统计代写|贝叶斯分析代写Bayesian Analysis代考|STAT4102
如果你也在 怎样代写贝叶斯分析Bayesian Analysis这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
贝叶斯分析,一种统计推断方法(以英国数学家托马斯-贝叶斯命名),允许人们将关于人口参数的先验信息与样本所含信息的证据相结合,以指导统计推断过程。
statistics-lab™ 为您的留学生涯保驾护航 在代写贝叶斯分析Bayesian Analysis方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写贝叶斯分析Bayesian Analysis代写方面经验极为丰富,各种代写贝叶斯分析Bayesian Analysis相关的作业也就用不着说。
我们提供的贝叶斯分析Bayesian Analysis及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|贝叶斯分析代写Bayesian Analysis代考|Drug Testing
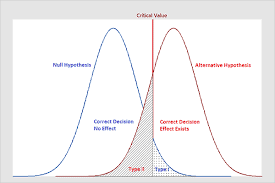
Here we dig deeper into the example (taken from Ziliak and McCloskey, 2008) first introduced in Chapter 2, Box 2.1. We are interested in comparing two weight-loss drugs to determine which should be sold. Experimental data on the drugs Oomph and Precision have shown that, over a one-month period for a number of test subjects:
- Weight loss for Precision is approximately Normally distributed with mean 5 pounds and variance 1 . So we define the NPT for the node Precision as a Normal $(5,1)$ distribution.
- Oomph showed a much higher average weight loss of 20 pounds but with much more variation and is estimated as a Normal $(20,100)$ distribution.
We might be interested in two things here: one is predictability of the effect of a drug on weight loss and the other is the size or impact of the drug on weight loss. Let’s adopt a similar formulation to before:
$$
\begin{gathered}
H_0: \text { Precision }>\text { Oomph } \
H_1: \text { Oomph } \geq \text { Precision }
\end{gathered}
$$
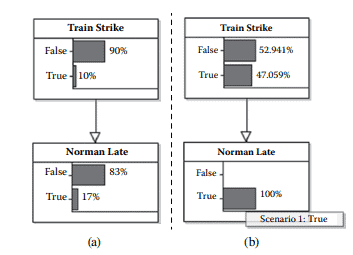
Figure 12.10 shows the AgenaRisk model used to test this hypothesis. Rather than create a node for the difference, Precision-Oomph, directly in AgenaRisk we have simply declared a single expression for the hypothesis node as
if (Precision > Oomph, “Precision”, “Oomph”)
rather than use two separate nodes as we did in the quality assurance example.
Notice that the hypothesis is approximately $93 \%$ in favor of Oomph over Precision, since only $7 \%$ of the time is Precision likely to result in more weight loss than Oomph. Interestingly we have included here two additional nodes to cover the risk that any of the drugs actually cause negative weight loss, that is, weight gain for the good reason that some may be fearful of putting on weight and might choose the drug that was less effective but also less risky. In this case someone might choose Precision since Oomph has a $2.28 \%$ chance of weight gain, where the chance of weight gain with Precision is negligible.
In the classical statistical approach to hypothesis testing in the drug testing example we would be interested in assessing the statistical significance of each drug with respect to its capability to reduce weight, that is, whether any weight reduction is likely to have occurred by chance. In doing this we compare the results for each drug against the null hypothesis: zero weight loss. So, for both Precision and Oomph we test the following hypotheses, where $\mu$ is the population mean weight loss in each case:
$$
\begin{aligned}
& H_0: \mu_0=0 \
& H_1: \mu_1>0
\end{aligned}
$$
Box 12.2 describes the classical statistical approach to testing this hypothesis in each case (i.e. the approach introduced in Section 12.2.1).
统计代写|贝叶斯分析代写Bayesian Analysis代考|Considering Difference between Distributions Rather Than Difference between Means
Consider the following problem scenario:
A new drug is trialled which is believed to increase survival time of patients with a particular disease. It is a comprehensive randomised control trial lasting 36 months in which 1000 patients with the disease take the drug and 1000 with the disease do not take the drug. The trial results show that the null hypothesis of “no increase in survival time” can be rejected with high confidence; specifically, there is greater than $99 \%$ chance that the mean survival time of people taking the drug is higher than those who do not. You are diagnosed with the disease. Should you take the drug and, if so, what are your chances of surviving longer if you do?
As in the previous problems we are comparing two attributes-the survival time with the drug and the survival time without the drug. Unfortunately, the $99 \%$ probability that the mean of the former is greater than the mean of the latter tells us nothing about the probability that any given person will survive longer if they take the drug. So, it does not help us to answer the question. The problem is that if we have reasonable size samples-as in this case-there will actually be very little uncertainty about the mean. All the “interesting” uncertainty is about the variance. As an extreme example suppose you could measure the height of every adult male in the United Kingdom. Then, despite wide variance in the results, the mean height will be an exact figure, say $176 \mathrm{~cm}$. Even if you were only able to take a sample of, say 100 , the mean of the sample would be a very accurate estimate of the true mean of 176 (i.e. with very little uncertainty). So, in the drug example, if the mean survival time of the 1000 patients taking the drug is 28.5 weeks, then this will be very close to the true, but unknown, survival time with little uncertainty. Yet the mean survival time will inevitably “hide” the fact that many of the patients survive the full 36 weeks while many die within the first 3 weeks.
Suppose that, based on the trial data, we get the following estimates for the mean and variance of the survival times:
Then we can construct the necessary $\mathrm{BN}$ model as shown in Figure 12.11.
The nodes with the estimated means and variances of the survival times are defined using the Normal distributions in the above table. Each of the “true” survival time nodes is defined simply as a Normal distribution with mean equal to the (parent) estimated mean and variance equal to the (parent) estimated variance. The Boolean node “Mean survival time no greater with drug” has its NPT defined as
if(mean_with > mean_without, ‘False’, ‘True’)
The Boolean node “survive no longer with drug” has its NPT defined as
if(with > without, ‘False’, ‘True’)
Note that the null hypothesis “Mean survival time no greater with drug” is easily rejected at the $1 \%$ level, and so the drug would certainly be accepted and recommended for patients with the disease. However, the situation for the null hypothesis “survive no longer with drug” is very different. There is actually a $47.45 \%$ chance that your survival time will be less if you take the drug than if you do not.
贝叶斯分析代考
统计代写|贝叶斯分析代写Bayesian Analysis代考|Drug Testing
在这里,我们深入研究第 2 章专栏 2.1 中首次介绍的示例(取自 Ziliak 和 McCloskey,2008 年)。我 们有兴趣比较两种减肥药,以确定应该出售哪种。药物 Oomph 和 Precision 的实验数据表明,在一个 月的时间里,许多测试对象:
- Precision 的体重减轻近似正态分布,均值为 5 磅,方差为 1 。所以我们将节点 Precision 的 NPT 定义为 $\operatorname{Normal}(5,1)$ 分配。
- Oomph 表现出更高的平均体重减轻 20 磅,但变化更大,估计为正常 $(20,100)$ 分配。 我们可能对这里的两件事感兴趣:一是药物对减肥效果的可预测性,二是药物对减肥的大小或影 响。让我们采用与之前类似的公式:
$$
H_0: \text { Precision }>\text { Oomph } H_1: \text { Oomph } \geq \text { Precision }
$$
图 12.10 显示了用于检验该假设的 AgenaRisk 模型。我们没有直接在 AgenaRisk 中为差值 Precision-Oomph 创建一个节点,而是简单地为假设节点声明了一个表达式,就像 (Precision > Oomph, “Precision”, “Oomph”) 而不是像我们一样使用两个单独的节点在质量保证示例中做了。
请注意,假设大约是 $93 \%$ 赞成 Oomph 而不是 Precision,因为只有 $7 \%$ 与 Oomph 相比,Precision 可 能会导致更多的体重减轻。有趣的是,我们在这里包括了两个额外的节点,以涵盖任何药物实际导致负 体重减轻的风险,即体重增加的充分理由是一些人可能害怕增加体重并可能选择效果较差的药物而且风 险也较小。在这种情况下,有人可能会选择 Precision,因为 Oomph 有 $2.28 \%$ 体重增加的机会,其中 Precision 增加体重的机会可以忽略不计。
在药物测试示例中假设检验的经典统计方法中,我们有兴趣评估每种药物在其减肥能力方面的统计显着 性,即任何体重减轻是否可能是偶然发生的。在这样做时,我们将每种药物的结果与零假设进行比较: 体重减轻为零。因此,对于 Precision 和 Oomph,我们检验以下假设,其中 $\mu$ 是每种情况下的总体平均 体重减轻:
$$
H_0: \mu_0=0 \quad H_1: \mu_1>0
$$
专栏 12.2 描述了在每种情况下检验该假设的经典统计方法 (即第 12.2 .1 节中介绍的方法)。
统计代写|贝叶斯分析代写Bayesian Analysis代考|Considering Difference between Distributions Rather Than Difference between Means
考虑以下问题场景:
正在试用一种新药,据信它可以延长患有特定疾病的患者的生存时间。这是一项持续 36 个月的综合随机对照试验,其中 1000 名患有该疾病的患者服用该药物,1000 名患有该疾病的患者未服用该药物。试验结果表明,可以高置信度地拒绝“生存时间没有增加”的原假设;具体来说,有大于99%服用该药物的人的平均生存时间高于未服用药物的人的可能性。你被诊断出患有这种疾病。你应该服用这种药物吗?如果服用的话,你活得更久的机会有多大?
与前面的问题一样,我们正在比较两个属性——使用药物的生存时间和不使用药物的生存时间。不幸的是,99%前者的均值大于后者的均值的概率并没有告诉我们任何给定的人服用该药后活得更久的概率。所以,这并不能帮助我们回答这个问题。问题是,如果我们有合理大小的样本——就像在这种情况下——实际上平均值的不确定性很小。所有“有趣”的不确定性都与方差有关。举一个极端的例子,假设您可以测量英国每个成年男性的身高。然后,尽管结果差异很大,但平均身高将是一个精确的数字,比如176 C米. 即使您只能抽取 100 个样本,样本的均值也将是对 176 的真实均值的非常准确的估计(即不确定性很小)。因此,在药物示例中,如果服用该药物的 1000 名患者的平均生存时间为 28.5 周,那么这将非常接近真实但未知的生存时间,几乎没有不确定性。然而,平均生存时间将不可避免地“掩盖”一个事实,即许多患者存活了整整 36 周,而许多患者在前 3 周内死亡。
假设,根据试验数据,我们得到以下生存时间均值和方差的估计值:
然后我们可以构建必要的乙否模型如图 12.11 所示。
使用上表中的正态分布定义具有估计生存时间均值和方差的节点。每个“真实”生存时间节点都被简单地定义为均值等于(父)估计均值且方差等于(父)估计方差的正态分布。布尔节点“使用药物后平均生存时间不再延长”将其 NPT 定义为
if(mean_with > mean_without, ‘False’, ‘True’)
布尔节点“不再使用药物生存”将其 NPT 定义为
if(with > without, ‘False’, ‘True’)
请注意零假设“平均生存时间不超过药物”很容易被拒绝1%水平,因此该药物肯定会被接受并推荐给患有这种疾病的患者。然而,零假设“不再靠药物生存”的情况就大不相同了。实际上有一个47.45%如果您服药,您的生存时间可能会比您不服药时短。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。