统计代写|R语言代写R language代考|STA518
如果你也在 怎样代写R语言这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
R是一种用于统计计算和图形的编程语言,由R核心团队和R统计计算基金会支持。R由统计学家Ross Ihaka和Robert Gentleman创建,在数据挖掘者和统计学家中被用于数据分析和开发统计软件。用户已经创建了软件包来增强R语言的功能。
根据用户调查和对学术文献数据库的研究,R是数据挖掘中最常用的编程语言之一。[6] 截至2022年3月,R在衡量编程语言普及程度的TIOBE指数中排名第11位。
官方的R软件环境是GNU软件包中的一个开源自由软件环境,在GNU通用公共许可证下提供。它主要是用C、Fortran和R本身(部分自我托管)编写的。预编译的可执行文件提供给各种操作系统。R有一个命令行界面。[8] 也有多个第三方图形用户界面,如RStudio,一个集成开发环境,和Jupyter,一个笔记本界面。
statistics-lab™ 为您的留学生涯保驾护航 在代写R语言方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写R语言代写方面经验极为丰富,各种代写R语言相关的作业也就用不着说。
我们提供的R语言及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|R语言代写R language代考|R as a language
$\mathrm{R}$ is a computer language designed for data analysis and data visualization, however, in contrast to some other scripting languages, it is, from the point of view of computer programming, a complete language-it is not missing any important feature. In other words, no fundamental operations or data types are lacking (Chambers 2016). I attribute much of its success to the fact that its design achieves a very good balance between simplicity, clarity and generality. R excels at generality thanks to its extensibility at the cost of only a moderate loss of simplicity, while clarity is ensured by enforced documentation of extensions and support for both object-oriented and functional approaches to programming. The same three principles can be also easily respected by user code written in $\mathrm{R}$.
As mentioned above, R started as a free and open-source implementation of the S language (Becker and Chambers 1984; Becker et al. 1988). We will describe the features of the $\mathrm{R}$ language in later chapters. Here I mention, for those with programming experience, that it does have some features that make it different from other frequently used programming languages. For example, R does not have the strict type checks of Pascal or $\mathrm{C}++$. It has operators that can take vectors and matrices as operands allowing more concise program statements for such operations than other languages. Writing programs, specially reliable and fast code, requires familiarity with some of these idiosyncracies of the $\mathrm{R}$ language. For those using $\mathrm{R}$ interactively, or writing short scripts, these idiosyncratic features make life a lot easier by saving typing.
统计代写|R语言代写R language代考|R as a computer program
The R program itself is open-source, and the source code is available for anybody to inspect, modify and use. A small fraction of users will directly contribute improvements to the R program itself, but it is possible, and those contributions are important in making R reliable. The executable, the R program we actually use, can be built for different operating systems and computer hardware. The members of the R developing team make an important effort to keep the results obtained from calculations done on all the different builds and computer architectures as consistent as possible. The aim is to ensure that computations return consistent results not only across updates to $R$ but also across different operating systems like Linux, Unix (including OS X), and MS-Windows, and computer hardware.
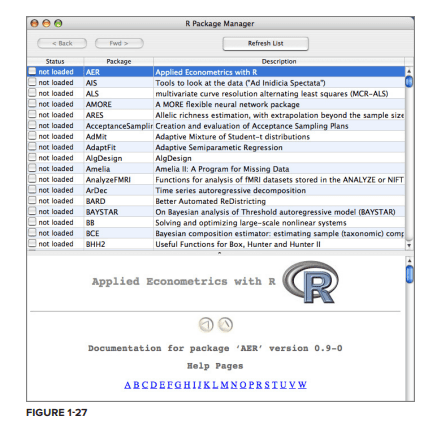
The $\mathrm{R}$ program does not have a graphical user interface (GUI), or menus from which to start different types of analyses. Instead, the user types the commands at the R console (Figure 1.1). The same textual commands can also be saved into a text file, line by line, and such a file, called a “script” can substitute repeated typing of the same sequence of commands. When we work at the console typing in commands one by one, we say that we use $\mathrm{R}$ interactively. When we run script, we may say that we run a “batch job.”
The two approaches described above are part of the R program by itself. However, it is common to use a second program as a front-end or middleman between the user and the R program. Such a program allows more flexibility and has multiple features that make entering commands or writing scripts easier. Computations are still done by exactly the same R program. The simplest option is to use a text editor like Emacs to edit the scripts and then run the scripts in R from within the editor. With some editors like Emacs, rather good integration is possible. However, nowadays there are also Integrated Development Environments (IDEs) available for R. An IDE both gives access to the R console in one window and provides a text editor for writing scripts in another window. Of the available IDEs for R, RStudio is currently the most popular by a wide margin.
R语言代写
统计代写|R语言代写R language代考|R as a language
R是一种专为数据分析和数据可视化而设计的计算机语言,然而,与其他一些脚本语言相比,从计算机编程的角度来看,它是一种完整的语言——它不缺少任何重要的特性。换句话说,不缺少基本操作或数据类型(Chambers 2016)。我将它的成功很大程度上归功于它的设计在简单性、清晰性和通用性之间取得了很好的平衡。R 在通用性方面表现出色,这要归功于它的可扩展性,其代价是仅在一定程度上降低了简单性,同时通过强制扩展文档和对面向对象和函数式编程方法的支持来确保清晰度。编写的用户代码也可以轻松遵守相同的三个原则R.
如上所述,R 最初是 S 语言的免费开源实现(Becker 和 Chambers 1984;Becker 等人 1988)。我们将描述的特点R后面章节的语言。在这里我提一下,对于那些有编程经验的人来说,它确实有一些特性使它不同于其他常用的编程语言。例如,R 没有 Pascal 或C++. 它具有可以将向量和矩阵作为操作数的运算符,允许比其他语言更简洁的程序语句来进行此类操作。编写程序,特别是可靠和快速的代码,需要熟悉一些这些特性R语。对于那些使用R交互式地,或编写简短的脚本,这些特殊的功能通过节省打字让生活变得更轻松。
统计代写|R语言代写R language代考|R as a computer program
R程序本身是开源的,任何人都可以查看、修改和使用源代码。一小部分用户将直接为 R 程序本身做出改进,但这是可能的,并且这些贡献对于使 R 可靠非常重要。可执行文件,即我们实际使用的 R 程序,可以针对不同的操作系统和计算机硬件构建。R 开发团队的成员做出了重要的努力,以使在所有不同构建和计算机体系结构上进行的计算所获得的结果尽可能保持一致。目的是确保计算不仅在更新之间返回一致的结果R但也跨越不同的操作系统,如 Linux、Unix(包括 OS X)和 MS-Windows,以及计算机硬件。
这R程序没有图形用户界面 (GUI),也没有启动不同类型分析的菜单。相反,用户在 R 控制台键入命令(图 1.1)。同样的文本命令也可以逐行保存到一个文本文件中,这样一个称为“脚本”的文件可以代替重复键入相同的命令序列。当我们在控制台上一个接一个地输入命令时,我们说我们使用R交互地。当我们运行脚本时,我们可能会说我们运行了一个“批处理作业”。
上述两种方法本身就是 R 程序的一部分。但是,通常使用第二个程序作为用户和 R 程序之间的前端或中间人。这样的程序允许更大的灵活性,并具有使输入命令或编写脚本更容易的多种功能。计算仍然由完全相同的 R 程序完成。最简单的选择是使用像 Emacs 这样的文本编辑器来编辑脚本,然后从编辑器中运行 R 中的脚本。对于一些像 Emacs 这样的编辑器,相当好的集成是可能的。然而,如今也有可用于 R 的集成开发环境 (IDE)。IDE 既可以在一个窗口中访问 R 控制台,又可以提供文本编辑器以在另一个窗口中编写脚本。在适用于 R 的可用 IDE 中,RStudio 目前是最受欢迎的,遥遥领先。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
随机过程代考
在概率论概念中,随机过程是随机变量的集合。 若一随机系统的样本点是随机函数,则称此函数为样本函数,这一随机系统全部样本函数的集合是一个随机过程。 实际应用中,样本函数的一般定义在时间域或者空间域。 随机过程的实例如股票和汇率的波动、语音信号、视频信号、体温的变化,随机运动如布朗运动、随机徘徊等等。
贝叶斯方法代考
贝叶斯统计概念及数据分析表示使用概率陈述回答有关未知参数的研究问题以及统计范式。后验分布包括关于参数的先验分布,和基于观测数据提供关于参数的信息似然模型。根据选择的先验分布和似然模型,后验分布可以解析或近似,例如,马尔科夫链蒙特卡罗 (MCMC) 方法之一。贝叶斯统计概念及数据分析使用后验分布来形成模型参数的各种摘要,包括点估计,如后验平均值、中位数、百分位数和称为可信区间的区间估计。此外,所有关于模型参数的统计检验都可以表示为基于估计后验分布的概率报表。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
statistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
机器学习代写
随着AI的大潮到来,Machine Learning逐渐成为一个新的学习热点。同时与传统CS相比,Machine Learning在其他领域也有着广泛的应用,因此这门学科成为不仅折磨CS专业同学的“小恶魔”,也是折磨生物、化学、统计等其他学科留学生的“大魔王”。学习Machine learning的一大绊脚石在于使用语言众多,跨学科范围广,所以学习起来尤其困难。但是不管你在学习Machine Learning时遇到任何难题,StudyGate专业导师团队都能为你轻松解决。
多元统计分析代考
基础数据: $N$ 个样本, $P$ 个变量数的单样本,组成的横列的数据表
变量定性: 分类和顺序;变量定量:数值
数学公式的角度分为: 因变量与自变量
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。