如果你也在 怎样代写机器学习Machine Learning这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
机器学习是人工智能(AI)和计算机科学的一个分支,主要是利用数据和算法来模仿人类的学习方式,逐步提高其准确性。
机器学习是不断增长的数据科学领域的一个重要组成部分。通过使用统计方法,算法被训练来进行分类或预测,在数据挖掘项目中发现关键的洞察力。这些洞察力随后推动了应用程序和业务的决策,最好是影响关键的增长指标。随着大数据的不断扩大和增长,市场对数据科学家的需求将增加,需要他们协助确定最相关的业务问题,随后提供数据来回答这些问题。
statistics-lab™ 为您的留学生涯保驾护航 在代写机器学习Machine Learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写机器学习方面经验极为丰富,各种代写机器学习Machine Learning相关的作业也就用不着说。
我们提供的机器学习Machine Learning及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|机器学习作业代写Machine Learning代考|Data mining
Data mining (DM) is defined as the process of discovering patterns in data [40]. There is no clear distinction in literature between data mining and machine learning. In some publications, data mining focuses on extracting data patterns and finding relationships between data [10], whereas machine learning focuses on making predictions [36]. Data mining is the process of discovering useful patterns and trends in large data sets. Predictive analytics is the process of extracting information from large data sets in order to make predictions and estimates about future outcomes [17]. Therefore the distinction is in the aim. Data mining aims to interpret data, to find patterns that can explain some phenomenon. Machine learning on the other hand, aims to make predictions by building models that can foresee some future outcome. However, clustering is a machine learning technique that aims to understand the underlying structure of the data and has similar goals to data mining. Here, we treat machine learning as a subarea of data mining where the rules are learned automatically.
Humans learn from experience, machines learn from data. Data is the starting point for all machine learning projects. Machine learning techniques learn the rules from historic data in order to create an inner representation, an abstraction, that is often difficult to interpret. Programming computers to learn from experience should eventually eliminate the need for much of this detailed programming effort [35].
统计代写|机器学习作业代写Machine Learning代考|Data mining steps
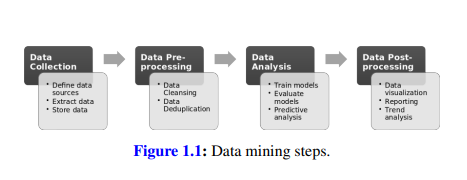
A typical data mining workflow goes through several steps. These steps include data collection, cleansing, transformation, aggregation, modeling, predictive analysis, visualization and dissemination. However, depending on the problem at hand, those steps might vary or additional steps might be necessary. Data mining requires domain specific knowledge. If a data mining project is supposed to detect fraud and money laundering in financial transactions or group news articles into categories such as “Politics”, “Business”, “Science” etc., different techniques apply. Getting familiar with the domain of the application and setting the goals of the data mining project are necessary preliminary tasks in order for the data mining project to complete successfully. Domain knowledge is also necessary to evaluate the performance of a trained learner. Figure $1.1$ summarizes the data mining steps.Data mining is a highly iterative process and typically goes through many iterations until satisfactory results are achieved. Data mining projects have to be executed with great care. The growth of data in the past years has fostered the development of new data mining applications where the internal workings often go undocumented. The blackbox approach is dangerous since the results can be difficult to explain, or lead to erroneous conclusions. For instance, cancer tissue in medical images that was undetected or a traffic situation that was misinterpreted by an autonomously driving car. The ease with which these applications can manipulate data, combined with the power of the formidable data mining algorithms embedded in the black-box software, make their misuse proportionally more hazardous [17]. Ultimately, one canfind anything in data and if a machine learning project is carried out without proficiency it can lead to expensive failures.
统计代写|机器学习作业代写Machine Learning代考|Data collection
Data collection is the process of tapping into data sources and extracting the data needed for training and testing a model. Data sources include databases, data warehouses, transaction data, the Internet, sensor data from the Internet of Things or streaming data, but many more sources exist. If the data is stored in its original format, it is called a data lake. The data can be historic or real-time, streaming data. For instance, training a model for spam filtering needs historic, labeled legitimate and spam mails for training and testing. Spam mails are artfully crafted in order to avoid elimination by spam filters, making spam filtering a tricky task. Spam filtering is one of the most widely-used applications of machine learning.
Often there is more than one data source and multiple data sources need to be combined, a process called data integration. As a general technology, data mining can be applied to any kind of data as long as the data are meaningful for a target application [10].
It is often difficult to collect enough training data. Data is sometimes not publicly available or cannot be accessed for privacy or security reasons. To mitigate the problem of sparse data sets, synthetic data can be created, or training techniques such as cross-validation can be applied. Also, to train a learner, labeled data is needed. Raw data, such as emails, are not labeled, and producing labeled training sets can be a laborious task. Semi-supervised techniques such as active learning can be used in these situations. Active learning is a form of online learning in which the agent acts to acquire useful examples from which to learn [31]. In offline learning, all training data is available beforehand, whereas in online learning the training data arrive while the learner is trained. The learning algorithm can actively ask the agent to label data while it arrives. Data availability, whether labeled or not, is crucial for the success of a machine learning project and should be clarified before a machine learning project is initiated.
机器学习代写
统计代写|机器学习作业代写Machine Learning代考|Data mining
数据挖掘(DM)被定义为发现数据模式的过程[40]。文献中数据挖掘和机器学习之间没有明确的区别。在一些出版物中,数据挖掘侧重于提取数据模式和发现数据之间的关系 [10],而机器学习侧重于进行预测 [36]。数据挖掘是在大型数据集中发现有用模式和趋势的过程。预测分析是从大型数据集中提取信息以对未来结果进行预测和估计的过程 [17]。因此,区别在于目标。数据挖掘旨在解释数据,找到可以解释某些现象的模式。另一方面,机器学习旨在通过构建可以预见未来结果的模型来进行预测。然而,聚类是一种机器学习技术,旨在了解数据的底层结构,其目标与数据挖掘相似。在这里,我们将机器学习视为数据挖掘的一个子领域,其中规则是自动学习的。
人类从经验中学习,机器从数据中学习。数据是所有机器学习项目的起点。机器学习技术从历史数据中学习规则,以创建通常难以解释的内部表示、抽象。对计算机进行编程以从经验中学习最终应该消除对这种详细编程工作的大部分需求[35]。
统计代写|机器学习作业代写Machine Learning代考|Data mining steps
典型的数据挖掘工作流程要经过几个步骤。这些步骤包括数据收集、清理、转换、聚合、建模、预测分析、可视化和传播。但是,根据手头的问题,这些步骤可能会有所不同,或者可能需要额外的步骤。数据挖掘需要特定领域的知识。如果数据挖掘项目要检测金融交易中的欺诈和洗钱行为,或者将新闻文章归类为“政治”、“商业”、“科学”等类别,则需要使用不同的技术。熟悉应用领域并设定数据挖掘项目的目标是数据挖掘项目成功完成的必要前期任务。领域知识对于评估训练有素的学习者的表现也是必要的。数字1.1总结了数据挖掘的步骤。数据挖掘是一个高度迭代的过程,通常要经过多次迭代,直到获得满意的结果。必须非常小心地执行数据挖掘项目。过去几年数据的增长促进了新数据挖掘应用程序的开发,其中内部工作经常没有记录。黑盒方法是危险的,因为结果可能难以解释,或导致错误的结论。例如,医学图像中未被检测到的癌组织或被自动驾驶汽车误解的交通状况。这些应用程序可以轻松地操作数据,再加上嵌入在黑盒软件中的强大数据挖掘算法的力量,使得它们的滥用成比例地更加危险[17]。最终,
统计代写|机器学习作业代写Machine Learning代考|Data collection
数据收集是利用数据源并提取训练和测试模型所需数据的过程。数据源包括数据库、数据仓库、交易数据、互联网、来自物联网的传感器数据或流数据,但还有更多来源。如果数据以其原始格式存储,则称为数据湖。数据可以是历史的或实时的流数据。例如,训练垃圾邮件过滤模型需要历史的、标记的合法邮件和垃圾邮件进行训练和测试。垃圾邮件经过精心设计,以避免被垃圾邮件过滤器消除,从而使垃圾邮件过滤成为一项棘手的任务。垃圾邮件过滤是机器学习最广泛使用的应用之一。
通常有多个数据源,并且需要组合多个数据源,这一过程称为数据集成。作为一种通用技术,数据挖掘可以应用于任何类型的数据,只要数据对目标应用有意义[10]。
通常很难收集到足够的训练数据。数据有时不公开或出于隐私或安全原因无法访问。为了缓解稀疏数据集的问题,可以创建合成数据,或者可以应用交叉验证等训练技术。此外,为了训练学习者,需要标记数据。原始数据(例如电子邮件)没有标记,生成标记的训练集可能是一项艰巨的任务。在这些情况下可以使用半监督技术,例如主动学习。主动学习是在线学习的一种形式,其中代理采取行动获取有用的示例以供学习[31]。在离线学习中,所有训练数据都是预先可用的,而在在线学习中,训练数据在学习者接受训练时到达。学习算法可以主动要求代理在数据到达时对其进行标记。数据可用性,无论是否标记,对于机器学习项目的成功至关重要,应该在启动机器学习项目之前进行澄清。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。统计代写|python代写代考
随机过程代考
在概率论概念中,随机过程是随机变量的集合。 若一随机系统的样本点是随机函数,则称此函数为样本函数,这一随机系统全部样本函数的集合是一个随机过程。 实际应用中,样本函数的一般定义在时间域或者空间域。 随机过程的实例如股票和汇率的波动、语音信号、视频信号、体温的变化,随机运动如布朗运动、随机徘徊等等。
贝叶斯方法代考
贝叶斯统计概念及数据分析表示使用概率陈述回答有关未知参数的研究问题以及统计范式。后验分布包括关于参数的先验分布,和基于观测数据提供关于参数的信息似然模型。根据选择的先验分布和似然模型,后验分布可以解析或近似,例如,马尔科夫链蒙特卡罗 (MCMC) 方法之一。贝叶斯统计概念及数据分析使用后验分布来形成模型参数的各种摘要,包括点估计,如后验平均值、中位数、百分位数和称为可信区间的区间估计。此外,所有关于模型参数的统计检验都可以表示为基于估计后验分布的概率报表。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
statistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
机器学习代写
随着AI的大潮到来,Machine Learning逐渐成为一个新的学习热点。同时与传统CS相比,Machine Learning在其他领域也有着广泛的应用,因此这门学科成为不仅折磨CS专业同学的“小恶魔”,也是折磨生物、化学、统计等其他学科留学生的“大魔王”。学习Machine learning的一大绊脚石在于使用语言众多,跨学科范围广,所以学习起来尤其困难。但是不管你在学习Machine Learning时遇到任何难题,StudyGate专业导师团队都能为你轻松解决。
多元统计分析代考
基础数据: $N$ 个样本, $P$ 个变量数的单样本,组成的横列的数据表
变量定性: 分类和顺序;变量定量:数值
数学公式的角度分为: 因变量与自变量
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。