如果你也在 怎样代写机器学习machine learning这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
机器学习是对计算机算法的研究,这些算法可以通过经验和使用数据来自动改进。机器学习算法基于样本数据(称为训练数据)建立模型,以便在没有明确编程的情况下做出预测或决定。机器学习算法被广泛用于各种应用中,如医学、电子邮件过滤、语音识别和计算机视觉,在这些应用中,开发传统算法来执行所需的任务是困难的或不可行的。
statistics-lab™ 为您的留学生涯保驾护航 在代写机器学习machine learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写机器学习machine learning代写方面经验极为丰富,各种代写机器学习machine learning相关的作业也就用不着说。
我们提供的机器学习machine learning及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|机器学习代写machine learning代考|The Learning Problem and Inference
This chapter introduces the general problem of machine learning and how it relates to statistical inference. It gives a short, example-based overview about supervised, unsupervised and reinforcement learning. The discussion of how to design a learning system for the problem of handwritten digit recognition shows that kernel classifiers offer some great advantages for practical machine learning. Not only are they fast and simple to implement, but they are also closely related to one of the most simple but effective classification algorithms – the nearest neighbor classifier. Finally, the chapter discusses which theoretical questions are of particular, and practical, importance.
It was only a few years after the introduction of the first computer that one of man’s greatest dreams seemed to be realizable-artificial intelligence. It was envisaged that machines would perform intelligent tasks such as vision, recognition and automatic data analysis. One of the first steps toward intelligent machines is machine learning.
The learning problem can be described as finding a general rule that explains data given only a sample of limited size. The difficulty of this task is best compared to the problem of children learning to speak and see from the continuous flow of sounds and pictures emerging in everyday life. Bearing in mind that in the early days the most powerful computers had much less computational power than a cell phone today, it comes as no surprise that much theoretical research on the potential of machines’ capabilities to learn took place at this time. One of the most influential works was the textbook by Minsky and Papert (1969) in which they investigate whether or not it is realistic to expect machines to learn complex tasks. They found that simple, biologically motivated learning systems called perceptrons were incapable of learning an arbitrarily complex problem. This negative result virtually stopped active research in the field for the next ten years. Almost twenty years later, the work by Rumelhart et al. (1986) reignited interest in the problem of machine learning. The paper presented an efficient, locally optimal learning algorithm for the class of neural networks, a direct generalization of perceptrons. Since then, an enormous number of papers and books have been published about extensions and empirically successful applications of neural networks. Among them, the most notable modification is the so-called support vector machine-a learning algorithm for perceptrons that is motivated by theoretical results from statistical learning theory. The introduction of this algorithm by Vapnik and coworkers (see Vapnik (1995) and Cortes (1995)) led many researchers to focus on learning theory and its potential for the design of new learning algorithms.
统计代写|机器学习代写machine learning代考|Supervised Learning
In the problem of supervised learning we are given a sample of input-output pairs (also called the training sample), and the task is to find a deterministic function that maps any input to an output such that disagreement with future input-output observations is minimized. Clearly, whenever asked for the target value of an object present in the training sample, it is possible to return the value that appeared the highest number of times together with this object in the training sample. However, generalizing to new objects not present in the training sample is difficult. Depending on the type of the outputs, classification learning, preference learning and function learning are distinguished.
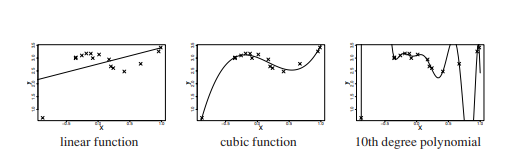
If the output space has no structure except whether two elements of the output space are equal or not, this is called the problem of classification learning. Each element of the output space is called a class. This problem emerges in virtually any pattern recognition task. For example, the classification of images to the classes “image depicts the digit $x$ ” where $x$ ranges from “zero” to “nine” or the classification of image elements (pixels) into the classes “pixel is a part of a cancer tissue” are standard benchmark problems for classification learning algorithms (see also Figure 1.1). Of particular importance is the problem of binary classification, i.e., the output space contains only two elements, one of which is understood as the positive class and the other as the negative class. Although conceptually very simple, the binary setting can be extended to multiclass classification by considering a series of binary classifications.
统计代写|机器学习代写machine learning代考|Unsupervised Learning
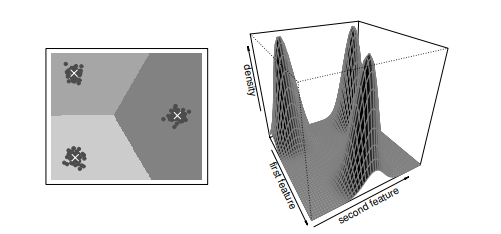
In addition to supervised learning there exists the task of unsupervised learning. In unsupervised learning we are given a training sample of objects, for example images or pixels, with the aim of extracting some “structure” from them-e.g., identifying indoor or outdoor images, or differentiating between face and background pixels. This is a very vague statement of the problem that should be rephrased better as learning a concise representation of the data. This is justified by the following reasoning: If some structure exists in the training objects, it is possible to take advantage of this redundancy and find a short description of the data. One of the most general ways to represent data is to specify a similarity between any pairs of objects. If two objects share much structure, it should be possible to reproduce the data from the same “prototype”. This idea underlies clustering algorithms: Given a fixed number of clusters, we aim to find a grouping of the objects such that similar objects belong to the same cluster. We view all objects within one cluster as being similar to each other. If it is possible to find a clustering such that the similarities of the objects in one cluster are much greater than the similarities among objects from different clusters, we have extracted structure from the training sample insofar as that the whole cluster can be represented by one representative. From a statistical point of view, the idea of finding a concise representation of the data is closely related to the idea of mixture models, where the overlap of high-density regions of the individual mixture components is as small as possible (see Figure 1.4). Since we do not observe the mixture component that generated a particular training object, we have to treat the assignment of training examples to the mixture components as hidden variables-a fact that makes estimation of the unknown probability measure quite intricate. Most of the estimation procedures used in practice fall into the realm of expectation-maximization (EM) algorithms (Dempster et al. 1977).
机器学习代写
统计代写|机器学习代写machine learning代考|The Learning Problem and Inference
本章介绍了机器学习的一般问题以及它与统计推断的关系。它提供了关于监督、无监督和强化学习的简短、基于示例的概述。关于如何设计手写数字识别问题的学习系统的讨论表明,核分类器为实际机器学习提供了一些巨大的优势。它们不仅实现起来快速简单,而且还与最简单但有效的分类算法之一——最近邻分类器密切相关。最后,本章讨论了哪些理论问题具有特殊的和实际的重要性。
仅仅在第一台计算机问世几年后,人类最伟大的梦想之一似乎就是可实现的——人工智能。设想机器将执行智能任务,例如视觉、识别和自动数据分析。迈向智能机器的第一步是机器学习。
学习问题可以描述为找到一个通用规则,该规则仅在给定有限样本的情况下解释数据。这项任务的难度最好与儿童从日常生活中不断出现的声音和图片学习说话和看东西的问题相比。请记住,在早期,最强大的计算机的计算能力比今天的手机要低得多,因此在这个时候对机器学习能力的潜力进行了大量理论研究也就不足为奇了。最有影响力的作品之一是 Minsky 和 Papert (1969) 的教科书,他们在其中调查了期望机器学习复杂任务是否现实。他们发现很简单,被称为感知器的生物驱动学习系统无法学习任意复杂的问题。这一负面结果实际上停止了该领域未来十年的积极研究。差不多二十年后,Rumelhart 等人的工作。(1986) 重新点燃了对机器学习问题的兴趣。该论文提出了一种高效的、局部最优的神经网络类学习算法,是感知器的直接推广。从那时起,已经发表了大量关于神经网络扩展和经验上成功应用的论文和书籍。其中,最显着的修改是所谓的支持向量机——一种由统计学习理论的理论结果驱动的感知器学习算法。
统计代写|机器学习代写machine learning代考|Supervised Learning
在监督学习问题中,我们给定一个输入-输出对的样本(也称为训练样本),任务是找到一个确定性函数,将任何输入映射到输出,使得与未来输入-输出观察的不一致是最小化。显然,无论何时询问训练样本中存在的对象的目标值,都可以返回与该对象一起在训练样本中出现次数最多的值。然而,推广到训练样本中不存在的新对象是困难的。根据输出的类型,可以区分分类学习、偏好学习和功能学习。
如果输出空间除了输出空间的两个元素是否相等之外没有结构,这称为分类学习问题。输出空间的每个元素称为一个类。这个问题几乎出现在任何模式识别任务中。例如,将图像分类到“图像描绘数字”类X“ 在哪里X从“零”到“九”的范围或将图像元素(像素)分类到“像素是癌组织的一部分”的类别是分类学习算法的标准基准问题(另请参见图 1.1)。特别重要的是二分类问题,即输出空间只包含两个元素,一个被理解为正类,另一个被理解为负类。虽然概念上非常简单,但可以通过考虑一系列二进制分类将二进制设置扩展到多类分类。
统计代写|机器学习代写machine learning代考|Unsupervised Learning
除了监督学习之外,还有无监督学习的任务。在无监督学习中,我们得到一个对象的训练样本,例如图像或像素,目的是从中提取一些“结构”,例如识别室内或室外图像,或区分面部和背景像素。这是对问题的一个非常模糊的陈述,应该更好地改写为学习数据的简洁表示。这是由以下推理证明的:如果训练对象中存在某种结构,则可以利用这种冗余并找到数据的简短描述。表示数据的最通用方法之一是指定任何对象对之间的相似性。如果两个对象共享很多结构,应该可以从相同的“原型”复制数据。这个想法是聚类算法的基础:给定固定数量的聚类,我们的目标是找到一组对象,使得相似的对象属于同一个聚类。我们将一个集群中的所有对象视为彼此相似。如果有可能找到一个聚类,使得一个聚类中的对象的相似性远大于不同聚类中的对象之间的相似性,我们从训练样本中提取结构,只要整个聚类可以由一个代表表示. 从统计的角度来看,找到数据的简洁表示的想法与混合模型的想法密切相关,其中各个混合成分的高密度区域的重叠尽可能小(见图 1.4)。由于我们没有观察到生成特定训练对象的混合分量,因此我们必须将训练示例分配给混合分量视为隐藏变量——这一事实使得未知概率测度的估计非常复杂。实践中使用的大多数估计程序都属于期望最大化(EM)算法(Dempster et al. 1977)。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。