数学代写|线性规划作业代写Linear Programming代考|Cycling Concept and Anti-Cyclic Rules
数学代写|线性规划作业代写Linear Programming代考|Cycling Concept and Anti-Cyclic Rules
In 2.4.1 Theorem, we have shown that after each iteration of the StandardMax algorithm, the value of the function is either targeted or increased, or it remains the same. In this way, we have “proved” that the same algorithm ends up in a finite number of iterations (since there are finally many basic solutions available). In doing so, we have not considered the possibility of value does not change the function of the target while running the StandardMax algorithm. In this case, we have no guarantee that the algorithm will StandardMax finish in finite time. The following is an example.
数学代写|线性规划作业代写Linear Programming代考|Complexity of Simplex Methods and Minty-Klee Polyhedra
In the introduction, we mentioned that despite the good features he showed in practice, the simplex algorithm is not polynomial. This claim was first proven by Minty and Klee in [28], back in 1970, assuming that for the pivot column, the first column is $\gamma_j<0$. It was later proven to [29] for almost everyone deterministic pivot column selection rule there is a class example of linear programming problems such that the number of iterations the simplex method depends exponentially on the dimension of the problem.
Definition 2.13.1. Let’s look at the following linear programming problem, given in canonical form and via Tucker’s table:
It corresponds to each condition of negativity in vector space $\mathbb{R}^n$ half-space in which the corresponding variable is non-negative. Each conditional equation in $\mathbb{R}^n$ corresponds to one hyper-straight. Each conditional inequality corresponds to the half-space bounded hyperbolic associated with the corresponding equation. A set of all the admissible vectors $y$ is the intersection of all given half-spaces and given hypergraphs, therefore, constitutes a convex polyhedron $\Gamma_P$. The equation $\gamma^T x=k$ for some $k$ is a hyperparallel parallel to space $\mathbb{R}^{n-1}$ which is normal at $\gamma$. Projection of polyhedra $\Gamma_P$ on the direction determined by the vector $\gamma$ is a closed set of $[l, \Lambda]$ real numbers, where $l$ minimum and $\Lambda$ maximum of the objective function (1.5.0. 2). Appropriately hyper straight normal to $\gamma$ are touched by hyper straight polyhedra $\Gamma_P$. The common points of these touching hyperlines with the polyhedron $\Gamma_P$ give values in which the function (1.5.0. 2) reaches an extreme value.
The geometric method can be used for problems containing $n=2$ programming task is given in the basic form it fulfills the condition $n-$ $m=2$ (and the highest $n-m=3$ ) can also be to geometric geometry. The geometric method, while not very basic, is used because easy access to the general algebraic method. Let be given a linear problem in form:
$$ \begin{aligned} & \max \omega(y)=\gamma_1 y_1+\ldots+\gamma_n y_n \ & \text { subj. } \alpha_{11} y_1+\alpha_{12} y_2+\ldots+\alpha_{1 n} y_n \leq \beta_1 \ & \text {…….. } \ & \alpha_{m 1} y_1+\alpha_{m 2} y_2+\ldots+\alpha_{m n} y_n \leq \beta_m . \ & \end{aligned} $$ For a given system we know that every solution of the system is an unequal solution one point space $\mathbb{R}^n$, and a set of nonnegative admissible ones $\Gamma_p$ is a subset of $\mathbb{R}^n$. Each of the unequal acts: $$ \sum_{j=1}^n \alpha_{i j} y_j \leq \beta_i, \beta=1,2, \ldots, m $$ specifies a subset of $D_i \subset \mathbb{R}^n, i=1, \ldots, m$ representing the set of ta aka on the one hand hyper-straight: $$ \sum_{j=1}^n \alpha_{i j} y_j=\beta_i $$
数学代写|线性规划作业代写Linear Programming代考|Properties of Simplex Methods
Note first that the vector $y^*$ in which the objective function $\omega(y)$ reaches extreme value need not be unique. The following theorem shows that the target function reaches an extreme value in some of the extreme points of the set $\Gamma_P$.
Theorem 2.1.1. If $\Gamma_P={y: A y=\beta, y \geq 0}$ limited set $i \omega(y)=$ $\gamma_1 y_1+\cdots+\gamma_n x_n$ given a linear function, then there is a bar one extreme point $y^* \in \Gamma_p$ such that: $$ \inf {y \in \Gamma_P} \omega(y)=\omega\left(y^\right) $$ Set $\left{y \mid y \in \Gamma_P, \omega(y)=\omega\left(y^\right)\right}$ is convex. Proof. Let $y^1, \ldots, y^p$ be the extreme points of the set $\Gamma_P$ and let is $y^$ the extreme point for which $\omega\left(y^i\right) \geq \omega\left(y^\right), i=1, \ldots, p$. How is each $y \in \Gamma_P$ a convex combination of extremes dots, there are positive scalars $\sigma_1, \ldots, \sigma_p$ such that it is: $$ y=\sum{k=1}^p \sigma_k y^k, \quad \sum_{k=1}^p \sigma_k=1 $$ Now we have: $$ \omega(y)=\omega\left(\sum_{k=1}^p \sigma_k y^k\right)=\sum_{k=1}^p \sigma_k \omega\left(y^k\right) \geq \sum_{k=1}^p \sigma_k \omega\left(y^\right)=\omega\left(y^\right), $$ which proves that $\omega$ reaches the minimum in $y^*$.
数学代写|线性规划作业代写Linear Programming代考|Pareto Optimality Test
数学代写|线性规划作业代写Linear Programming代考|Pareto Optimality Test
As a rule, it is impossible to find a complete infinite set of Pareto optimal solutions to special problems from real life. For this reason, the engineering securitization problem of the command seeks to determine a subset of criterion-wise different Pareto optimal solutions finally. Also, there are a number of methods for proving Pareto optimality. These methods can also be used to find the original Pareto optimal solution of [?].
An algorithm for determining the Pareto optimality was introduced in the paper [57] solutions of multiobjective of the problem, using direct proof in accordance with the Pareto definition of the optimal point. Algoritam 1.1 Pareto optimality test of fixed point $x^$. Require: Optimization problem (1.0.1). Arbitrary fixed point $\mathbf{x}^$. 1: Specify the set $X=$ Reduce [constr /. List $\rightarrow$ And, var] and set Optimal $=$ true. 2: For each index $j=1, \ldots, l$ repeat Steps 2.1 and 2.2 : 2.1: Generate the following conjunction constraint $$ \text { Par }=X \& \& u_1(\mathbf{x}) \& \& \ldots \& \& u_l(\mathbf{x}) $$ where $$ u_i(\mathbf{x})=\left{\begin{array}{l} Q_i(\mathbf{x}) \geq Q_i\left(\mathbf{x}^\right), j \neq i, \ Q_i(\mathbf{x})>Q_i\left(\mathbf{x}^\right), j=i . \end{array}\right. $$ 2.2: If $\mathrm{Par}=\emptyset$, set Optimal $:=$ false and to Step 3 . 3: return the value of the variable Optimal as a result.
数学代写|线性规划作业代写Linear Programming代考|The Method of Weight Coefficients
Weight coefficient method is the oldest method used for MOO. According to this method, the weight coefficient $w_i$ is introduced for all criterion functions $Q_i(\operatorname{mathbfx}), i=1$, ldots, $l$, so the problem optimization reduces to the following scalar optimization: $$ \begin{array}{ll} \max & Q(\mathbf{x})=\sum_{i=1}^l w_i Q_i(\mathbf{x}) \ \text { p.o. } & \mathbf{x} \in \mathbf{X}, \end{array} $$ where; $w_i, i=1$, ldots $l$ meet the following conditions: $$ \sum_{i=1}^l w_i=1, \quad w_i \geq 0, i=1, \ldots, l . $$ The method of weight coefficients is often used by setting the values of these coefficients. However, this always causes certain difficulties and objections to this procedure, because the subjective influence on the final solution is entered through the given values of the weight coefficients.
数学代写|线性规划作业代写Linear Programming代考|Pareto Optimality Test
Hypersphere. $A$ hypersphere in $E^n$ with centre at a and radius $\varepsilon>0$ is defined to be the set of points [Meerut 93] $$ X={\mathbf{x}:|\mathbf{x}-\mathbf{a}|=\varepsilon} $$ i.e., the equation of a hypersphere in $E^n$ is $$ \left(x_1-a_1\right)^2+\left(x_2-a_2\right)^2+\ldots+\left(x_n-a_n\right)^2=\varepsilon^2 $$ where $\quad \mathrm{a}=\left(a_1, a_2, \ldots, a_n\right), \mathrm{x}=\left(x_1, x_2, \ldots, x_n\right)$, which represent a circle in $E^2$ and sphere in $E^3$.
An $\varepsilon$-neighbourhood. An e-neighbourhood about the point a is defined as the set of points lying inside the hypersphere with centre is a and radius $\varepsilon>0$. i.e., the $\varepsilon$-neighbourhood about the point a is the set of points $$ X={\mathbf{x}:|\mathbf{x}-\mathbf{a}|<\varepsilon} $$
数学代写|线性规划作业代写Linear Programming代考|Extreme point of a convex set
$A$ point $\mathrm{x}$ in a convex set $C$ is called an extreme point if $\times$ cannot be expressed as a convex combination of any two distinct points $\mathrm{x}_1$ and $x_2$ in $C$. Obviously, an extreme point is a boundary point of the set. It is important to note that all boundary points of a convex set are not necessarily extreme points.
Convex Hull. The convex hull $C(\mathbf{x})$ of any given set of points $X$ is the set of all
convex combinations of sets of points from $X$. Ex. If $X$ is the set of eight vertices of a cube, then the convex hull $C(\mathbf{x})$ is the whole cube.
Convex Function. A function $f(\mathrm{x})$ is said to be strictly convex at $\mathrm{x}$ if for any two other distinct points $x_1$ and $x_2$ $$ f\left{\lambda \mathrm{x}_1+(1-\lambda) \mathrm{x}_2\right}<\lambda f\left(\mathrm{x}_1\right)+(1-\lambda) f\left(\mathrm{x}_2\right) \text {, } $$ where $0<\lambda<1$. On the other hand, a function $f(x)$ is strictly concave if $-f(x)$ is strictly convex.
如果你也在 怎样代写似然估计Probability and Estimation这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
似然估计是一种统计方法,它用来求一个样本集的相关概率密度函数的参数。
statistics-lab™ 为您的留学生涯保驾护航 在代写似然估计Probability and Estimation方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写似然估计Probability and Estimation代写方面经验极为丰富,各种代写似然估计Probability and Estimation相关的作业也就用不着说。
我们提供的似然估计Probability and Estimation及其相关学科的代写,服务范围广, 其中包括但不限于:
Statistical Inference 统计推断
Statistical Computing 统计计算
Advanced Probability Theory 高等楖率论
Advanced Mathematical Statistics 高等数理统计学
(Generalized) Linear Models 广义线性模型
Statistical Machine Learning 统计机器学习
Longitudinal Data Analysis 纵向数据分析
Foundations of Data Science 数据科学基础
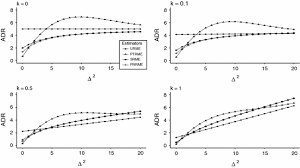
统计代写|似然估计作业代写Probability and Estimation代考|Bias and Weighted L2 Risks of Estimators
统计代写|似然估计作业代写Probability and Estimation代考|Bias and Weighted L2 Risks of Estimators
This section contains the bias and the weighted $\mathrm{L}{2}$-risk expressions of the estimators. We study the comparative performance of the seven estimators defined on the basis of the weighted $L{2}$ risks defined by $$ \begin{aligned} R\left(\theta_{n}^{}: W_{1}, W_{2}\right)=& \mathbb{E}\left[\left(\theta_{1 n}^{}-\theta_{1}\right)^{\top} W_{1}\left(\theta_{1 n}^{}-\theta_{1}\right)\right] \ &+\mathbb{E}\left[\left(\theta_{2 n}^{}-\theta_{2}\right)^{\top} W_{2}\left(\theta_{2 n}^{}-\theta_{2}\right)\right] \end{aligned} $$ where $\theta_{n}^{}=\left(\theta_{1 n}^{}, \theta_{2 n}^{}\right)^{\top}$ is any estimator of $\theta=\left(\theta_{1}^{\top}, \theta_{2}^{\top}\right)^{\top}$, and $W_{1}$ and $W_{2}$ are weight matrices. For convenience, when $W_{1}=I_{p_{1}}$ and $W_{2}=I_{p_{2}}$, we get the mean squared error (MSE) and write $R\left(\theta_{n}^{}: I_{p}\right)=\mathbb{E}\left[\left|\theta_{n}^{}-\theta\right|^{2}\right]$. First, we note that for LSE, $$ \begin{aligned} b\left(\tilde{\theta}{n}\right) &=\mathbf{0} \ R\left(\tilde{\theta}{n}: N_{1}, N_{2}\right) &=\sigma^{2}\left(p_{1}+p_{2}\right) \end{aligned} $$ and for RLSE, $\hat{\theta}{\mathrm{R}}=\left(\tilde{\theta}{1 n}^{\top}, \mathbf{0}^{\top}\right)^{\top}$, we have $$ \begin{aligned} b\left(\hat{\theta}{\mathbb{R}}\right) &=\left(\mathbf{0}^{\top}, \boldsymbol{\theta}{2}^{\top}\right) \ R\left(\hat{\theta}{\mathbb{R}} ; N{1}, N_{2}\right) &=\sigma^{2}\left(p_{1}+\Delta^{2}\right) \end{aligned} $$
统计代写|似然估计作业代写Probability and Estimation代考|Hard Threshold Estimator
The bias of this estimator is given by $$ b\left(\hat{\theta}{n}^{\mathrm{HT}}(\kappa)\right)=\left(-\sigma n{j}^{-\frac{1}{2}} \Delta_{j} H_{3}\left(\kappa^{2} ; \Delta_{j}^{2}\right) \mid j=1, \ldots, p\right)^{\top} $$ where $H_{v}\left(; \Delta_{j}^{2}\right.$ ) is the cumulative distribution function (c.d.f.) of a noncentral $\chi^{2}$ distribution with $v$ DF. and noncentrality parameter $\Delta_{j}^{2}(j=1, \ldots, p)$. The MSE of $\hat{\theta}{n}^{\mathrm{HT}}(\kappa)$ is given by $$ \begin{aligned} R\left(\hat{\theta}{n}^{\mathrm{HT}}(\kappa): I_{p}\right)=& \sum_{j=1}^{p} \mathbb{E}\left[\tilde{\theta}{j n} I\left(\left|\tilde{\theta}{j n}\right|>\kappa \sigma n_{j}^{-\frac{1}{2}}\right)-\theta_{j}\right]^{2} \ =& \sigma^{2} \sum_{j=1}^{p} n_{j}^{-1}\left{\left(1-H_{3}\left(\kappa^{2} ; \Delta_{j}^{2}\right)\right)\right.\ &\left.+\Delta_{j}^{2}\left(2 H_{3}\left(\kappa^{2} ; \Delta_{j}^{2}\right)-H_{5}\left(\kappa^{2} ; \Delta_{j}^{2}\right)\right)\right} \end{aligned} $$
Since $\left[\tilde{\theta}{j m} I\left(\left|\tilde{\theta}{j n}\right|>\kappa \sigma n_{j}^{-\frac{1}{2}}\right)-\theta_{j}\right]^{2} \leq\left(\tilde{\theta}{j n}-\theta{j}\right)^{2}+\theta_{j}^{2}$, we obtain $R\left(\hat{\theta}{n}^{\mathrm{HT}}(\kappa): I{p}\right) \leq \sigma^{2} \operatorname{tr} N^{-1}+\theta^{\top} \boldsymbol{\theta} \quad$ (free of $\left.\kappa\right) .$ Following Donoho and Johnstone (1994), one can show that what follows holds: where $\rho_{\mathrm{HT}}(\kappa, 0)=2[(1-\Phi(\kappa))+\kappa \varphi(\kappa)]$, and $\varphi(\cdot)$ and $\Phi(\cdot)$ are the probability density function (p.d.f.) and c.d.f. of standard normal distribution, respectively. Theorem 3.1 Under the assumed regularity conditions, the weighted $\mathrm{L}{2}$-risk bounds are given by $$ R\left(\hat{\boldsymbol{\theta}}{n}^{\mathrm{HT}}(\kappa): N_{1}, N_{2}\right) \leq\left{\begin{array}{lll} \text { (i) } & \sigma^{2}\left(1+\kappa^{2}\right)\left(p_{1}+p_{2}\right) & \kappa>1, \ \text { (ii) } & \sigma^{2}\left(p_{1}+p_{2}\right)+\boldsymbol{\theta}{1}^{\top} N{1} \boldsymbol{\theta}{1} & \ & +\boldsymbol{\theta}{2}^{\top} \boldsymbol{N}{2} \boldsymbol{\theta}{2} & \forall \boldsymbol{\theta} \in \mathbb{R}^{p}, \ \text { (iii) } & \sigma^{2} \rho_{\mathrm{HT}}(\kappa, 0)\left(p_{1}+p_{2}\right) & \ & +1.2\left{\boldsymbol{\theta}{1}^{\top} \boldsymbol{N}{1} \boldsymbol{\theta}{1}+\boldsymbol{\theta}{2}^{\top} N_{2} \boldsymbol{\theta}{2}\right} & 0<\boldsymbol{\theta}{p}^{\top} \end{array}\right. $$ If the solution of $\hat{\theta}{n}^{\mathrm{HT}}(\kappa)$ has the configuration $\left(\tilde{\theta}{1 n}^{\mathrm{T}}, \mathbf{0}^{\mathrm{T}}\right)^{\mathrm{T}}$, then the $\mathrm{L}{2}$ risk of $\hat{\boldsymbol{\theta}}{n}^{\mathrm{HT}}(\kappa)$ is given by $$ R\left(\hat{\boldsymbol{\theta}}{n}^{\mathrm{HT}}(\kappa): \boldsymbol{N}{1}, \boldsymbol{N}{2}\right)=\sigma^{2}\left[p{1}+\Delta^{2}\right], $$ independent of $\kappa$.
统计代写|似然估计作业代写Probability and Estimation代考|LASSO Estimator
The bias expression of the LASSO estimator is given by $$ b\left(\theta_{n}^{\mathrm{L}}(\lambda)\right)=\left(\sigma n_{j}^{-\frac{1}{2}}\left[\lambda\left(2 \Phi\left(\Delta_{j}\right)-1\right) ; j=1, \ldots, p_{1} ;-\Delta_{p_{1}+1}, \ldots, \Delta_{p}\right)^{\top} .\right. $$ The MSE of the LASSO estimator has the form $$ R\left(\hat{\boldsymbol{\theta}}{n}^{\mathrm{L}}(\lambda): \boldsymbol{I}{p}\right)=\sigma^{2} \sum_{j=1}^{p_{1}} n_{j}^{-1} \rho_{\mathrm{ST}}\left(\lambda, \Delta_{j}\right)+\Delta^{2}, $$
where $$ \begin{aligned} \rho_{\mathrm{ST}}\left(\lambda, \Delta_{j}\right)=&\left(1+\lambda^{2}\right)\left{1-\Phi\left(\lambda-\Delta_{j}\right)+\Phi\left(-\lambda-\Delta_{j}\right)\right} \ &+\Delta_{j}^{2}\left{\Phi\left(\lambda-\Delta_{j}\right)-\Phi\left(-\lambda-\Delta_{j}\right)\right} \ &-\left{\left(\lambda-\Delta_{j}\right) \varphi\left(\lambda+\Delta_{j}\right)+\left(\lambda+\Delta_{j}\right) \varphi\left(\lambda-\Delta_{j}\right)\right} \end{aligned} $$ Thus, according to Donoho and Johnstone (1994, Appendix 2), we have the following result. Under the assumed regularity conditions, $R\left(\hat{\theta}{n}^{\mathrm{L}}(\lambda): \boldsymbol{I}{p}\right) \leq\left{\begin{array}{lll}\text { (i) } & \sigma^{2}\left(1+\lambda^{2}\right) \operatorname{tr} N^{-1} & \forall \theta \in \mathbb{R}^{p}, \kappa \ \text { (ii) } & \sigma^{2} \operatorname{tr} N^{-1}+\theta^{\top} \boldsymbol{\theta} & \forall \theta \in \mathbb{R}^{p}, \ \text { (iii) } & \sigma^{2} \rho_{\mathrm{ST}}(\lambda, 0) \operatorname{tr} \boldsymbol{N}^{-1}+1.2 \boldsymbol{\theta}^{\top} \boldsymbol{\theta} & \forall \theta \in \mathbb{R}^{p},\end{array}\right.$ where $\rho_{\mathrm{ST}}(\lambda, 0)=2\left[\left(1+\lambda^{2}\right)(1-\Phi(\lambda))-\kappa \phi(\lambda)\right]$. If the solution of $\hat{\theta}{n}^{L}(\lambda)$ has the configuration $\left(\hat{\theta}{1 n}^{\top}, \mathbf{0}^{\top}\right)$, then the $L_{2}$ risk of $\hat{\theta}{n}^{\mathrm{L}}(\lambda)$ is given by $$ R\left(\hat{\boldsymbol{\theta}}{n}^{\mathrm{L}}(\lambda): N_{1}, N_{2}\right)=\sigma^{2}\left(p_{1}+\Delta^{2}\right) $$ Thus, we note that $$ R\left(\hat{\boldsymbol{\theta}}{n} ; \boldsymbol{N}{1}, \boldsymbol{N}{2}\right)=R\left(\hat{\boldsymbol{\theta}}{n}^{\mathrm{HT}}(\kappa) ; \boldsymbol{N}{1}, \boldsymbol{N}{2}\right)=R\left(\hat{\boldsymbol{\theta}}{n}^{\mathrm{L}}(\lambda) ; \boldsymbol{N}{1}, \boldsymbol{N}{2}\right)=\sigma^{2}\left(p{1}+\Delta^{2}\right) . $$ To prove the $\mathrm{L}{2}$ risk of LASSO, we consider the multivariate decision theory. We are given the LSE of $\theta$ as $\tilde{\theta}{n}=\left(\tilde{\theta}{1 n}, \ldots, \tilde{\theta}{p n}\right)^{\top}$ according to $$ \tilde{\theta}{j n}=\theta{j}+\sigma n_{j}^{-\frac{1}{2}} \mathcal{Z}{j}, \quad \mathcal{Z}{j} \sim \mathcal{N}(0,1), $$ where $\sigma n_{j}^{-\frac{1}{2}}$ is the marginal variance of $\tilde{\theta}{j n}$ and noise level, and $\left{\theta{j}\right}_{j=1, \ldots, p}$ are the treatment effects of interest. We measure the quality of the estimators based on the $\mathrm{L}{2}$ risk, $R\left(\tilde{\boldsymbol{\theta}}{n}: \boldsymbol{I}{p}\right)=\mathbb{E}\left[\left|\tilde{\boldsymbol{\theta}}{n}-\boldsymbol{\theta}\right|^{2}\right]$. Note that for a sparse solution, we use (3.11). Consider the family of diagonal linear projections, $$ T_{\mathrm{DP}}\left(\hat{\theta}{n}^{\mathrm{L}}(\lambda): \delta\right)=\left(\delta{1} \hat{\theta}{1 n}^{\mathrm{L}}(\lambda), \ldots, \delta{p} \hat{\theta}{p n}^{\mathrm{L}}(\lambda)\right)^{\top}, $$ where $\delta=\left(\delta{1}, \ldots, \delta_{p}\right)^{\top}, \delta_{j} \in(0,1), j=1, \ldots, p$. Such estimators “kill” or “keep” the coordinates.
Suppose we had available an oracle which would supply for us the coefficients $\delta_{j}$ optimal for use in the diagonal projection scheme (3.15). These “ideal” coefficients are $\delta_{j}=I\left(\left|\theta_{j}\right|>\sigma n_{j}^{-\frac{1}{2}}\right)$. Ideal diagonal projections consist of estimating only those $\theta_{j}$, which are larger than its noise, $\sigma n_{j}^{-\frac{1}{2}}(j=1, \ldots, p)$. These yield the “ideal” $\mathrm{L}_{2}$ risk given by (3.16).
统计代写|似然估计作业代写Probability and Estimation代考|Bias and Weighted L2 Risks of Estimators
如果你也在 怎样代写似然估计Probability and Estimation这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
似然估计是一种统计方法,它用来求一个样本集的相关概率密度函数的参数。
statistics-lab™ 为您的留学生涯保驾护航 在代写似然估计Probability and Estimation方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写似然估计Probability and Estimation代写方面经验极为丰富,各种代写似然估计Probability and Estimation相关的作业也就用不着说。
我们提供的似然估计Probability and Estimation及其相关学科的代写,服务范围广, 其中包括但不限于:
Statistical Inference 统计推断
Statistical Computing 统计计算
Advanced Probability Theory 高等楖率论
Advanced Mathematical Statistics 高等数理统计学
(Generalized) Linear Models 广义线性模型
Statistical Machine Learning 统计机器学习
Longitudinal Data Analysis 纵向数据分析
Foundations of Data Science 数据科学基础
统计代写|似然估计作业代写Probability and Estimation代考|Test of Significance
统计代写|似然估计作业代写Probability and Estimation代考|Test of Significance
For the test of $\mathcal{H}{\mathrm{o}}: \boldsymbol{\theta}{2}=\mathbf{0}$ vs. $\mathcal{H}{\mathrm{A}}: \boldsymbol{\theta}{2} \neq \mathbf{0}$, we consider the statistic $\mathcal{L}{n}$ given by $$ \begin{aligned} \mathcal{L}{n} &=\frac{1}{\sigma^{2}} \tilde{\boldsymbol{\theta}}{2 n}^{\top} \boldsymbol{N}{2} \tilde{\boldsymbol{\theta}}{2 n}, \quad \text { if } \sigma^{2} \text { is known } \ &=\frac{1}{p{2} s_{n}^{2}} \tilde{\boldsymbol{\theta}}{2 n}^{\top} \boldsymbol{N}{2} \tilde{\boldsymbol{\theta}}{2 n}, \quad \text { if } \sigma^{2} \text { is unknown. } \end{aligned} $$ Under a null-hypothesis $\mathcal{H}{0}$, the null distribution of $\mathcal{L}{n}$ is the central $\chi^{2}$ distribution with $p{2}$ DF. when $\sigma^{2}$ is known and the central $F$-distribution with $\left(p_{2}, m\right)$ DE in the case of $\sigma^{2}$ being unknown, respectively. Under the alternative hypothesis, $\mathcal{H}{A}$, the test statistics $\mathcal{L}{n}$ follows the noncentral version of the mentioned densities. In both cases, the noncentrality parameter is $\Delta^{2}=\theta_{2}^{\top} N_{2} \theta_{2} / \sigma^{2}$. In this paper, we always assume that $\sigma^{2}$ is known, then $\mathcal{L}{n}$ follows a chi-square distribution with $p{2} \mathrm{DF}$. Further, we note that $$ \tilde{\theta}{j n} \sim \mathcal{N}\left(\theta{j}, \sigma^{2} n_{j}^{-1}\right), \quad j=1, \ldots, p $$ so that $\left.\mathcal{Z}{j}=\sqrt{n{j}} \tilde{\theta}{j n} / \sigma \sim \mathcal{N}^{(} \Delta{j}, 1\right)$, where $\Delta_{j}=\sqrt{n_{j}} \theta_{j} / \sigma$. Thus, one may use $\mathcal{Z}{j}$ to test the null-hypothesis $\mathcal{H}{\mathrm{o}}^{(j)}: \theta_{j}=0$ vs. $\mathcal{H}{\mathrm{A}}^{(j)}: \theta{j} \neq 0, j=p_{1}+1, \ldots, p$.
In this chapter, we are interested in studying three penalty estimators, namely, (i) the subset rule called “hard threshold estimator” (HTE), (ii) LASSO or the “soft threshold estimator” (STE), (iii) the “ridge regression estimator” (RRE), (iv) the classical PTE and shrinkage estimators such as “Stein estimator” (SE) and “positive-rule Stein-type estimator” (PRSE).
统计代写|似然估计作业代写Probability and Estimation代考|Penalty Estimators
In this section, we discuss the penalty estimators. Define the HTE as $$ \begin{aligned} \hat{\boldsymbol{\theta}}{n}^{\mathrm{HT}}(\kappa) &=\left(\tilde{\theta}{j n} I\left(\left|\tilde{\theta}{j n}\right|>\kappa \sigma n{j}^{-\frac{1}{2}}\right) \mid j=1, \ldots, p\right)^{\top} \ &=\left(\sigma n_{j}^{-\frac{1}{2}} \mathcal{Z}{j} I\left(\left|\mathcal{Z}{j}\right|>\kappa\right) \mid j=1, \ldots, p\right)^{\top} \end{aligned} $$ where $\kappa$ is a positive threshold parameter. This estimator is discrete in nature and may be extremely variable and unstable due to the fact that small changes in the data can result in very different models and can reduce the prediction accuracy. As such we obtain the continuous version of $\hat{\theta}{n}^{\mathrm{HT}}(\kappa)$, and the LASSO is defined by $$ \hat{\boldsymbol{\theta}}{n}^{\mathrm{L}}(\lambda)=\operatorname{argmin}{\theta}(\boldsymbol{Y}-\boldsymbol{B} \boldsymbol{\theta})^{\top}(\boldsymbol{Y}-\boldsymbol{B} \theta)+2 \lambda \sigma \sum{j=1}^{p} \sqrt{n_{j}} \kappa\left|\theta_{j}\right|, $$ where $|\theta|=\left(\left|\theta_{1}\right|, \ldots,\left|\theta_{p}\right|\right)^{\mathrm{T}}$, yielding the equation $$ \boldsymbol{B}^{\top} \boldsymbol{B} \boldsymbol{\theta}-\boldsymbol{B}^{\top} \boldsymbol{Y}+\lambda \sigma \boldsymbol{N}^{\frac{1}{2}} \operatorname{sgn}(\boldsymbol{\theta})=\mathbf{0} $$ or $$ \hat{\boldsymbol{\theta}}{n}^{\mathrm{L}}(\lambda)-\tilde{\boldsymbol{\theta}}{n}+\frac{1}{2} \lambda \sigma \boldsymbol{N}^{-\frac{1}{2}} \operatorname{sgn}\left(\hat{\boldsymbol{\theta}}{n}^{\mathrm{L}}(\lambda)\right)=\mathbf{0} . $$ Now, the $j$ th component of (3.5) is given by $$ \hat{\theta}{j n}^{\mathrm{L}}(\lambda)-\ddot{\theta}{j n}+\lambda \sigma n{j}^{-\frac{1}{2}} \operatorname{sgn}\left(\hat{\theta}{j m}^{\mathrm{L}}(\lambda)\right)=0 . $$ Then, we consider three cases: (i) $\operatorname{sgn}\left(\hat{\theta}{j n}^{L}(\lambda)\right)=+1$, then, (3.6) reduces to $$ 0<\frac{\hat{\theta}{j n}^{\mathrm{L}}(\lambda)}{\sigma n{j}^{-\frac{1}{2}}}-\frac{\tilde{\theta}{j n}}{\sigma n{j}^{-\frac{1}{2}}}+\lambda=0 . $$ Hence, $$ 0<\hat{\theta}{j n}^{L}(\lambda)=\sigma n{j}^{-\frac{1}{2}}\left(Z_{j}-\lambda\right)=\sigma n_{j}^{-\frac{1}{2}}\left(\left|Z_{j}\right|-\lambda\right), $$ with, clearly, $\mathcal{Z}{j}>0$ and $\left|\mathcal{Z}{j}\right|>\lambda$.
统计代写|似然估计作业代写Probability and Estimation代考|Preliminary Test and Stein-Type Estimators
We recall that the unrestricted estimator of $\theta=\left(\theta_{1}^{\top}, \theta_{2}^{\top}\right)^{\top}$ is given by $\left(\tilde{\theta}{1 n}^{\top}, \tilde{\theta}{2 n}^{\top}\right)^{\top}$ with marginal distribution $\tilde{\theta}{1 n} \sim \mathcal{N}{p_{1}}\left(\theta_{1}, \sigma^{2} N_{1}^{-1}\right)$ and $\tilde{\theta}{2 n} \sim \mathcal{N}{p_{2}}\left(\theta_{2}, \sigma^{2} N_{2}^{-1}\right)$, respectively. The restricted estimator of $\left(\theta_{1}^{\top}, \mathbf{0}^{\top}\right)^{\top}$ is $\left(\tilde{\theta}{1 n}^{\top}, \mathbf{0}^{\top}\right)^{\top}$. Similarly, the PTE of $\theta$ is given by $$ \hat{\theta}{n}^{\mathrm{PT}}(\alpha)=\left(\begin{array}{c} \tilde{\theta}{1 n} \ \tilde{\theta}{2 n} I\left(\mathcal{L}{n}>c{\alpha}\right) \end{array}\right), $$ where $I(A)$ is the indicator function of the set $A, \mathcal{L}{n}$ is the test statistic given in Section $2.2$, and $c{\alpha}$ is the $\alpha$-level critical value. Similarly, the Stein estimator (SE) is given by $$ \hat{\boldsymbol{\theta}}{n}^{\mathrm{S}}=\left(\begin{array}{c} \tilde{\boldsymbol{\theta}}{1 n} \ \tilde{\boldsymbol{\theta}}{2 n}\left(1-\left(p{2}-2\right) \mathcal{L}{n}^{-1}\right) \end{array}\right), \quad p{2} \geq 3 $$
and the positive-rule Stein-type estimator (PRSE) is given by $$ \hat{\boldsymbol{\theta}}{n}^{\mathrm{S+}}=\left(\begin{array}{c} \tilde{\boldsymbol{\theta}}{1 n} \ \hat{\theta}{2 n}^{\mathrm{S}} I\left(\mathcal{L}{n}>p_{2}-2\right) \end{array}\right) $$
统计代写|似然估计作业代写Probability and Estimation代考|Test of Significance
如果你也在 怎样代写似然估计Probability and Estimation这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
似然估计是一种统计方法,它用来求一个样本集的相关概率密度函数的参数。
statistics-lab™ 为您的留学生涯保驾护航 在代写似然估计Probability and Estimation方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写似然估计Probability and Estimation代写方面经验极为丰富,各种代写似然估计Probability and Estimation相关的作业也就用不着说。
我们提供的似然估计Probability and Estimation及其相关学科的代写,服务范围广, 其中包括但不限于:
Statistical Inference 统计推断
Statistical Computing 统计计算
Advanced Probability Theory 高等楖率论
Advanced Mathematical Statistics 高等数理统计学
(Generalized) Linear Models 广义线性模型
Statistical Machine Learning 统计机器学习
Longitudinal Data Analysis 纵向数据分析
Foundations of Data Science 数据科学基础
统计代写|似然估计作业代写Probability and Estimation代考|ANOVA Model
统计代写|似然估计作业代写Probability and Estimation代考|Introduction
An important model belonging to the class of general linear hypothesis is the analysis of variance (ANOVA) model. In this model, we consider the assessment of $p$ treatment effects by considering sample experiments of sizes $n_{1}$, $n_{2}, \ldots, n_{p}$, respectively, with the responses $\left{\left(y_{i 1}, \ldots, y_{i n_{i}}\right)^{\mathrm{T}} ; i=1,2, \ldots, p\right}$ which satisfy the model, $y_{i j}=\theta_{i}+e_{i j}\left(j=1, \ldots, n_{i}, i=1, \ldots, p\right)$. The main objective of the chapter is the selection of the treatments which would yield best results. Accordingly, we consider the penalty estimators, namely, ridge, subset selection rule, and least absolute shrinkage and selection operator (LASSO) together with the classical shrinkage estimators, namely, the preliminary test estimator (PTE), the Stein-type estimators (SE), and positive-rule Stein-type estimator (PRSE) of $\theta=\left(\theta_{1}, \ldots, \theta_{p}\right)^{\top}$. For LASSO and related methods, see Breiman (1996), Fan and Li (2001), Zou and Hastie (2005), and Zou (2006), among others; and for PTE and SE, see Judge and Bock (1978) and Saleh (2006), among others.
The chapter points to the useful “selection” aspect of LASSO and ridge estimators as well as limitations found in other papers. Our conclusions are based on the ideal $\mathrm{L}{2}$ risk of LASSO of an oracle which would supply optimal coefficients in a diagonal projection scheme given by Donoho and Johnstone (1994, p. 437). The comparison of the estimators considered here are based on mathematical analysis as well as by tables of $\mathrm{L}{2}$-risk efficiencies and graphs and not by simulation.
In his pioneering paper, Tibshirani (1996) examined the relative performance of the subset selection, ridge regression, and LASSO in three different scenarios, under orthogonal design matrix in a linear regression model: (a) Small number of large coefficients: subset selection does the best here, the LASSO not quite as well, ridge regression does quite poorly. (b) Small to moderate numbers of moderate-size coefficients: LASSO does the best, followed by ridge regression and then subset selection.
统计代写|似然估计作业代写Probability and Estimation代考|Model, Estimation, and Tests
Consider the ANOVA model $$ \boldsymbol{Y}=\boldsymbol{B} \boldsymbol{\theta}+\boldsymbol{\epsilon}=\boldsymbol{B}{1} \boldsymbol{\theta}{1}+\boldsymbol{B}{2} \boldsymbol{\theta}{2}+\boldsymbol{\epsilon}, $$ where $Y=\left(y_{11}, \ldots, y_{1 n_{1}}, \ldots, y_{p_{1}}, \ldots, y_{p w_{p}}\right)^{\top}, \theta=\left(\theta_{1}, \ldots, \theta_{p_{1}}, \theta_{p_{1}+1}, \ldots, \theta_{p}\right)^{\top}$ is the unknown vector that can be partitioned as $\boldsymbol{\theta}=\left(\boldsymbol{\theta}{1}^{\top}, \boldsymbol{\theta}{2}^{\top}\right)^{\top}$, where $\boldsymbol{\theta}{1}=$ $\left(\theta{1}, \ldots, \theta_{p_{1}}\right)^{\top}$, and $\theta_{2}=\left(\theta_{p_{1}+1}, \ldots, \theta_{p}\right)^{\top}$.
The error vector $\boldsymbol{\epsilon}$ is $\left(\epsilon_{11}, \ldots, \epsilon_{1 n_{1}}, \ldots, \epsilon_{p_{1}}, \ldots, \epsilon_{p v_{p}}\right)^{\top}$ with $\boldsymbol{E} \sim \mathcal{N}{n}\left(\mathbf{0}, \sigma^{2} I{n}\right)$. The notation $B$ stands for a block-diagonal vector of $\left(\mathbf{1}{n{1}}, \ldots, \mathbf{1}{n{p}}\right)$ which can subdivide into two matrices $\boldsymbol{B}{1}$ and $\boldsymbol{B}{2}$ as $\left(\boldsymbol{B}{1}, \boldsymbol{B}{2}\right)$, where $\mathbf{1}{n{j}}=(1, \ldots, 1)^{\top}$ is an $n_{i}$-tuples of $1 \mathrm{~s}, \boldsymbol{I}{n}$ is the $n$-dimensional identity matrix where $n=n{1}+\cdots+n_{p}$, and $\sigma^{2}$ is the known variance of the errors.
Our objective is to estimate and select the treatments $\theta=\left(\theta_{1}, \ldots, \theta_{p}\right)^{\top}$ when we suspect that the subset $\theta_{2}=\left(\theta_{p_{1}+1}, \ldots, \theta_{p}\right)^{\top}$ may be $\mathbf{0}$, i.e. ineffective. Thus, we consider the model (3.1) and discuss the LSE of $\theta$ in Section 3.2.1.
统计代写|似然估计作业代写Probability and Estimation代考|Estimation of Treatment Effects
First, we consider the unrestricted LSE of $\theta=\left(\theta_{1}^{\top}, \theta_{2}^{\top}\right)^{\top}$ given by $\tilde{\theta}{n}=\operatorname{argmin}{\theta}\left{\left(\boldsymbol{Y}-\boldsymbol{B}{1} \boldsymbol{\theta}{1}-\boldsymbol{B}{2} \boldsymbol{\theta}{2}\right)^{\top}\left(\boldsymbol{Y}-\boldsymbol{B}{1} \boldsymbol{\theta}{1}-\boldsymbol{B}{2} \boldsymbol{\theta}{2}\right)\right}$ $=\left(\begin{array}{cc}\boldsymbol{B}{1}^{\top} \boldsymbol{B}{1} & \boldsymbol{B}{1}^{\top} \boldsymbol{B}{2} \ \boldsymbol{B}{2}^{\top} \boldsymbol{B}{1} & \boldsymbol{B}{2}^{\top} \boldsymbol{B}{2}\end{array}\right)^{-1}\left(\begin{array}{c}\boldsymbol{B}{1}^{\top} \boldsymbol{Y} \ \boldsymbol{B}{2}^{\top} \boldsymbol{Y}\end{array}\right)=\left(\begin{array}{cc}\boldsymbol{N}{1} & \mathbf{0} \ \mathbf{0} & \boldsymbol{N}{2}\end{array}\right)^{-1}\left(\begin{array}{c}\boldsymbol{B}{1}^{\top} \boldsymbol{Y} \ \boldsymbol{B}{2}^{\top} \boldsymbol{Y}\end{array}\right)$ $=\left(\begin{array}{c}\boldsymbol{N}{1}^{-1} \boldsymbol{B}{1}^{\top} \boldsymbol{Y} \ \boldsymbol{N}{2}^{-1} \boldsymbol{B}{2}^{\top} \boldsymbol{Y}\end{array}\right)=\left(\begin{array}{l}\tilde{\boldsymbol{\theta}}{1 n} \ \tilde{\boldsymbol{\theta}}{2 n}\end{array}\right)$, where $\boldsymbol{N}=\boldsymbol{B}^{\top} \boldsymbol{B}=\operatorname{Diag}\left(n_{1}, \ldots, n_{p}\right), \quad \boldsymbol{N}{1}=\operatorname{Diag}\left(n{1}, \ldots, n_{p_{1}}\right), \quad$ and $\quad \boldsymbol{N}{2}=$ $\operatorname{Diag}\left(n{p_{1}+1}, \ldots, n_{p}\right)$.
In case $\sigma^{2}$ is unknown, the best linear unbiased estimator (BLUE) of $\sigma^{2}$ is given by $$ s_{n}^{2}=(n-p)^{-1}\left(\boldsymbol{Y}-\boldsymbol{B}{1} \tilde{\theta}{1 n}-\boldsymbol{B}{2} \tilde{\theta}{2 n}\right)^{\top}\left(\boldsymbol{Y}-\boldsymbol{B}{1} \tilde{\theta}{1 n}-\boldsymbol{B}{2} \tilde{\theta}{2 n}\right) . $$ Clearly, $\tilde{\theta}{n} \sim \mathcal{N}{p}\left(\theta, \sigma^{2} N^{-1}\right)$ is independent of $m s_{n}^{2} / \sigma^{2}(m=n-p)$, which follows a central $\chi^{2}$ distribution with $m$ degrees of freedom (DF).
When $\theta_{2}=\mathbf{0}$, the restricted least squares estimator (RLSE) of $\theta_{\mathrm{R}}=\left(\theta_{1}^{\top}, \mathbf{0}^{\top}\right)^{\top}$ is given by $\hat{\boldsymbol{\theta}}{\mathrm{R}}=\left(\tilde{\boldsymbol{\theta}}{1 n}^{\top}, \boldsymbol{0}^{\top}\right)^{\top}$, where $\tilde{\boldsymbol{\theta}}{1 n}=\boldsymbol{N}{1}^{-1} \boldsymbol{B}_{1}^{\top} \boldsymbol{Y}$.
统计代写|似然估计作业代写Probability and Estimation代考|ANOVA Model
如果你也在 怎样代写似然估计Probability and Estimation这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
似然估计是一种统计方法,它用来求一个样本集的相关概率密度函数的参数。
statistics-lab™ 为您的留学生涯保驾护航 在代写似然估计Probability and Estimation方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写似然估计Probability and Estimation代写方面经验极为丰富,各种代写似然估计Probability and Estimation相关的作业也就用不着说。
我们提供的似然估计Probability and Estimation及其相关学科的代写,服务范围广, 其中包括但不限于:
Statistical Inference 统计推断
Statistical Computing 统计计算
Advanced Probability Theory 高等楖率论
Advanced Mathematical Statistics 高等数理统计学
(Generalized) Linear Models 广义线性模型
Statistical Machine Learning 统计机器学习
Longitudinal Data Analysis 纵向数据分析
Foundations of Data Science 数据科学基础
统计代写|似然估计作业代写Probability and Estimation代考|Bias and MSE Expressions
统计代写|似然估计作业代写Probability and Estimation代考|Bias and MSE Expressions
From (2.65), it is easy to see that the bias expression of $\hat{\theta}{n}^{\mathrm{RR}}(k)$ and $\hat{\beta}{n}^{\mathrm{RR}}(k)$, respectively, are given by $$ \begin{aligned} &b\left(\hat{\theta}{n}^{\mathrm{RR}}(k)\right)=-\frac{k}{Q+k} \beta \bar{x} \ &b\left(\hat{\beta}{n}^{\mathrm{RR}}(k)\right)=-\frac{k}{Q+k} \beta . \end{aligned} $$ Similarly, MSE expressions of the estimators are given by $$ \begin{aligned} \operatorname{MSE}\left(\hat{\theta}{n}^{\mathrm{RR}}(k)\right) &=\frac{\sigma^{2}}{n}\left(1+\frac{n \bar{x}^{2} Q}{(Q+k)^{2}}\right)+\frac{k^{2} \beta^{2} \bar{x}^{2}}{(Q+k)^{2}} \ &=\frac{\sigma^{2}}{n}\left{\left(1+\frac{n \bar{x}^{2} Q}{(Q+k)^{2}}\right)+\frac{n \bar{x}^{2} k^{2} \beta^{2}}{(Q+k)^{2} \sigma^{2}}\right} \ &=\frac{\sigma^{2}}{n}\left{1+\frac{n \bar{x}^{2}}{Q(Q+k)^{2}}\left(Q^{2}+k^{2} \Delta^{2}\right)\right} \end{aligned} $$ where $\Delta^{2}=\frac{Q \rho^{2}}{\sigma^{2}}$ and $$ \begin{aligned} \operatorname{MSE}\left(\hat{\beta}{n}^{\mathrm{RR}}(k)\right) &=\frac{\sigma^{2} Q}{(Q+k)^{2}}+\frac{k^{2} \beta^{2}}{(Q+k)^{2}} \ &=\frac{\sigma^{2}}{Q(Q+k)^{2}}\left(Q^{2}+k^{2} \Delta^{2}\right) . \end{aligned} $$ Hence, the REff of these estimators are given by $$ \begin{aligned} \operatorname{REff}\left(\hat{\theta}{n}^{\mathrm{RR}}(k): \tilde{\theta}{n}\right) &=\left(1+\frac{n \bar{x}^{2}}{Q}\right)\left{1+\frac{n \bar{x}^{2}}{Q(Q+k)^{2}}\left(Q^{2}+k^{2} \Delta^{2}\right)\right}^{-1} \ \operatorname{REff}\left(\hat{\beta}{n}^{\mathrm{RR}}(k): \tilde{\beta}{n}\right) &=(Q+k)^{2}\left(Q^{2}+k \Delta^{2}\right)^{-1} \ &=\left(1+\frac{k}{Q}\right)\left{1+\frac{k \Delta^{2}}{Q^{2}}\right}^{-1} \end{aligned} $$
Note that the optimum value of $k$ is $Q \Delta^{-2}$. Hence, $$ \begin{aligned} \operatorname{MSE}\left(\hat{\theta}{n}^{\mathrm{RR}}\left(Q \Delta^{-2}\right)\right) &=\frac{\sigma^{2}}{n}\left(1+\frac{n \bar{x}^{2} \Delta^{2}}{Q\left(1+\Delta^{2}\right)}\right) \ \operatorname{REff}\left(\hat{\theta}{n}^{\mathrm{RR}}\left(Q \Delta^{-2}\right): \tilde{\theta}{n}\right) &=\left(1+\frac{n \bar{x}^{2}}{Q}\right)\left{1+\frac{n \bar{x}^{2} \Delta^{2}}{Q\left(1+\Delta^{2}\right)}\right}^{-1} \ \operatorname{MSE}\left(\hat{\beta}{n}^{\mathrm{RR}}\left(Q \Delta^{-2}\right)\right) &=\frac{\sigma^{2}}{Q}\left(\frac{1+\Delta^{2}}{\Delta^{2}}\right)\left(\frac{Q}{1+Q}\right) \ \operatorname{REff}\left(\hat{\beta}{n}^{\mathrm{RR}}\left(Q \Delta^{-2}\right): \tilde{\beta}{n}\right) &=\left(\frac{1+\Delta^{2}}{\Delta^{2}}\right)\left(\frac{Q}{1+Q}\right) \end{aligned} $$
统计代写|似然估计作业代写Probability and Estimation代考|LASSO Estimation of Intercept and Slope
In this section, we consider the LASSO estimation of $(\theta, \beta)$ when it is suspected that $\beta$ may be 0 . For this case, the solution is given by $$ \left(\hat{\theta}{n}^{\mathrm{LASSO}}(\lambda), \hat{\beta}{n}^{\mathrm{LASSO}}(\lambda)\right)^{\top}=\operatorname{argmin}{(\theta), \beta}}\left{\left|Y-\theta \mathbf{1}{n}-\beta x\right|^{2}+\sqrt{Q} \lambda \sigma|\beta|\right} . $$ Explicitly, we find $$ \begin{aligned} \hat{\theta}{n}^{\mathrm{LASSO}}(\lambda) &=\bar{y}-\hat{\beta}{n}^{\mathrm{LASSO}} \bar{x} \ \hat{\beta}{n}^{\mathrm{LASSO}} &=\operatorname{sgn}(\tilde{\beta})\left(|\tilde{\beta}|-\lambda \frac{\sigma}{\sqrt{Q}}\right)^{+} \ &=\frac{\sigma}{\sqrt{Q}} \operatorname{sgn}\left(Z{n}\right)\left(\left|Z_{n}\right|-\lambda\right)^{+}, \end{aligned} $$ where $Z_{n}=\sqrt{Q} \tilde{\beta}{n} / \sigma \sim \mathcal{N}(\Delta, 1)$ and $\Delta=\sqrt{Q} \beta / \sigma$. According to Donoho and Johnstone (1994), and results of Section 2.2.5, the bias and MSE expressions for $\hat{\beta}{n}^{\mathrm{LASSO}}(\lambda)$ are given by $$ \begin{aligned} b\left(\hat{\beta}{n}^{\mathrm{LASSO}}(\lambda)\right)=& \frac{\sigma}{\sqrt{Q}}{\lambda[\Phi(\lambda-\Delta)-\Phi(\lambda+\Delta)]\ &+\Delta[\Phi(-\lambda-\Delta)-\Phi(\lambda-\Delta)] \ &+[\phi(\lambda-\Delta)-\phi(\lambda+\Delta)]}, \ \operatorname{MSE}\left(\hat{\beta}{n}^{\mathrm{LASSO}}(\lambda)\right)=& \frac{\sigma^{2}}{Q} \rho_{\mathrm{ST}}(\lambda, \Delta), \end{aligned} $$ where $$ \begin{aligned} \rho_{\mathrm{ST}}(\lambda, \Delta)=& 1+\lambda^{2}+\left(1-\Delta^{2}-\lambda^{2}\right){\Phi(\lambda-\Delta)-\Phi(-\lambda-\Delta)} \ &-(\lambda-\Delta) \phi(\lambda+\Delta)-(\lambda+\Delta) \phi(\lambda-\Delta) \end{aligned} $$
统计代写|似然估计作业代写Probability and Estimation代考|Summary and Concluding Remarks
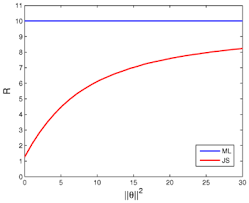
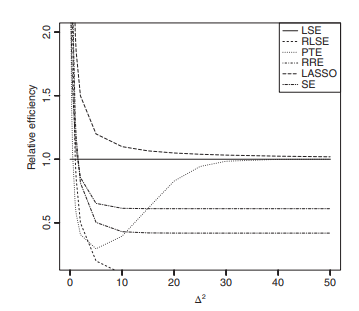
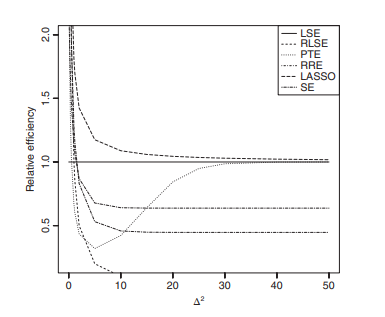
This chapter considers the location model and the simple linear regression model when errors of the models are normally distributed. We consider LSE, RLSE, PTE, SE and two penalty estimators, namely, the RRE and the LASSO estimator for the location parameter for the location model and the intercept and slope parameter for the simple linear regression model. We found that the RRE uniformly dominates LSE, PTE, SE, and LASSO. However, RLSE dominates all estimators near the null hypothesis. LASSO dominates LSE, PTE, and SE uniformly.
统计代写|似然估计作业代写Probability and Estimation代考|Bias and MSE Expressions
如果你也在 怎样代写似然估计Probability and Estimation这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
似然估计是一种统计方法,它用来求一个样本集的相关概率密度函数的参数。
statistics-lab™ 为您的留学生涯保驾护航 在代写似然估计Probability and Estimation方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写似然估计Probability and Estimation代写方面经验极为丰富,各种代写似然估计Probability and Estimation相关的作业也就用不着说。
我们提供的似然估计Probability and Estimation及其相关学科的代写,服务范围广, 其中包括但不限于:
Statistical Inference 统计推断
Statistical Computing 统计计算
Advanced Probability Theory 高等楖率论
Advanced Mathematical Statistics 高等数理统计学
(Generalized) Linear Models 广义线性模型
Statistical Machine Learning 统计机器学习
Longitudinal Data Analysis 纵向数据分析
Foundations of Data Science 数据科学基础
统计代写|似然估计作业代写Probability and Estimation代考|Comparison of Bias and MSE Functions
统计代写|似然估计作业代写Probability and Estimation代考|Comparison of Bias and MSE Functions
Since the bias and MSE expressions are known to us, we may compare them for the three estimators, namely, $\tilde{\theta}{n}, \hat{\theta}{n}$, and $\hat{\theta}{n}^{\mathrm{PT}}(\alpha)$ as well as $\tilde{\beta}{n}, \hat{\beta}{n}$, and $\hat{\beta}{n}^{\mathrm{PT}}(\alpha)$. Note that all the expressions are functions of $\Delta^{2}$, which is the noncentrality parameter of the noncentral $F$-distribution. Also, $\Delta^{2}$ is the standardized distance between $\beta$ and $\beta_{\mathrm{o}}$. First, we compare the bias functions as in Theorem $2.4$, when $\sigma^{2}$ is unknown. For $\bar{x}=0$ or under $\mathcal{H}{\mathrm{o}}$, $$ \begin{aligned} &b\left(\tilde{\theta}{n}\right)=b\left(\hat{\theta}{n}\right)=b\left(\hat{\theta}{n}^{\mathrm{pT}}(\alpha)\right)=0 \ &b\left(\tilde{\beta}{n}\right)=b\left(\hat{\beta}{n}\right)=b\left(\hat{\beta}_{n}^{\mathrm{PT}}(\alpha)\right)=0 . \end{aligned} $$
Otherwise, for all $\Delta^{2}$ and $\bar{x} \neq 0$, $$ \begin{aligned} &0=b\left(\tilde{\theta}{n}\right) \leq\left|b\left(\hat{\theta}{n}^{\mathrm{pT}}(\alpha)\right)\right|=\left|\beta-\beta_{\mathrm{o}}\right| \bar{x}{3, m}\left(\frac{1}{3} F{1, m}(\alpha) ; \Delta^{2}\right) \leq\left|b\left(\hat{\theta}{n}\right)\right| \ &0=b\left(\tilde{\beta}{n}\right) \leq\left|b\left(\hat{\beta}{n}^{\mathrm{pT}}(\alpha)\right)\right|=\left|\beta-\beta{\mathrm{o}}\right| G_{3, m}\left(\frac{1}{3} F_{1, m}(\alpha) ; \Delta^{2}\right) \leq\left|b\left(\hat{\beta}{n}\right)\right| . \end{aligned} $$ The absolute bias of $\hat{\theta}{n}$ is linear in $\Delta^{2}$, while the absolute bias of $\hat{\theta}{n}^{\mathrm{pT}}(\alpha)$ increases to the maximum as $\Delta^{2}$ moves away from the origin, and then decreases toward zero as $\Delta^{2} \rightarrow \infty$. Similar conclusions hold for $\hat{\beta}{n}^{\mathrm{PT}}(\alpha)$.
Now, we compare the MSE functions of the restricted estimators and PTEs with respect to the traditional estimator, $\tilde{\theta}{n}$ and $\tilde{\beta}{n}$, respectively. The REff of $\hat{\theta}{n}$ compared to $\tilde{\theta}{n}$ may be written as $$ \operatorname{REff}\left(\hat{\theta}{n}: \tilde{\theta}{n}\right)=\left(1+\frac{n \bar{x}^{2}}{Q}\right)\left[1+\frac{n \bar{x}^{2}}{Q} \Delta^{2}\right]^{-1} \text {. } $$ The efficiency is a decreasing function of $\Delta^{2}$. Under $\mathcal{H}{\mathrm{o}}$ (i.e. $\Delta^{2}=0$ ), it has the maximum value $$ \operatorname{REff}\left(\hat{\theta}{n} ; \tilde{\theta}{n}\right)=\left(1+\frac{n \bar{x}^{2}}{Q}\right) \geq 1, $$ and $\operatorname{REff}\left(\hat{\theta}{n} ; \tilde{\theta}{n}\right) \geq 1$, accordingly, as $\Delta^{2} \geq 1$. Thus, $\hat{\theta}{n}$ performs better than $\tilde{\theta}{n}$ whenever $\Delta^{2}<1$; otherwise, $\tilde{\theta}{n}$ performs better $\hat{\theta}{n}$. The REff of $\hat{\theta}{n}^{\mathrm{pT}}(\alpha)$ compared to $\tilde{\theta}{n}$ may be written as $$ \operatorname{REff}\left(\hat{\theta}{n}^{\mathrm{PT}}(\alpha) ; \tilde{\theta}{n}\right)=\left[1+g\left(\Delta^{2}\right)\right]^{-1}, $$ where $$ \begin{aligned} g\left(\Delta^{2}\right)=&-\frac{\bar{x}^{2}}{Q}\left(\frac{1}{n}+\frac{\bar{x}^{2}}{Q}\right)^{-1}\left[G{3, m}\left(\frac{1}{3} F_{1, m}(\alpha) ; \Delta^{2}\right)\right.\ &\left.-\Delta^{2}\left{2 G_{3, m}\left(\frac{1}{3} F_{1, m}(\alpha) ; \Delta^{2}\right)-G_{5, m}\left(\frac{1}{5} F_{1, m}(\alpha) ; \Delta^{2}\right)\right}\right] \end{aligned} $$ Under the $\mathcal{H}{0}$, it has the maximum value $$ \operatorname{REff}\left(\hat{\theta}{n}^{\mathrm{pT}}(\alpha) ; \tilde{\theta}{n}\right)=\left{1-\frac{\bar{x}^{2}}{Q}\left(\frac{1}{n}+\frac{\bar{x}^{2}}{Q}\right)^{-1} G{3, m}\left(\frac{1}{3} F_{1, m}(\alpha) ; 0\right)\right}^{-1} \geq 1 $$ and $\operatorname{REff}\left(\hat{\theta}{n}^{\mathrm{pT}}(\alpha) ; \ddot{\theta}{n}\right)$ according as $$ \Delta^{2} \leq \Delta^{2}(\alpha)=\frac{G_{3, m}\left(\frac{1}{3} F_{1, m}(\alpha) ; \Delta^{2}\right)}{2 G_{3, m}\left(\frac{1}{3} F_{1, m}(\alpha) ; \Delta^{2}\right)-G_{5, m}\left(\frac{1}{5} F_{1, m}(\alpha) ; \Delta^{2}\right)} $$
统计代写|似然估计作业代写Probability and Estimation代考|Alternative PTE
In this subsection, we provide the alternative expressions for the estimator of PT and its bias and MSE. To test the hypothesis $\mathcal{H}{0}: \beta=0$ vs. $\mathcal{H}{\mathrm{A}}: \beta \neq 0$, we use the following test statistic: $$ Z_{n}=\frac{\sqrt{Q} \tilde{\beta}{n}}{\sigma} . $$ The PTE of $\beta$ is given by $$ \begin{aligned} \hat{\beta}{n}^{\mathrm{PT}}(\alpha) &=\tilde{\beta}{n}-\tilde{\beta}{n} I\left(\left|\tilde{\beta}{n}\right|<\frac{\lambda \sigma}{\sqrt{Q}}\right) \ &=\frac{\sigma}{\sqrt{Q}}\left[Z{n}-Z_{n} I\left(\left|Z_{n}\right|<\lambda\right)\right] \end{aligned} $$ where $\lambda=\sqrt{2 \log 2}$. Hence, the bias of $\tilde{\beta}{n}$ equals $\beta[\Phi(\lambda-\Delta)-\Phi(-\lambda-\Delta)]-[\phi(\lambda-\Delta)-\phi(\lambda+$ $\Delta)$, and the MSE is given by $$ \operatorname{MSE}\left(\hat{\beta}{n}^{\mathrm{PT}}\right)=\frac{\sigma^{2}}{Q} \rho_{\mathrm{PT}}(\lambda, \Delta) $$
统计代写|似然估计作业代写Probability and Estimation代考|Optimum Level of Significance of Preliminary Test
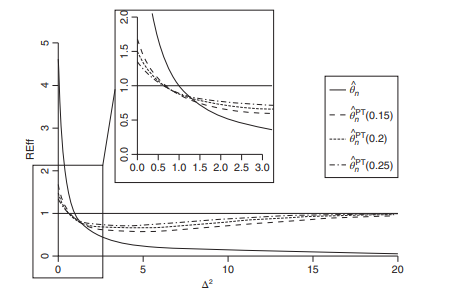
Consider the REff of $\hat{\theta}{n}^{\mathrm{pT}}(\alpha)$ compared to $\tilde{\theta}{n^{*}}$ Denoting it by REff $\left(\alpha ; \Delta^{2}\right)$, we have $$ \operatorname{REff}\left(\alpha, \Delta^{2}\right)=\left[1+g\left(\Delta^{2}\right)\right]^{-1}, $$ where $$ \begin{aligned} g\left(\Delta^{2}\right)=&-\frac{\bar{x}^{2}}{Q}\left(\frac{1}{n}+\frac{\bar{x}^{2}}{Q}\right)^{-1}\left[G_{3, m}\left(\frac{1}{3} F_{1, m}(\alpha) ; \Delta^{2}\right)\right.\ &\left.-\Delta^{2}\left{2 G_{3, m}\left(\frac{1}{3} F_{1, m}(\alpha) ; \Delta^{2}\right)-G_{5, m}\left(\frac{1}{5} F_{1, m}(\alpha) ; \Delta^{2}\right)\right}\right] \end{aligned} $$ The graph of REff $\left(\alpha, \Delta^{2}\right)$, as a function of $\Delta^{2}$ for fixed $\alpha$, is decreasing crossing the 1-line to a minimum at $\Delta^{2}=\Delta_{0}^{2}(\alpha)$ (say); then it increases toward the 1-line as $\Delta^{2} \rightarrow \infty$. The maximum value of $\operatorname{REff}\left(\alpha, \Delta^{2}\right)$ occurs at $\Delta^{2}=0$ with the value $$ \operatorname{REff}(\alpha ; 0)=\left{1-\frac{\bar{x}^{2}}{Q}\left(\frac{1}{n}+\frac{\bar{x}^{2}}{Q}\right)^{-1} G_{3, m}\left(\frac{1}{3} F_{1, m}(\alpha) ; 0\right)\right}^{-1} \geq 1, $$ for all $\alpha \in A$, the set of possible values of $\alpha$. The value of REff $(\alpha ; 0)$ decreases as $\alpha$-values increase. On the other hand, if $\alpha=0$ and $\Delta^{2}$ vary, the graphs of $\operatorname{REff}\left(0, \Delta^{2}\right)$ and $\operatorname{REff}\left(1, \Delta^{2}\right)$ intersect at $\Delta^{2}=1$. In general, $\operatorname{REff}\left(\alpha_{1}, \Delta^{2}\right)$ and $\operatorname{REff}\left(\alpha_{2}, \Delta^{2}\right)$ intersect within the interval $0 \leq \Delta^{2} \leq 1$; the value of $\Delta^{2}$ at the intersection increases as $\alpha$-values increase. Therefore, for two different $\alpha$-values, $\operatorname{REff}\left(\alpha_{1}, \Delta^{2}\right)$ and $\operatorname{REff}\left(\alpha_{2}, \Delta^{2}\right)$ will always intersect below the 1 -line. In order to obtain a PTE with a minimum guaranteed efficiency, $E_{0}$, we adopt the following procedure: If $0 \leq \Delta^{2} \leq 1$, we always choose $\tilde{\theta}{n}$, since $\operatorname{REff}\left(\alpha, \Delta^{2}\right) \geq 1$ in this interval. However, since in general $\Delta^{2}$ is unknown, there is no way to choose an estimate that is uniformly best. For this reason, we select an estimator with minimum guaranteed efficiency, such as $E{0}$, and look for a suitable $\alpha$ from the set, $A=\left{\alpha \mid \operatorname{REff}\left(\alpha, \Delta^{2}\right) \geq E_{0}\right}$. The estimator chosen
maximizes $\operatorname{REff}\left(\alpha, \Delta^{2}\right)$ over all $\alpha \in A$ and $\Delta^{2}$. Thus, we solve the following equation for the optimum $\alpha^{}$ : $$ \min {\Delta^{2}} \operatorname{REff}\left(\alpha, \Delta^{2}\right)=E\left(\alpha, \Delta{0}^{2}(\alpha)\right)=E_{0} . $$ The solution $\alpha^{}$ obtained this way gives the PTE with minimum guaranteed efficiency $E_{0}$, which may increase toward $\operatorname{REff}\left(\alpha^{*}, 0\right)$ given by $(2.61)$, and Table $2.2$. For the following given data, we have computed the maximum and minimum guaranteed REff for the estimators of $\theta$ and provided them in Table 2.2. $$ \begin{aligned} x=&(19.383,21.117,18.99,19.415,20.394,20.212,20.163,20.521,20.125,\ & 19.944,18.345,21.45,19.479,20.199,20.677,19.661,20.114,19.724 \ &18.225,20.669)^{\top} \end{aligned} $$
统计代写|似然估计作业代写Probability and Estimation代考|Comparison of Bias and MSE Functions
如果你也在 怎样代写似然估计Probability and Estimation这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
似然估计是一种统计方法,它用来求一个样本集的相关概率密度函数的参数。
statistics-lab™ 为您的留学生涯保驾护航 在代写似然估计Probability and Estimation方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写似然估计Probability and Estimation代写方面经验极为丰富,各种代写似然估计Probability and Estimation相关的作业也就用不着说。
我们提供的似然估计Probability and Estimation及其相关学科的代写,服务范围广, 其中包括但不限于:
Statistical Inference 统计推断
Statistical Computing 统计计算
Advanced Probability Theory 高等楖率论
Advanced Mathematical Statistics 高等数理统计学
(Generalized) Linear Models 广义线性模型
Statistical Machine Learning 统计机器学习
Longitudinal Data Analysis 纵向数据分析
Foundations of Data Science 数据科学基础
统计代写|似然估计作业代写Probability and Estimation代考|Simple Linear Model
统计代写|似然估计作业代写Probability and Estimation代考|Estimation of the Intercept and Slope Parameters
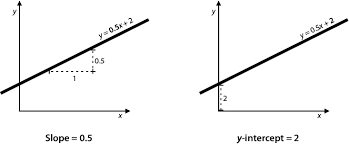
First, we consider the LSE of the parameters. Using the model $(2.1)$ and the sample information from the normal distribution, we obtain the LSEs of $(\theta, \beta)^{\top}$ as $$ \left(\begin{array}{c} \tilde{\theta}{n} \ \tilde{\beta}{n} \end{array}\right)=\left(\begin{array}{c} \bar{y}-\tilde{\beta}{n} \bar{x} \ \frac{1}{Q}\left[x^{\top} \boldsymbol{Y}-\frac{1}{n}\left(\mathbf{1}{n}^{\top} \boldsymbol{x}\right)\left(\mathbf{1}_{n}^{\top} \boldsymbol{Y}\right)\right] \end{array}\right) $$
where $$ \bar{x}=\frac{1}{n} \mathbf{1}{n}^{\top} \boldsymbol{x}, \quad \bar{y}=\frac{1}{n} \mathbf{1}{n}^{\top} Y, \quad Q=\boldsymbol{x}^{\top} \boldsymbol{x}-\frac{1}{n}\left(\mathbf{1}{n}^{\top} \boldsymbol{x}\right)^{2} . $$ The exact distribution of $\left(\tilde{\theta}{n}, \tilde{\beta}{n}\right)^{\top}$ is a bivariate normal with mean $(\theta, \beta)^{\top}$ and covariance matrix $$ \frac{\sigma^{2}}{n}\left(\begin{array}{cc} 1+\frac{n \bar{x}^{2}}{Q} & -\frac{n \bar{x}}{Q} \ \frac{n \bar{x}}{Q} & \frac{n}{Q} \end{array}\right) $$ An unbiased estimator of the variance $\sigma^{2}$ is given by $$ s{n}^{2}=(n-2)^{-1}\left(\boldsymbol{Y}-\tilde{\theta}{n} \mathbf{1}{n}-\tilde{\beta}{n} \boldsymbol{x}\right)^{\top}\left(\boldsymbol{Y}-\tilde{\theta}{n} \mathbf{1}{n}-\tilde{\beta}{n} \boldsymbol{x}\right), $$ which is independent of $\left(\tilde{\theta}{n}, \tilde{\beta}{n}\right)$, and $(n-2) s_{n}^{2} / \sigma^{2}$ follows a central chi-square distribution with ( $n-2$ ) degrees of freedom (DF)
统计代写|似然估计作业代写Probability and Estimation代考|Test for Slope Parameter
Suppose that we want to test the null-hypothesis $\mathcal{H}{0}: \beta=\beta{o}$ vs. $\mathcal{H}{A}: \beta \neq \beta{o}$. Then, we use the likelihood ratio (LR) test statistic $\mathcal{L}{n}^{(\sigma)}=\frac{\left(\tilde{\beta}{n}-\beta_{\mathrm{o}}\right)^{2} Q}{\sigma^{2}}, \quad$ if $\sigma^{2}$ is known $\mathcal{L}{n}^{(s)}=\frac{\left(\tilde{\beta}{n}-\beta_{\mathrm{o}}\right)^{2} Q}{s_{n}^{2}}, \quad$ if $\sigma^{2}$ is unknown where $\mathcal{L}{n}^{(\sigma)}$ follows a noncentral chi-square distribution with $1 \mathrm{DF}$ and noncentrality parameter $\Delta^{2} / 2$ and $\mathcal{L}{n}^{(s)}$ follows a noncentral $F$-distribution with $(1, m)$, where $m=n-2$ is DF and also the noncentral parameter is $$ \Delta^{2}=\frac{\left(\beta-\beta_{\mathrm{o}}\right)^{2} Q}{\sigma^{2}} $$ Under $\mathcal{H}{\mathrm{o}}, \mathcal{L}{n}^{(\sigma)}$ follows a central chi-square distribution and $\mathcal{L}{n}^{(s)}$ follows a central $F$-distribution. At the $\alpha$-level of significance, we obtain the critical value $\chi{1}^{2}(\alpha)$ or $F_{1, m}(\alpha)$ from the distribution and reject $\mathcal{H}{0}$ if $\mathcal{L}{n}^{(\sigma)}>\chi_{1}^{2}(\alpha)$ or $\mathcal{L}{n}^{(s)}>$ $F{1, n}(\alpha)$; otherwise, we accept $\mathcal{H}_{\mathrm{o}^{*}}$
统计代写|似然估计作业代写Probability and Estimation代考|PTE of the Intercept and Slope Parameters
This section deals with the problem of estimation of the intercept and slope parameters $(\theta, \beta)$ when it is suspected that the slope parameter $\beta$ may be $\beta_{o^{\circ}}$ From (2.30), we know that the LSE of $\theta$ is given by $$ \tilde{\theta}{n}=\bar{y}-\tilde{\beta}{n} \bar{x} . $$
If we know $\beta$ to be $\beta_{0}$ exactly, then the restricted least squares estimator (RLSE) of $\theta$ is given by $$ \hat{\theta}{n}=\bar{y}-\beta{\mathrm{o}} \bar{x} . $$ In practice, the prior information that $\beta=\beta_{\mathrm{o}}$ is uncertain. The doubt regarding this prior information can be removed using Fisher’s recipe of testing the null-hypothesis $\mathcal{H}{o}: \beta=\beta{o}$ against the alternative $\mathcal{H}{A}: \beta \neq \beta{o}$. As a result of this test, we choose $\tilde{\theta}{n}$ or $\hat{\theta}{n}$ based on the rejection or acceptance of $\mathcal{H}{\mathrm{a}}$. Accordingly, in case of the unknown variance, we write the estimator as $$ \hat{\theta}{n}^{\mathrm{PT}}(\alpha)=\hat{\theta}{n} I\left(\mathcal{L}{n}^{(s)} \leq F_{1, m}(\alpha)\right)+\tilde{\theta}{n} I\left(\mathcal{L}{n}^{(s)}>F_{1, m}(\alpha)\right), \quad m=n-2 $$ called the PTE, where $F_{1, n}(\alpha)$ is the $\alpha$-level upper critical value of a central $F$-distribution with $(1, m)$ DF and $I(A)$ is the indicator function of the set $A$. For more details on PTE, see Saleh (2006), Ahmed and Saleh (1988), Ahsanullah and Saleh (1972), Kibria and Saleh (2012) and, recently Saleh et al. (2014), among others. We can write PTE of $\theta$ as $$ \hat{\theta}{n}^{\mathrm{pT}}(\alpha)=\tilde{\theta}{n}+\left(\tilde{\beta}{n}-\beta{\mathrm{o}}\right) \bar{x} I\left(\mathcal{L}{n}^{(s)} \leq F{1, m}(\alpha)\right), \quad m=n-2 $$ If $\alpha=1, \tilde{\theta}{n}$ is always chosen; and if $\alpha=0, \hat{\theta}{n}$ is chosen. Since $0<\alpha<1$, $\hat{\theta}{n}^{\mathrm{pT}}(\alpha)$ in repeated samples, this will result in a combination of $\tilde{\theta}{n}$ and $\hat{\theta}{n}$. Note that the PTE procedure leads to the choice of one of the two values, namely, either $\dot{\theta}{n}$ or $\hat{\theta}_{n}$. Also, the PTE procedure depends on the level of significance $\alpha$.
Clearly, $\hat{\beta}{n}$ is the unrestricted estimator of $\beta$, while $\beta{\mathrm{o}}$ is the restricted estimator. Thus, the PTE of $\beta$ is given by $$ \hat{\beta}{n}^{P \mathrm{~T}}(\alpha)=\tilde{\beta}{n}-\left(\tilde{\beta}{a}-\beta{\mathrm{o}}\right) I\left(\mathcal{L}{n}^{(s)} \leq F{1, m}(\alpha)\right), \quad m=n-2 . $$ Now, if $\alpha=1, \tilde{\beta}{n}$ is always chosen; and if $\alpha=0, \beta{\mathrm{o}}$ is always chosen. Since our interest is to compare the LSE, RLSE, and PTE of $\theta$ and $\beta$ with respect to bias and the MSE, we obtain the expression of these quantities in the following theorem. First we consider the bias expressions of the estimators.
统计代写|似然估计作业代写Probability and Estimation代考|Simple Linear Model