统计代写|数据可视化代写Data visualization代考|STAT1100
如果你也在 怎样代写数据可视化Data visualization这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
数据可视化是将信息转化为视觉背景的做法,如地图或图表,使数据更容易被人脑理解并从中获得洞察力。数据可视化的主要目标是使其更容易在大型数据集中识别模式、趋势和异常值。
statistics-lab™ 为您的留学生涯保驾护航 在代写数据可视化Data visualization方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写数据可视化Data visualization代写方面经验极为丰富,各种代写数据可视化Data visualization相关的作业也就用不着说。
我们提供的数据可视化Data visualization及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|数据可视化代写Data visualization代考|The Transcendent Effect of Water
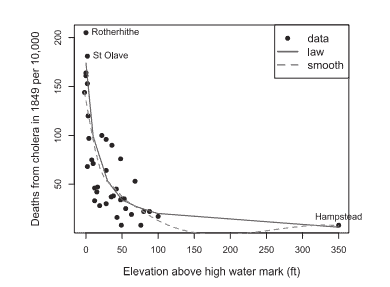
Farr was certainly meticulous in evaluating the impact of potential causes on mortality from cholera. But he lacked an effective method for doing so, even for one potential cause, and the idea of accounting for the combination of several causes stretched him to the limit. His general method was to prepare tables of cholera mortality in the districts of London, broken down and averaged over classes of a possible explanatory variable.
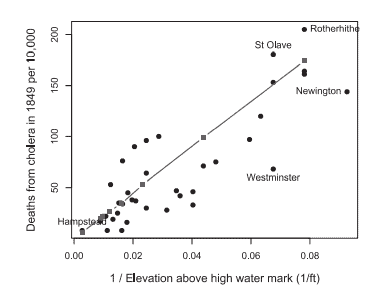
For example, Farr divided the 38 districts into the 19 highest and 19 lowest values on other variables and calculated the ratio of cholera mortality for each; elevation had the largest ratio (3:1), while all other variables showed smaller ratios (e.g., 2.1:1 for house values). Having hit on elevation above the Thames as his principal cause, he prepared many other tables showing mortality by districts also in relation to density of the population, value of houses and shops, relief to the poor, and geographical features.
Figure $4.5$ illustrates the depth of this inquiry, in an ingenious semigraphic combination of small tables for each district overlaid on a schematic map of their spatial arrangement along the Thames. The tables show the numbers for elevation, cholera deaths, deaths from all causes, and population density, and identify the water companies supplying each district. Unfortunately, this lovely diagram concealed more than it revealed: the signal was there, but the wealth of detail provided too much noise.
It would later turn out that the direct cause of cholera could be traced to contamination of the water supply from which people drew. It was probably confusing that water was provided by nine water companies, as Farr shows in Figure 4.5, so he divided the registration districts into three groups based on the region along the Thames for their water supply: Thames, between Kew and Hammersmith bridges (western London), between Battersea and Waterloo bridges (central London), and districts that obtained their water from tributaries of the Thames (New River, Lea River, and Ravensbourne River).
统计代写|数据可视化代写Data visualization代考|John Snow on Cholera
Another terrible wave of cholera struck London toward the end of summer 1854, concentrated in the parish of St. James, Westminster (the present-day district of Soho). This time, a correct explanation of the cause would eventually be found with the aid of meticulous data collection, a map of disease incidence, keen medical detective work, and logical reasoning to rule out alternative explanations. It is useful to understand why John Snow succeeded while William Farr did not.
The physician John Snow [1813-1858] lived in the Soho district at the time of this new outbreak. He had been an eighteen-year-old medical assistant in Newcastle upon Tyne in 1831 when cholera first struck there with great loss of life. At the time of the second great epidemic, in 1848-1849, Snow observed the severity of the disease in his district. In 1849, in a two-part paper in the Medical Gazette and Times ${ }^{11}$ and a longer monograph ${ }^{12}$ he proposed that cholera was transmitted by water rather than through the air and passed from person to person through the intestinal discharges of the sick, either transmitted directly or entering the water supply.
Snow’s reasoning was entirely that of a clinician based on the form of pathology of the disease, rather than that of a statistician seeking associations with potential causal factors. Had cholera been an airborne disease, one would expect to see its effects in the lungs and then perhaps spread to others by respiratory discharge. But the disease clearly acted mainly in the gut, causing vomiting, intense diarrhea, and the massive dehydration that led to death. Whatever causal agent was responsible, it must have been something ingested rather than something inhaled.
William Farr was well aware of Snow’s theory when he wrote his 1852 report. ${ }^{13} \mathrm{He}$ described it quite politely but rejected Snow’s theory of the pathology of cholera. He could not understand any mechanism whereby something ingested by one individual could be passed to a larger community. To Farr, who was then considered the foremost authority on the outbreak and contagion of cholera, Snow’s contention of a single causal agent (some unknown poisonous matter, materies morbi) and a limited vector of transmission (water) was too circumscribed, too restrictive. Snow presented his argument and the evidence to support it as if ingestion and waterborne transmission could be the only causes; he also lacked the crucial data, either from a natural experiment or from direct knowledge of the water that cholera victims drank.
数据可视化代考
统计代写|数据可视化代写Data visualization代考|The Transcendent Effect of Water
法尔在评估潜在原因对霍乱死亡率的影响方面无疑是一丝不苟的。但是他缺乏有效的方法来做到这一点,即使是针对一个潜在的原因,而考虑多种原因的组合的想法使他走到了极限。他的一般方法是准备伦敦各地区的霍乱死亡率表,对可能的解释变量进行分类和平均。
例如,Farr 将 38 个地区划分为其他变量的 19 个最高值和 19 个最低值,并计算了每个地区的霍乱死亡率;海拔的比例最大(3:1),而所有其他变量的比例都较小(例如,房屋价值为 2.1:1)。将泰晤士河以上的海拔作为他的主要原因后,他准备了许多其他表格,显示各地区的死亡率,这些表格还与人口密度、房屋和商店的价值、对穷人的救济以及地理特征有关。
数字4.5展示了这项调查的深度,在每个地区的小桌子的巧妙半图形组合中,覆盖在泰晤士河沿岸空间布置的示意图上。这些表格显示了海拔、霍乱死亡人数、各种原因造成的死亡人数和人口密度,并确定了为每个地区供水的供水公司。不幸的是,这个可爱的图表隐藏的比它揭示的要多:信号在那里,但丰富的细节提供了太多的噪音。
后来发现,霍乱的直接原因可以追溯到人们取水的供水受到污染。正如法尔在图 4.5 中显示的那样,供水由九家供水公司提供可能令人困惑,因此他根据泰晤士河沿岸的供水地区将登记区分为三组:泰晤士河,在 Kew 和 Hammersmith 桥之间(西部伦敦),在巴特西和滑铁卢桥(伦敦市中心)之间,以及从泰晤士河支流(新河、利亚河和拉文斯伯恩河)取水的地区。
统计代写|数据可视化代写Data visualization代考|John Snow on Cholera
1854 年夏末,另一波可怕的霍乱袭击了伦敦,集中在威斯敏斯特的圣詹姆斯教区(现在的苏活区)。这一次,在细致的数据收集、疾病发病率地图、敏锐的医学侦探工作以及排除其他解释的逻辑推理的帮助下,最终将找到对原因的正确解释。理解为什么约翰·斯诺成功而威廉·法尔没有成功是很有用的。
在这次新的疫情爆发时,医生约翰·斯诺 [1813-1858] 住在苏荷区。1831 年,当霍乱首次袭击泰恩河畔纽卡斯尔时,他还是一名 18 岁的医疗助理,造成了巨大的生命损失。在 1848-1849 年第二次大流行病爆发时,斯诺观察了他所在地区疾病的严重程度。1849 年,在《医学公报》和《泰晤士报》的两篇论文中11和更长的专着12他提出,霍乱是通过水而不是空气传播的,并通过病人的肠道排泄物在人与人之间传播,要么直接传播,要么进入供水系统。
斯诺的推理完全是基于疾病病理学形式的临床医生的推理,而不是寻求与潜在因果因素关联的统计学家的推理。如果霍乱是一种空气传播的疾病,人们会期望看到它对肺部的影响,然后可能会通过呼吸道排出物传播给其他人。但这种疾病显然主要作用于肠道,导致呕吐、剧烈腹泻和导致死亡的大量脱水。无论病因是什么,它一定是被摄入的东西而不是被吸入的东西。
威廉·法尔 (William Farr) 在撰写 1852 年的报告时非常了解斯诺的理论。13H和描述得很客气,但拒绝了斯诺关于霍乱病理学的理论。他无法理解任何一种机制,可以将一个人摄入的东西传递给更大的社区。对于当时被认为是霍乱爆发和传染的最高权威的法尔来说,斯诺关于单一病原体(一些未知的有毒物质,即 morbi)和有限的传播媒介(水)的论点过于局限,过于严格。斯诺提出了他的论点和支持它的证据,好像摄入和水传播可能是唯一的原因;他还缺乏来自自然实验或直接了解霍乱受害者饮用的水的关键数据。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。