalized by the Karush-Kuhn-Tucker conditions (KKT conditions). Like the first-order conditions we considered in unconstrained optimization problems, none of the two approaches leads to necessary and sufficient conditions for constrained optimization problems without further assumptions. One of the most general frameworks in which the KKT conditions are necessary and sufficient is that of convex programming. We have a convex programing problem if the objective function is a convex function and the set of feasible points is a convex set. As important subcases of convex optimization, linear programming and convex quadratic programming problems are considered.
In this section, we describe first the method of Lagrange multipliers, which is often applied to special types of mean-variance optimization problems in order to obtain closed-form solutions. Then we proceed with convex programming that is the framework for reward-risk analysis. The mentioned applications of constrained optimization problems is covered in Chapters 8,9 , and 10 .
金融代写|风险理论投资组合代写Market Risk, Measures and Portfolio 代考|Lagrange Multipliers
Consider the following optimization problem in which the set of feasible points is defined by a number of equality constraints,
$$
\begin{array}{rl}
\min {x} & f(x) \ \text { subject to } & b{1}(x)=0 \
& b_{2}(x)=0 \
\cdots \
& b_{k}(x)=0
\end{array}
$$
The functions $h_{i}(x), i=1, \ldots, k$ build up the constraint set. Note that even though the right-hand side of the equality constraints is zero in the classical formulation of the problem given in equation $(2.12)$, this is not restrictive. If in a practical problem the right-hand side happens to be different than zero, it can be equivalently transformed, for example,
$$
\left{x \in \mathbb{R}^{n}: v(x)=c\right} \quad \Longleftrightarrow \quad\left{x \in \mathbb{R}^{n}: h_{1}(x)=v(x)-c=0\right} .
$$
In order to illustrate the necessary condition for optimality valid for (2.12), let us consider the following two-dimensional example:
$$
\begin{aligned}
\min _{x \in \mathbb{R}^{2}} & \frac{1}{2} x^{\prime} C x \
\text { subject to } & x^{\prime} e=1,
\end{aligned}
$$
where the matrix is
$$
C=\left(\begin{array}{cc}
1 & 0.4 \
0.4 & 1
\end{array}\right) .
$$
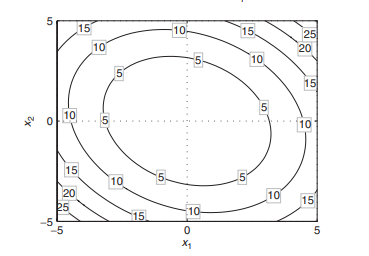
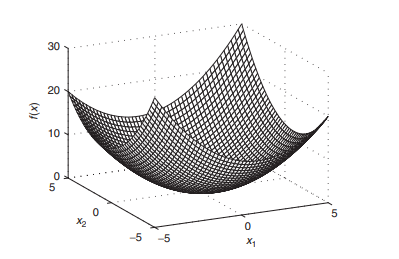
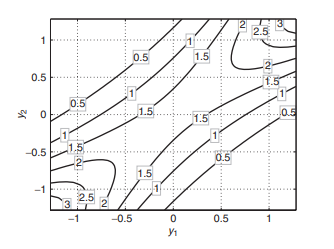
The objective function is a quadratic function and the constraint set contains one linear equality. In Chapter 8, we see that the mean-variance optimization problem in which short positions are allowed is very similar to (2.13). The surface of the objective function and the constraint are shown on the top plot in Figure 2.7. The black line on the surface shows the function values of the feasible points. Geometrically, solving problem (2.13) reduces to finding the lowest point of the black curve on the surface. The contour lines shown on the bottom plot in Figure $2.7$ imply that the feasible point yielding the minimum of the objective function is where a contour line is tangential to the line defined by the equality constraint. On the plot, the tangential contour line and the feasible points are in bold. The black dot indicates the position of the point in which the objective function attains its minimum subject to the constraints.
Even though the example is not general in the sense that the constraint set contains one linear rather than a nonlinear equality, the same geometric intuition applies in the nonlinear case. The fact that the minimum is attained where a contour line is tangential to the curve defined by the nonlinear equality constraints in mathematical language is expressed in the following way: The gradient of the objective function at the point yielding the minimum is proportional to a linear combination of the gradients of the functions defining the constraint set. Formally, this is stated as
$$
\nabla f\left(x^{0}\right)-\mu_{1} \nabla h_{1}\left(x^{0}\right)-\cdots-\mu_{k} \nabla h_{k}\left(x^{0}\right)=0 .
$$
where $\mu_{i}, i=1, \ldots, k$ are some real numbers called Lagrange multipliers and the point $x^{0}$ is such that $f\left(x^{0}\right) \leq f(x)$ for all $x$ that are feasible. Note that if there are no constraints in the problem, then (2.14) reduces to the first-order condition we considered in unconstrained optimization. Therefore, the system of equations behind (2.14) can be viewed as a generalization of the first-order condition in the unconstrained case.
The method of Lagrange multipliers basically associates a function to the problem in $(2.12)$ such that the first-order condition for unconstrained optimization for that function coincides with (2.14). The method of Lagrange multiplier consists of the following steps.
金融代写|风险理论投资组合代写Market Risk, Measures and Portfolio 代考|Convex Programming
The general form of convex programming problems is the following:
$$
\begin{array}{rl}
\min {x} & f(x) \ \text { subject to } & g{i}(x) \leq 0, \quad i=1, \ldots, m \
& h_{j}(x)=0, \quad j=1, \ldots, k,
\end{array}
$$
where:
$f(x)$ is a convex objective function.
$g_{1}(x), \ldots, g_{m}(x)$ are convex functions defining the inequality constraints. $h_{1}(x), \ldots, h_{k}(x)$ are affine functions defining the equality constraints.
Generally, without the assumptions of convexity, problem $(2.17)$ is more involved than $(2.12)$ because besides the equality constraints, there are inequality constraints. The KKT condition, generalizing the method of Lagrange multipliers, is only a necessary condition for optimality in this case. However, adding the assumption of convexity makes the KKT condition necessary and sufficient.
Note that, similar to problem (2.12), the fact that the right-hand side of all constraints is zero is nonrestrictive. The limits can be arbitrary real numbers.
Consider the following two-dimensional optimization problem;
$$
\begin{aligned}
\min {\substack{x \in \mathbb{R}^{2}}} & \frac{1}{2} x^{\prime} \mathrm{C} x \ \text { subject to } &\left(x{1}+2\right)^{2}+\left(x_{2}+2\right)^{2} \leq 3
\end{aligned}
$$
in which
$$
C=\left(\begin{array}{cc}
1 & 0.4 \
0.4 & 1
\end{array}\right) \text {. }
$$
The objective function is a two-dimensional convex quadratic function and the function in the constraint set is also a convex quadratic function. In fact, the boundary of the feasible set is a circle with a radius of $\sqrt{3}$ centered at the point with coordinates $(-2,-2)$. The top plot in Figure $2.8$ shows the surface of the objective function and the set of feasible points. The shaded part on the surface indicates the function values of all feasible points. In fact, solving problem (2.18) reduces to finding the lowest point on the shaded part of the surface. The bottom plot shows the contour lines of the objective function together with the feasible set that is in gray. Geometrically, the point in the feasible set yielding the minimum of the objective function is positioned where a contour line only touches the constraint set. The position of this point is marked with a black dot and the tangential contour line is given in bold.
Note that the solution points of problems of the type $(2.18)$ can happen to be not on the boundary of the feasible set but in the interior. For example, suppose that the radius of the circle defining the boundary of the feasible set in $(2.18)$ is a larger number such that the point $(0,0)$ is inside the feasible
set. Then, the point $(0,0)$ is the solution to problem $(2.18)$ because at this point the objective function attains its global minimum.
In the two-dimensional case, when we can visualize the optimization problem, geometric reasoning guides us to finding the optimal solution point. In a higher dimensional space, plots cannot be produced and we rely on the analytic method behind the KKT conditions.
风险理论投资组合代写
金融代写|风险理论投资组合代写Market Risk, Measures and Portfolio 代考|CONSTRAINED OPTIMIZATION
在构建解决实际问题的优化问题时,通常需要施加某些约束以使最优解具有实际意义。例如,只做多的投资组合优化问题要求代表优化中变量的投资组合权重应该是非负的,并且应该总和为 1。根据本章中的符号,这对应于类型的问题,
分钟XF(X) 受制于 X′和=1 X≥0,在哪里:F(X)是目标函数。和∈Rn是一个向量,和=(1,…,1). X′和等于所有组件的总和X,X′和=∑一世nX一世.
X≥0表示向量的所有分量X∈Rn是非负的。
在问题 (2.10) 中,我们通过改变来寻找目标函数的最小值X仅在集合中
\mathbf{X}=\left{x \in \mathbb{R}^{n}: \begin{array}{l} x^{\prime} e=1 \ x \geq 0 \end{array}\对}\mathbf{X}=\left{x \in \mathbb{R}^{n}: \begin{array}{l} x^{\prime} e=1 \ x \geq 0 \end{array}\对}
也称为可行点集或约束集。有时会使用更紧凑的符号,类似于无约束问题中的符号,
分钟X∈XF(X)
在哪里X在方程(2.11)中定义。
我们根据目标函数和约束集的假设属性来区分不同类型的优化问题。如果约束集仅包含等式,则问题更易于分析处理。在这种情况下,应用拉格朗日乘子法。对于更一般的约束集,当它们形成时
通过等式和不等式,拉格朗日乘子法由 Karush-Kuhn-Tucker 条件(KKT 条件)推广。就像我们在无约束优化问题中考虑的一阶条件一样,如果没有进一步的假设,这两种方法都不会导致约束优化问题的充分必要条件。KKT 条件是必要和充分的最一般框架之一是凸规划。如果目标函数是一个凸函数并且可行点集是一个凸集,那么我们就有一个凸规划问题。作为凸优化的重要子案例,考虑了线性规划和凸二次规划问题。
在本节中,我们首先描述拉格朗日乘子方法,该方法通常应用于特殊类型的均值方差优化问题以获得封闭形式的解。然后我们继续进行凸规划,这是奖励风险分析的框架。第 8、9 和 10 章介绍了约束优化问题的上述应用。
金融代写|风险理论投资组合代写Market Risk, Measures and Portfolio 代考|Lagrange Multipliers
考虑以下优化问题,其中可行点集由多个等式约束定义,
分钟XF(X) 受制于 b1(X)=0 b2(X)=0 ⋯ bķ(X)=0
功能H一世(X),一世=1,…,ķ建立约束集。请注意,即使等式约束的右侧在方程中给出的问题的经典公式中为零(2.12), 这不是限制性的。如果在实际问题中右侧恰好不为零,则可以对其进行等价变换,例如,
\left{x \in \mathbb{R}^{n}: v(x)=c\right} \quad \Longleftrightarrow \quad\left{x \in \mathbb{R}^{n}: h_{1 }(x)=v(x)-c=0\right} 。\left{x \in \mathbb{R}^{n}: v(x)=c\right} \quad \Longleftrightarrow \quad\left{x \in \mathbb{R}^{n}: h_{1 }(x)=v(x)-c=0\right} 。
为了说明对 (2.12) 有效的最优性的必要条件,让我们考虑以下二维示例:
分钟X∈R212X′CX 受制于 X′和=1,
矩阵在哪里
C=(10.4 0.41).
目标函数是二次函数,约束集包含一个线性等式。在第 8 章中,我们看到允许空头头寸的均值方差优化问题与(2.13)非常相似。目标函数的表面和约束显示在图 2.7 的顶部图上。表面上的黑线表示可行点的函数值。在几何上,解决问题 (2.13) 简化为找到曲面上黑色曲线的最低点。图中底部图上显示的等高线2.7暗示产生目标函数最小值的可行点是轮廓线与由等式约束定义的线相切的地方。在图上,切线等高线和可行点以粗体显示。黑点表示目标函数在约束条件下达到其最小值的点的位置。
尽管该示例在约束集包含一个线性而不是非线性等式的意义上不是一般的,但相同的几何直觉适用于非线性情况。在等高线与由数学语言中的非线性等式约束定义的曲线相切时,达到最小值的事实用以下方式表示: 目标函数在产生最小值的点处的梯度与线性组合成比例定义约束集的函数的梯度。正式地,这被表述为
∇F(X0)−μ1∇H1(X0)−⋯−μķ∇Hķ(X0)=0.
在哪里μ一世,一世=1,…,ķ是一些实数,称为拉格朗日乘数和点X0是这样的F(X0)≤F(X)对全部X这是可行的。请注意,如果问题中没有约束,则 (2.14) 简化为我们在无约束优化中考虑的一阶条件。因此,(2.14) 后面的方程组可以看作是无约束情况下一阶条件的推广。
拉格朗日乘子法基本上将函数与问题相关联(2.12)使得该函数的无约束优化的一阶条件与 (2.14) 一致。拉格朗日乘子法由以下步骤组成。
金融代写|风险理论投资组合代写Market Risk, Measures and Portfolio 代考|Convex Programming
凸规划问题的一般形式如下:
分钟XF(X) 受制于 G一世(X)≤0,一世=1,…,米 Hj(X)=0,j=1,…,ķ,
在哪里:
F(X)是一个凸目标函数。
G1(X),…,G米(X)是定义不等式约束的凸函数。H1(X),…,Hķ(X)是定义等式约束的仿射函数。
一般来说,在没有凸性假设的情况下,问题(2.17)比(2.12)因为除了等式约束,还有不等式约束。KKT 条件是拉格朗日乘子法的推广,在这种情况下只是最优性的必要条件。然而,添加凸性假设使得 KKT 条件是必要且充分的。
请注意,与问题 (2.12) 类似,所有约束的右侧为零的事实是非限制性的。限制可以是任意实数。
考虑以下二维优化问题;
分钟X∈R212X′CX 受制于 (X1+2)2+(X2+2)2≤3
其中
C=(10.4 0.41).
目标函数是一个二维凸二次函数,约束集中的函数也是一个凸二次函数。实际上,可行集的边界是一个半径为3以坐标点为中心(−2,−2). 图中的顶部图2.8显示了目标函数的曲面和可行点集。表面阴影部分表示所有可行点的函数值。事实上,解决问题 (2.18) 可以简化为在曲面的阴影部分找到最低点。底部图显示了目标函数的等高线以及灰色的可行集。在几何上,可行集中产生目标函数最小值的点位于轮廓线仅接触约束集的位置。该点的位置用黑点标记,切线轮廓线用粗体表示。
注意类型问题的解点(2.18)可能恰好不在可行集的边界上,而是在内部。例如,假设定义可行集边界的圆的半径为(2.18)是一个更大的数,使得该点(0,0)在可行范围内
放。那么,重点(0,0)是解决问题的方法(2.18)因为此时目标函数达到其全局最小值。
在二维情况下,当我们可以可视化优化问题时,几何推理会引导我们找到最优解点。在更高维度的空间中,无法生成图,我们依赖于 KKT 条件背后的分析方法。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。