计算机代写|机器学习代写machine learning代考|COMP4318
如果你也在 怎样代写机器学习Machine Learning 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning令人兴奋。这是有趣的,具有挑战性的,创造性的,和智力刺激。它还为公司赚钱,自主处理大量任务,并从那些宁愿做其他事情的人那里消除单调工作的繁重任务。
机器学习Machine Learning也非常复杂。从数千种算法、数百种开放源码包,以及需要具备从数据工程(DE)到高级统计分析和可视化等各种技能的专业实践者,ML专业实践者所需的工作确实令人生畏。增加这种复杂性的是,需要能够与广泛的专家、主题专家(sme)和业务单元组进行跨功能工作——就正在解决的问题的性质和ml支持的解决方案的输出进行沟通和协作。
statistics-lab™ 为您的留学生涯保驾护航 在代写机器学习 machine learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写机器学习 machine learning代写方面经验极为丰富,各种代写机器学习 machine learning相关的作业也就用不着说。
计算机代写|机器学习代写machine learning代考|Bulk external delivery
The considerations for bulk external delivery aren’t substantially different from internal use serving to a database or data warehouse. The only material differences between these serving cases are in the realms of delivery time and monitoring of the predictions.
DELIVERY CONSISTENCY
Bulk delivery of results to an external party has the same relevancy requirements as any other ML solution. Whether you’re building something for an internal team or generating predictions that will be end-user-customer facing, the goal of creating useful predictions doesn’t change.
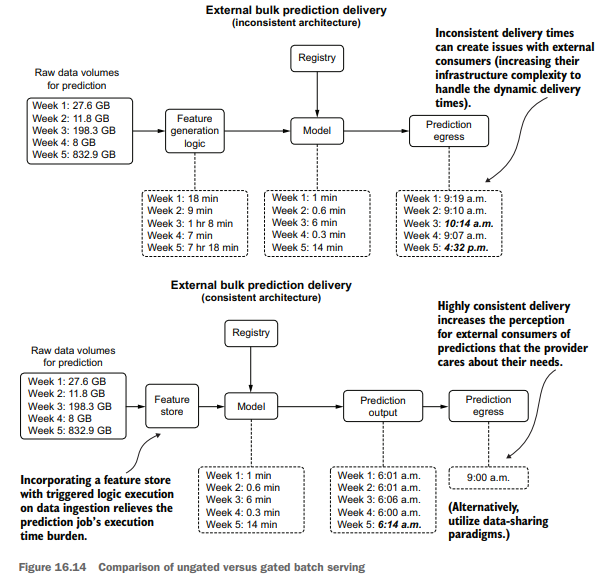
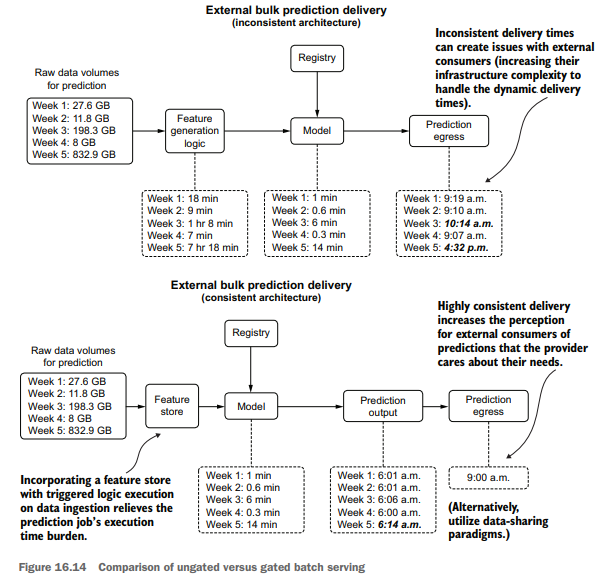
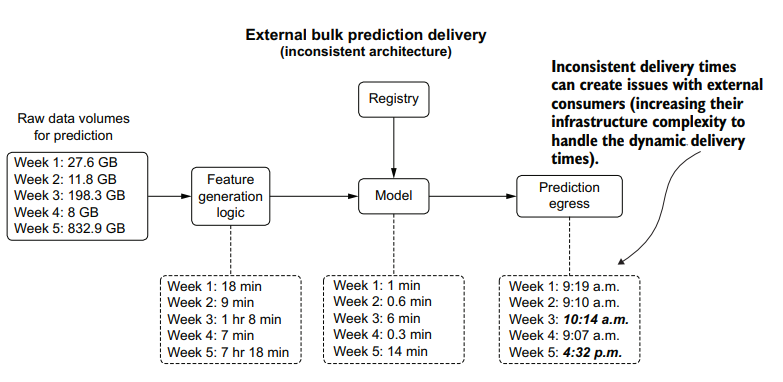
The one thing that does change with providing bulk predictions to an outside organization (generally applicable to business-to-business companies) when compared to other serving paradigms is in the timeliness of the delivery. While it may be obvious that a failure to deliver an extract of bulk predictions entirely is a bad thing, an inconsistent delivery can be just as detrimental. There is a simple solution to this, however, illustrated in the bottom portion of figure 16.14.
Figure 16.14 shows the comparison of gated and ungated serving to an external user group. By controlling a final-stage egress from the stored predictions in a scheduled batch prediction job, as well as coupling feature-generation logic to an ETL process governed by a feature store, delivery consistency from a chronological perspective can be guaranteed. While this may not seem an important consideration from the DS perspective of the team generating the predictions, having a predictable dataavailability schedule can dramatically increase the perceived professionalism of the serving company.
计算机代写|机器学习代写machine learning代考|QUALITY ASSURANCE
An occasionally overlooked aspect of serving bulk predictions externally (external to the DS and analytics groups at a company) is ensuring that a thorough quality check is performed on those predictions.
An internal project may rely on a simple check for overt prediction failures (for example, silent failures are ignored that result in null values, or a linear model predicts infinity). When sending data products externally, additional steps should be done to minimize the chances of end users of predictions finding fault with them. Since we, as humans, are so adept at finding abnormalities in patterns, a few scant issues in a batch-delivered prediction dataset can easily draw the focus of a consumer of the data, deteriorating their faith in the efficacy of the solution to the point of disuse.
In my experience, when delivering bulk predictions external to a team of data specialists, I’ve found it worthwhile to perform a few checks before releasing the data:
- Validate the predictions against the training data:
- Classification problems-Comparing aggregated class counts
- Regression problems-Comparing prediction distribution
- Unsupervised problems-Evaluating group membership counts
- Check for prediction outliers (applicable to regression problems).
- Build (if applicable) heuristics rules based on knowledge from SMEs to ensure that predictions are not outside the realm of possibility for the topic.
- Validate incoming features (particularly encoded ones that may use a generic catchall encoding if the encoding key is previously unseen) to ensure that the data is fully compatible with the model as it was trained.
By running a few extra validation steps on the output of a batch prediction, a great deal of confusion and potential lessening of trust in the final product can be avoided in the eyes of end users.
机器学习代考
计算机代写|机器学习代写machine learning代考|Bulk external delivery
批量外部交付的考虑因素与数据库或数据仓库的内部使用没有本质上的区别。这些服务案例之间唯一的实质性区别在于交付时间和预测监控方面。
交付的一致性
将结果批量交付给外部方与任何其他ML解决方案具有相同的相关性要求。无论您是在为内部团队构建某些东西,还是生成面向最终用户-客户的预测,创建有用预测的目标都不会改变。
与其他服务范式相比,向外部组织提供批量预测(通常适用于b2b公司)确实改变了一件事,那就是交付的及时性。虽然很明显,不能完全交付批量预测的摘要是一件坏事,但不一致的交付可能同样有害。但是,有一个简单的解决方案,如图16.14的底部部分所示。
图16.14显示了为外部用户组服务的门控和不门控的比较。通过控制计划批处理预测作业中存储的预测的最后阶段出口,以及将特征生成逻辑耦合到由特征存储管理的ETL过程,可以保证从时间顺序角度来看交付的一致性。虽然从生成预测的团队的DS角度来看,这似乎不是一个重要的考虑因素,但拥有可预测的数据可用性时间表可以显著提高服务公司的专业水平。
计算机代写|机器学习代写machine learning代考|QUALITY ASSURANCE
在向外部(公司的DS和分析组外部)提供批量预测时,一个偶尔被忽视的方面是确保对这些预测执行彻底的质量检查。
内部项目可能依赖于对公开预测失败的简单检查(例如,忽略导致空值的静默失败,或者线性模型预测无穷大)。在向外部发送数据产品时,应该采取额外的步骤,以尽量减少预测的最终用户发现错误的可能性。作为人类,我们非常善于发现模式中的异常,因此批量交付的预测数据集中的一些小问题很容易吸引数据消费者的注意力,从而降低他们对解决方案有效性的信心,直至不再使用。
根据我的经验,当向数据专家团队外部交付批量预测时,我发现在发布数据之前执行一些检查是值得的:
根据训练数据验证预测:
分类问题——比较聚合类计数
回归问题-比较预测分布
不受监督的问题——评估团队成员数量
检查预测异常值(适用于回归问题)。
基于中小企业的知识构建启发式规则(如果适用),以确保预测不会超出主题的可能性范围。
验证传入的特性(特别是编码的特性,如果编码键以前未见过,则可能使用通用的通用编码),以确保数据在训练时与模型完全兼容。
通过在批预测的输出上运行一些额外的验证步骤,可以避免在最终用户眼中对最终产品的大量混淆和潜在的信任度降低。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。