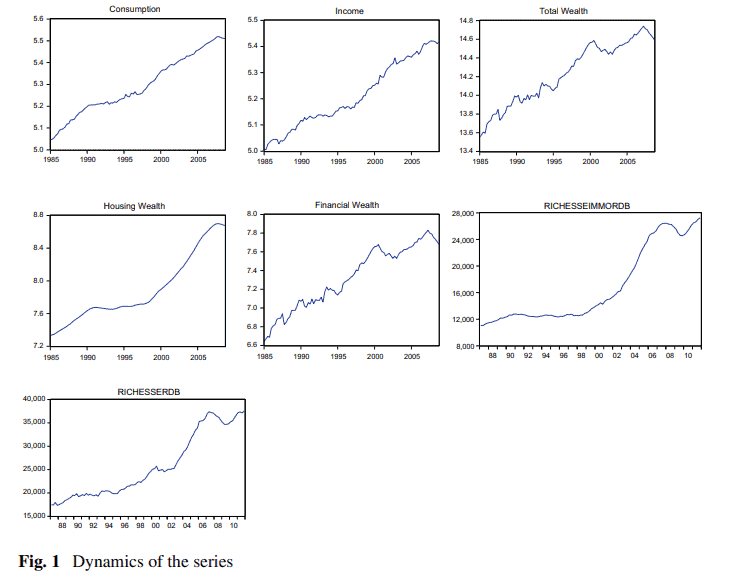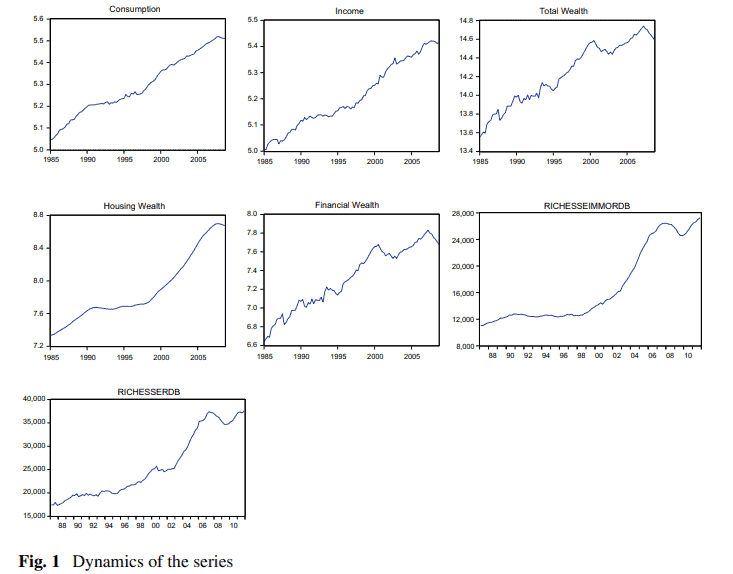
经济代写|计量经济学代写Econometrics代考|Domestic and Global Productivity
如果你也在 怎样代写金融计量经济学Financial Econometrics 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。金融计量经济学Financial Econometrics是使用统计方法来发展理论或检验经济学或金融学的现有假设。计量经济学依靠的是回归模型和无效假设检验等技术。计量经济学也可用于尝试预测未来的经济或金融趋势。
金融计量经济学Financial Econometrics的一个基本工具是多元线性回归模型。计量经济学理论使用统计理论和数理统计来评估和发展计量经济学方法。计量经济学家试图找到具有理想统计特性的估计器,包括无偏性、效率和一致性。应用计量经济学使用理论计量经济学和现实世界的数据来评估经济理论,开发计量经济学模型,分析经济历史和预测。
statistics-lab™ 为您的留学生涯保驾护航 在代写计量经济学Econometrics方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写计量经济学Econometrics代写方面经验极为丰富,各种代写计量经济学Econometrics相关的作业也就用不着说。
经济代写|计量经济学代写Econometrics代考|Domestic and Global Productivity
In this section, we apply the Glick-Rogoff model to the fast-growing emerging economies, namely the BRICS countries, Brazil, China, India, Russia, and South Africa. The key determinants of current account change in the Glick-Rogoff model are global and country-specific productivity shocks. To account for the severe negative shocks experienced during the global financial crisis, we estimate the model in two sample periods; one ending in 2008 and the other ending in 2017. In the second subsection, we also apply the extended model with additional macroeconomic variables after we obtain the base results from the original Glick-Rogoff model. In next section, we apply the same model to developed countries, namely Canada, France, Germany, Italy, Japan, the UK, and the USA. We discuss similarities and differences in current account determinants between the BRICS and G7 countries.
Estimation Results of the Basic Glick–Rogoff Model
Global productivity is constructed from the weighted average of the productivities of the G7 countries, namely Canada, France, Germany, Italy, Japan, the UK, and the USA. Alternatively, the first principal component of the productivities of the G7 countries is also used as a measure of global productivity. ${ }^5$ The regression model of Eq. (10) is restated here.
$$
\Delta C A_t=\gamma_1 I_{t-1}+\gamma_2 \Delta A_t^c+\gamma_3 \Delta A_t^W+\varepsilon_t,
$$
From the Glick-Rogoff model, the expected sign of the past investment is positive, that of the first difference of each country’s productivity is negative, and that of the first difference of worldwide productivity is zero; that is, $\gamma_1>0, \gamma_2<0$, and $\gamma_3=$ 0 . The dynamic optimization model of Glick and Rogoff (1995) integrates the endogenous decisions of producers and consumers; therefore, the derived parameters of the model are affected by several sources. However, if we simply decompose the dependent variable, which is the first difference of the current account in terms of private saving and investment, and leave aside the government role, we can observe (in the first equality) the first-degree importance of the current investment and the past investment on the dependent variable. Adjusted for marginal production with respect to investment and capital stock, i.e., $\alpha_I$ and $\alpha_K$, and the impact of past investment shock on the current investment, i.e., $\beta_1$, the coefficient of unity in the equation remains positive, $\gamma_1$, as shown in Eq. (8).
$$
\Delta C A_t \equiv C A_t-C A_{t-1}=\left(S_t-I_t\right)-\left(S_{t-1}-I_{t-1}\right)=\Delta S_t-\Delta I_t
$$
It is also clear that a change in a country’s productivity negatively affects a change in its current account, $\gamma_2$, via a change in investment through the second equality.
经济代写|计量经济学代写Econometrics代考|Extended Models with Other Macroeconomic Variables
Not all empirical models of current account movements emphasize productivity shocks. The advantage of the Glick-Rogoff regression model is its concrete derivation based on the theoretical dynamic model. However, many researchers have continued to explore the possibility of many other macroeconomic variables to explain current account movements, frequently without theoretical models.
Chinn and Prasad (2003) investigated the medium-term determinants of current accounts for a large sample of developed and developing countries. They find that current account balance is positively correlated with government budget balance and the initial level of net foreign assets. Among developing countries, financial deepening is positively associated with current account balance, while trade openness is negatively correlated with current account balance.
Cudre and Hoffmann (2017) and Romelli et al. (2018) also showed that trade openness is a significant driver of current accounts. Romelli et al. (2018) investigated the impact of trade openness on the relationship between the current account and the real exchange rate. They find that during the balance of payment distress episodes, currency depreciations are associated with larger improvements in the current accounts of countries that are more open to trade, and the magnitude of exchange rate depreciations over the adjustment process of current accounts is related to the degree of openness to trade. Cudre and Hoffmann (2017) also find that trade openness is an important factor even across regions within a nation.
Following the recent development of the empirical current account literature, we extended the Glick-Rogoff model with five macroeconomic variables: financial deepening, old dependency ratio, young dependency ratio, net foreign assets, and trade openness. ${ }^8$ First, the fitness of regression substantially improved for Brazil, India, and China. In the shorter sample between 1983 and 2008, the adjusted Rsquared increased from 0.29 to 0.60 for Brazil, from 0.60 to 0.69 for India, and from 0.58 to 0.68 for China. In the longer sample that included the post-crisis period, the adjusted R-squared values were 0.31 for Russia, 0.21 for Brazil, and 0.24 for China; all of these values increased from zero or even negative values of the adjusted R-squared in the basic model estimations.
计量经济学代考
经济代写|计量经济学代写Econometrics代考|Domestic and Global Productivity
在本节中,我们将Glick-Rogoff模型应用于快速增长的新兴经济体,即金砖国家、巴西、中国、印度、俄罗斯和南非。在格利克-罗格夫模型中,决定经常账户变化的关键因素是全球和特定国家的生产率冲击。为了考虑全球金融危机期间经历的严重负面冲击,我们在两个样本期间估计模型;一个是2008年,另一个是2017年。在第二小节中,在获得原始Glick-Rogoff模型的基本结果后,我们还应用了带有额外宏观经济变量的扩展模型。在下一节中,我们将把相同的模型应用于发达国家,即加拿大、法国、德国、意大利、日本、英国和美国。我们讨论了金砖国家和七国集团国家经常账户决定因素的异同。
Glick-Rogoff基本模型的估计结果
全球生产率是由七国集团(G7)(加拿大、法国、德国、意大利、日本、英国和美国)的生产率加权平均值构建而成的。另外,G7国家生产率的第一个主要组成部分也被用作衡量全球生产率的指标。${ }^5$这里重述Eq.(10)的回归模型。
$$
\Delta C A_t=\gamma_1 I_{t-1}+\gamma_2 \Delta A_t^c+\gamma_3 \Delta A_t^W+\varepsilon_t,
$$
从Glick-Rogoff模型看,过去投资的预期符号为正,各国生产率第一次差异的预期符号为负,全球生产率第一次差异的预期符号为零;即$\gamma_1>0, \gamma_2<0$和$\gamma_3=$ 0。Glick和Rogoff(1995)的动态优化模型整合了生产者和消费者的内生决策;因此,模型的导出参数受到多个源的影响。然而,如果我们简单地分解因变量,即经常账户在私人储蓄和投资方面的第一个差异,而不考虑政府的作用,我们可以观察到(在第一个等式中)当前投资和过去投资对因变量的一级重要性。调整了边际产量对投资和资本存量的影响,即$\alpha_I$和$\alpha_K$,以及过去投资冲击对当前投资的影响,即$\beta_1$,方程的统一系数仍然为正,即$\gamma_1$,如式(8)所示。
$$
\Delta C A_t \equiv C A_t-C A_{t-1}=\left(S_t-I_t\right)-\left(S_{t-1}-I_{t-1}\right)=\Delta S_t-\Delta I_t
$$
同样明显的是,一国生产率的变化会通过第二项平等导致投资的变化,从而对其经常账户($\gamma_2$)的变化产生负面影响。
经济代写|计量经济学代写Econometrics代考|Extended Models with Other Macroeconomic Variables
并非所有经常账户变动的实证模型都强调生产率冲击。Glick-Rogoff回归模型的优势在于它在理论动态模型的基础上进行了具体的推导。然而,许多研究人员继续探索许多其他宏观经济变量来解释经常账户变动的可能性,往往没有理论模型。
Chinn和Prasad(2003)调查了大量发达国家和发展中国家经常账户的中期决定因素。他们发现经常项目余额与政府预算余额和初始净外国资产水平呈正相关。在发展中国家,金融深化与经常账户余额正相关,而贸易开放与经常账户余额负相关。
Cudre和Hoffmann(2017)以及Romelli等人(2018)也表明,贸易开放是经常账户的重要驱动因素。Romelli等人(2018)研究了贸易开放对经常账户与实际汇率关系的影响。他们发现,在国际收支困难时期,货币贬值与对贸易更开放的国家经常账户的较大改善有关,而汇率贬值在经常账户调整过程中的幅度与对贸易的开放程度有关。Cudre和Hoffmann(2017)还发现,即使在一个国家的各个地区,贸易开放程度也是一个重要因素。
根据实证经常账户文献的最新发展,我们将Glick-Rogoff模型扩展为五个宏观经济变量:金融深化、老年抚养比、年轻抚养比、净外国资产和贸易开放度。${}^8$首先,巴西、印度和中国的回归适应度显著提高。在1983年至2008年的较短样本中,巴西调整后的Rsquared从0.29增加到0.60,印度从0.60增加到0.69,中国从0.58增加到0.68。在包括危机后时期在内的较长样本中,俄罗斯、巴西和中国的调整后r平方值分别为0.31、0.21和0.24;这些值都是从基本模型估计中调整后的r平方的零甚至负值开始增加的。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。