数学代写|复分析作业代写Complex function代考|KMA152
如果你也在 怎样代写复分析Complex function这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
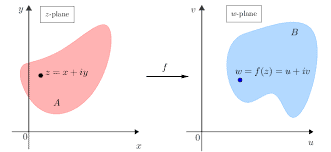
复分析是一个从复数到复数的函数。换句话说,它是一个以复数的一个子集为域,以复数为子域的函数。复数函数通常应该有一个包含复数平面的非空开放子集的域。
statistics-lab™ 为您的留学生涯保驾护航 在代写复分析Complex function方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写复分析Complex function代写方面经验极为丰富,各种代写复分析Complex function相关的作业也就用不着说。
我们提供的复分析Complex function及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础

数学代写|复分析作业代写Complex function代考|Cassinian Curves
Consider [2.8a]. The ends of a piece of string of length $l$ are attached to two fixed points $a_1$ and $a_2$ in $\mathbb{C}$, and, with its tip at $z$, a pencil holds the string taut. The figure illustrates the well known fact that if we move the pencil (continuing to keep the string taut) it traces out an ellipse, with foci $a_1$ and $a_2$. Writing $r_{1,2}=\left|z-a_{1,2}\right|$, the equation of the ellipse is thus
$$
r_1+r_2=l
$$
By choosing different values of $l$ we obtain the illustrated family of confocal ellipses.
In 1687 Newton published his great Principia, in which he demonstrated that the planets orbit in such ellipses, with the sun at one of the foci. Seven years earlier, however, Giovanni Cassini had instead proposed that the orbits were curves for which the product of the distances is constant:
$$
r_1 \cdot r_2=\text { const. }=k^2
$$
These curves are illustrated in $[2.8 \mathrm{~b}]$; they are called Cassinian curves, and the points $a_1$ and $a_2$ are again called foci.
The following facts will become clearer in a moment, but you might like to think about them for yourself. If $k$ is small then the curve consists of two separate pieces, resembling small circles centred at $a_1$ and $a_2$. As $k$ increases, these two components of the curve become more egg shaped. When $k$ reaches a value equal to half the distance between the foci then the pointed ends of the egg shapes meet at the midpoint of the foci, producing a figure eight [shown solid]. Increasing the value of $k$ still further, the curve first resembles an hourglass, then an ellipse, and finally a circle.
Although Cassinian curves turned out to be useless as a description of planetary motion, the figure eight curve proved extremely valuable in quite another context. In 1694 it was rediscovered by James Bernoulli and christened the lemniscate-it then became the catalyst in unravelling the behaviour of the so-called elliptic integrals and elliptic functions. See Stillwell (2010) and Siegel (1969) for more on this fascinating story.
数学代写|复分析作业代写Complex function代考|The Mystery of Real Power Series
Many real functions $F(x)$ can be expressed (e.g., via Taylor’s Theorem) as power series:
$$
F(x)=\sum_{j=0}^{\infty} c_j x^j=c_0+c_1 x+c_2 x^2+c_3 x^3+\cdots,
$$
where the $c_j$ ‘s are real constants. Of course, this infinite series will normally only converge to $F(x)$ in some origin-centred interval of convergence $-R<x<R$. But how is $R$ (the radius of convergence) determined by $F(x)$ ?
It turns out that this question has a beautifully simple answer, but only if we investigate it in the complex plane. If we instead restrict ourselves to the real line-as mathematicians were forced to in the era in which such series were first employed – then the relationship between $R$ and $F(x)$ is utterly mysterious. Historically, it was precisely this mystery ${ }^1$ that led Cauchy to several of his breakthroughs in complex analysis.
To see that there is a mystery, consider the power series representations of the functions
$$
\mathrm{G}(\mathrm{x})=\frac{1}{1-x^2} \quad \text { and } \quad \mathrm{H}(x)=\frac{1}{1+x^2}
$$
The familiar infinite geometric series,
$$
\frac{1}{1-x}=\sum_{j=0}^{\infty} x^j=1+x+x^2+x^3+\cdots \quad \text { if and only if }-1<x<1
$$
immediately yields
$$
G(x)=\sum_{j=0}^{\infty} \chi^{2 j} \quad \text { and } \quad H(x)=\sum_{j=0}^{\infty}(-1)^j \chi^{2 j}
$$
where both series have the same interval of convergence, $-1<x<1$.
It is easy to understand the interval of convergence of the series for $G(x)$ if we look at the graph [2.12a]. The series becomes divergent at $x= \pm 1$ because these points are singularities of the function itself, i.e., they are places where $|\mathrm{G}(\mathrm{x})|$ becomes infinite. But if we look at $y=|\mathrm{H}(\mathrm{x})|$ in $[2.12 \mathrm{~b}]$, there seems to be no reason for the series to break down at $x= \pm 1$. Yet break down it does.

复分析代写
数学代写|复分析作业代写Complex function代考|Cassinian Curves
拉紧了绳子。该图说明了一个众所周知的事实,即如果我们移动铅笔(继续保持绳子绷坚),它会描绘 出一个椭圆,焦点为 $a_1$ 和 $a_2$. 写作 $r_{1,2}=\left|z-a_{1,2}\right|$ ,椭圆的方程因此是
$$
r_1+r_2=l
$$
通过选择不同的值我们得到了图示的共焦椭圆族。
1687 年,牛顿出版了他伟大的《原理》,其中他证明了行星以这样的椭圆轨道运行,其中一个焦点是太 阳。然而,七年前,乔瓦尼卡西尼 (Giovanni Cassini) 提出轨道是距离乘积恒定的曲线:
$$
r_1 \cdot r_2=\text { const. }=k^2
$$
这些曲线示于 $[2.8 \mathrm{~b}]$; 它们被称为卡西尼曲线,点 $a_1$ 和 $a_2$ 再次被称为焦点。
以下事实稍后会变得更加清晰,但您可能㹷望自己考虑一下。如果 $k$ 很小,那么曲线由两个独立的部分 组成,类似于以为中心的小圆圈 $a_1$ 和 $a_2$. 作为 $k$ 增加,曲线的这两个分量变得更蛋形。什么时候 $k$ 达到等 于焦点之间距离的一半的值,然后蛋形的尖端在焦点的中点相遇,产生数字 8 [显示为实线]。增加的价 值 $k$ 更进一步,曲线先像沙漏,然后像椭圆,最后像圆。
尽管事实证明卡西尼曲线在描述行星运动时毫无用处,但在完全不同的情况下,8 字形曲线被证明是极 其有价值的。1694 年,詹姆斯·伯努利 (James Bernoulli) 重新发现了它,并将其命名为双纽线一一它随 后成为揭示所谓椭圆积分和椭圆函数行为的催化剂。有关这个引人入胜的故事的更多信息,请参阅 Stillwell (2010) 和 Siegel (1969)。
数学代写|复分析作业代写Complex function代考|The Mystery of Real Power Series
许多真实的功能 $F(x)$ 可以表示 (例如,通过泰勒定理) 为幂级数:
$$
F(x)=\sum_{j=0}^{\infty} c_j x^j=c_0+c_1 x+c_2 x^2+c_3 x^3+\cdots
$$
在哪里 $c_j$ 是实常数。当然,这个无穷级数通常只会收敛到 $F(x)$ 在一些以原点为中心的收敛区间 $-R<x<R$. 但是怎么样 $R$ (收敛半径) 由 $F(x)$ ?
事实证明,这个问题有一个非常简单的答案,但前提是我们在复平面上进行调查。如果我们改为将自己 限制在实线一一就像数学家在首次使用此类级数的时代被迫这样做的那样一一那么两者之间的关系 $R$ 和 $F(x)$ 是完全神秘的。历史上,正是这个谜团 ${ }^1$ 这导致柯西在复数分析中取得了多项突破。
要看出其中的血秘,请考虑函数的幂级数表示
$$
\mathrm{G}(\mathrm{x})=\frac{1}{1-x^2} \quad \text { and } \quad \mathrm{H}(x)=\frac{1}{1+x^2}
$$
熟手的无限几何级数,
$$
\frac{1}{1-x}=\sum_{j=0}^{\infty} x^j=1+x+x^2+x^3+\cdots \quad \text { if and only if }-1<x<1
$$
立即产生
$$
G(x)=\sum_{j=0}^{\infty} \chi^{2 j} \quad \text { and } \quad H(x)=\sum_{j=0}^{\infty}(-1)^j \chi^{2 j}
$$
其中两个系列具有相同的收敛区间, $-1<x<1$.
很容易理解级数的收敛区间为 $G(x)$ 如果我们看一下图 [2.12a]。该系列在 $x= \pm 1$ 因为这些点是函数本 身的奇点,即它们是 $|\mathrm{G}(\mathrm{x})|$ 变得无穷大。但是如果我们看 $y=|\mathrm{H}(\mathrm{x})|$ 在 $[2.12 \mathrm{~b}]$, 该系列似乎没有理由 在 $x= \pm 1$. 然而分解它确实如此。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。